Last Wednesday, September 17th, we’ve done the first RAC Attack in Switzerland (as far as I know!). I have to say that it has been a complete success like all other RAC Attacks I’ve been involved in.
This time I’ve been particularly happy and proud because I’ve organized it almost all alone. Trivadis, my employer, has kindly sponsored everything: the venue (the new, cool Trivadis offices in Geneva), the T-shirts (I’ve done the design, very similar to the one I’ve designed for Collaborate 14), beers and pizza!
For beer lovers,we’ve got the good “Blanche des Neiges” from Belgium, “La Helles” and “La Rossa” from San Martino Brewery, Ticino (Italian speaking region of Switzerland). People have appreciated 🙂
We’ve had 4 top-class Ninjas and 10 people actively installing Oracle RAC (plus a famous blogger that joined for networking), sadly two people have renounced at the last minute. For the very first time, all the participants have downloaded the Oracle Software in advance. When they’ve registered I’ve reminded twice that the software was necessary because we cannot provide it due to legal constraints.
People running the lab on Windows laptops have reported problems with VirtualBox 4.3.16 (4.3.14 has been skipped directly because of known problems). So every one had to fallback to version 4.3.12 (the last stable release, IMO).
The best praise I’ve got has been the presence of a Senior DBA coming from Nanterre! 550Km (> 5h00 by public transport door-to-door) and an overnight stay just for this event, can you believe it? 🙂
This makes me think seriously about the real necessity of organizing this kind of events around the world.
Off course, we’ve got a photo session with a lot of jumps 😉 We could not miss this RAC Attack tradition!
We’ve wrapped everything around 10:30pm, after a bit more than 5 hours of event. We’ve enjoyed a lot and had good time together chatting about Oracle RAC and about our work in general.
I feel the strong need to blog abut this very recent problem because I’ve spent a lot of time debugging it… especially because there’s no information about this error on the MOS.
Introduction
For a lab, I have prepared two RAC Container databases in physical stand-by.
Real-time query is configured (real-time apply, standby in read-only mode).
But, on the standby database, the PDB somehow was existing.
Oracle PL/SQL
1
2
3
4
5
6
7
16:20:58SYS@CDBGVA_1>selectnamefromv$pdbs;
NAME
------------------------------
PDB$SEED
MAAZ
LUDO
I’ve tried to play a little, and finally decided to disable the recovery for the PDB (new in 12.1.0.2).
But to disable the recovery I was needing to connect to the PDB, but the PDB was somehow “inexistent”:
Then I’ve shutted down the standby, but one instance hung and I’ve needed to do a shutdown abort (I don’t know if it was related with my original problem..)
So I’ve RESTARTED the recovery for a few seconds, and because the PDB had the recovery disabled, the recovery process has added the datafiles and set them offline.
Après Oracle Open World, IOUG Collaborate et d’autres grandes conférences, RAC Attack arrive également à Genève! Installez l’environnement Oracle 12c RAC sur votre laptop. Des volontaires expérimentés (ninjas) vous aideront à résoudre
toutes les énigmes apparentés et vous guideront à travers le processus
d’installation.
Ninjas Ludovico Caldara – Oracle ACE, RAC SIG European Chair & RAC Attack co-writer Luca Canali – OAK Table Member & frequent speaker Eric Grancher – OAK Table member Jacques Kostic – OCM 11g & Senior Consultant at Trivadis
Où? nouveaux bureaux Trivadis, Chemin Château-Bloch 11, CH1219 Geneva Quand? Mercredi 17 September 2014, dès 17h00 Coût? C’est un évènement GRATUIT! C’est un atelier communautaire, plaisant et
informel. Vous n’avez qu’à apporter votre laptop et votre bonne humeur! Inscription: TVD_LS_ADMIN@trivadis.com
Places limitées! Réservez votre place & votre T-shirt dès à présent: TVD_LS_ADMIN@trivadis.com
Agenda:
17.00 – Bienvenue
17.30 – RAC Attack 12c – 1ere partie
19.30 – Pizza et Bières! (sponsorisés par Trivadis)
20.00 – RAC Attack 12c – 2eme partie
22.00 – distribution des T-shirt et photo de groupe!!
TRES IMPORTANT:La participation à cet évènementrequière l’apport de votre propre laptop!
Spécifications requises:
a) 64 bit OS qui supporte Oracle Virtual Box
b) 8GB RAM, 50GB free HDD space.
En raison de contraintes juridiques, merci de télécharger à l’avance Oracle Database 12c ainsi que Grid Infrastructure pour Linux x86-64 depuis https://edelivery.oracle.com/ (et pour
plus d’informations : http://goo.gl/pqavYh).
After Oracle Open World, IOUG Collaborate and all major conferences, RAC Attack comes to Geneva! Set up Oracle 12c RAC environment on your laptop. Experienced volunteers (ninjas) will help you address any related issues and guide you through the setup process.
Ninjas Ludovico Caldara – Oracle ACE, RAC SIG European Chair & RAC Attack co-writer Luca Canali – OAK Table Member and frequent speaker Eric Grancher – OAK Table member Jacques Kostic – OCM 11g & Senior Consultant at Trivadis
Where? new Trivadis office, Chemin Château-Bloch 11, CH1219 Geneva When? Wednesday September 17th 2014, from 17h00 onwards Cost? It is a FREEevent! It is a community based, informal and enjoyable workshop.
You just need to bring your laptop and your desire to have fun! Registration: TVD_LS_ADMIN@trivadis.com
Limited places! Reserve your seat and T-shirt now: TVD_LS_ADMIN@trivadis.com
Agenda:
17.00 – Welcome
17.30 – RAC Attack 12c part I
19.30 – Pizza and Beers! (kindly sponsored by Trivadis)
20.00 – RAC Attack 12c part II
22.00 – T-shirt distribution and group photo!!
VERY IMPORTANT: To participate in the workshop, you need to bring your own laptop.
Required specification:
a) any 64 bit OS that supports Oracle Virtual Box
b) 8GB RAM, 50GB free HDD space.
Due to legal constraints, please pre-download Oracle Database 12c and Grid Infrastructure for Linux x86-64 from https://edelivery.oracle.com/ web site (further
information here: http://goo.gl/pqavYh).
I’ve just published an advanced lab on SlideShare that RAC Attack attendees may do at Collaborate this year, instead of just doing the basic 2-node RAC installation on their laptop.
We’ll offer also an advanced lab about Flex Clusters and Flex ASM (written by Maaz Anjum). Moreover, I’m working on an additional lab that allows to implement a multi-node RAC by using Virtual Box linked clones and GI Home clones like I’ve shown in my previous post.
RAC Attack at #C14LV will be like fun again. We’ll have a few t-shirts for the attendants, designed by me and Chet “Oraclenerd” Justice, kindly sponsored by OTN.
The workshop will end up with beers and snaks (again, thank you OTN for sponsoring this :-)).
If you’re planning to attend Collaborate, join us and start your conference week in a good mood 🙂
Recently I’ve had to install a four-node RAC cluster on my laptop in order to do some tests. I have found an “easy” (well, easy, it depends), fast and space-efficient way to do it so I would like to track it down.
The quick step list
Install the OS on the first node
Add the shared disks
Install the clusterware in RAC mode on on the first node only
Remove temporarily the shared disks
Clone the server as linked clone as many times as you want
Reconfigure the new nodes with the new ip and naming
Add back the shared disks on the first node and on all other nodes
Clone the GI + database homes in order to add them to the cluster
Using this method the Oracle binaries (the most space consuming portion of the RAC installation) are installed and allocated on the first node only.
The long step list
Actually you can follow many instruction steps from the RAC Attack 12c book.
Review the HW requirements but let at least 3Gb RAM for each guest + 2Gb more for your host (you may try with less RAM but everything will slow down).
Download all the SW components , additionally you may download the latest PSU (12.1.0.1.2) from MOS.
Prepare the host and install linux on the first node. When configuring the OS, make sure you enter all the required IP addresses for the additional nodes. RAC Attack has two nodes collabn1, collabn2. Add as many nodes as you want to configure. As example, the DNS config may have four nodes
Once the GI + DB are installed correctly, stop and disable the crs on the first node:
Oracle PL/SQL
1
2
3
#<GIHOME>/bin/crsctlstopcrs
#<GIHOME>/bin/crsctldisablecrs
#shutdown-hnow
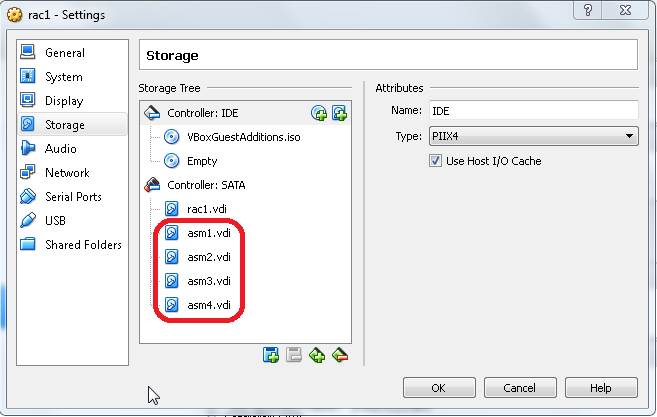
Go to the VirtualBox VM settings and delete all the shared disks
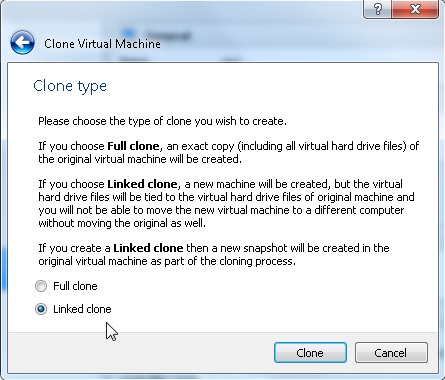
Clone the first server as linked clone (right-click, clone, choose the name, flag “Linked Clone” as many times as the number of additional servers you want.
By using this method the new servers will use the same virtual disk file of the first server and a second file will be used to track the differences. This will save a lot of space on the disk.
Once all the nodes are configured, the GI installation has to be cleaned out on all the cloned servers using these guidelines:
Shell
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
cd$GI_HOME
rm-rf log/$(hostname)
rm-rf gpnp/$(hostname)
findgpnp-typef-execrm-f{}\;
rm-rf cfgtoollogs/*
rm-rf crs/init/*
rm-rf cdata/*
rm-rf crf/*
rm-rf network/admin/*.ora
rm-rf crs/install/crsconfig_params
find.-name'*.ouibak'-execrm{}\;
find.-name'*.ouibak.1'-execrm{}\;
rm-rf root.sh*
rm-rf rdbms/audit/*
rm-rf rdbms/log/*
rm-rf inventory/backup/*
chown-Roracle:oinstall/u01/app
rm-f/etc/init.d/ohasd
rm-rf/etc/oracle
rm-rf/u01/app/oraInventory/*
Then, on each cloned server, run the perl clone.pl as follows to clone the GI home, but change the LOCAL_NODE accordingly (note: the GI Home name must be identical to the one specified in the original installation!):
Then, on the first node (that you have started and you have reactivated the clusterware stack on it with crsctl enable crs / crsctl start crs ;-)), run this command to add the new nodes in the definition of the cluster:
I know it seems a little complex, but if you have several nodes this is dramatically faster than the standard installation and also the space used is reduced. This is good if you have invested in a high-performance but low-capacity SSD disk like I did :-(.
Hope it helps, I paste here the official documentation links that I’ve used to clone the installations. The other steps are my own work.
System Configuration Collection failed:oracle.osysmodel.driver.crs.productdriver.ProductDriverException:PRCD-1061:No database exists
opatchauto failed with error code2.
So you need to patch the Oracle Homes individually if it’s a new installation.
Remind that:
The patch must be unzipped by the oracle/grid user in a directory readable to oracle and root (or it will fail with Argument(s) Error… Patch Location not valid) or other funny errors (permission denied errors in the middle of the patch process)
Must be applied by the root user
Must be applied individually and on every node, one node at time.
The opatchauto executable must belong to one of the OH you’re patching (so if you patch GI and RAC separately, you have to use the correspondent opatch.
What I’ve realized by is that Policy Managed Databases are not widely used and there is a lot misunderstanding on how it works and some concerns about implementing it in production.
My current employer Trivadis (@Trivadis, make sure to call us if your database needs a health check :-)) use PMDs as best practice, so it’s worth to spend some words on it. Isn’t it?
Why Policy Managed Databases?
PMDs are an efficient way to manage and consolidate several databases and services with the least effort. They rely on Server Pools. Server pools are used to partition physically a big cluster into smaller groups of servers (Server Pool). Each pool have three main properties:
A minumim number of servers required to compose the group
A maximum number of servers
A priority that make a server pool more important than others
If the cluster loses a server, the following rules apply:
If a pool has less than min servers, a server is moved from a pool that has more than min servers, starting with the one with lowest priority.
If a pool has less than min servers and no other pools have more than min servers, the server is moved from the server with the lowest priority.
Poolss with higher priority may give servers to pools with lower priority if the min server property is honored.
This means that if a serverpool has the greatest priority, all other server pools can be reduced to satisfy the number of min servers.
Generally speaking, when creating a policy managed database (can be existent off course!) it is assigned to a server pool rather than a single server. The pool is seen as an abstract resource where you can put workload on.
Cloud computing is a model for enabling ubiquitous, convenient, on-demand network access to a shared
pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that
can be rapidly provisioned and released with minimal management effort or service provider interaction
There are some major benefits in using policy managed databases (that’s my solely opinion):
PMD instances are created/removed automatically. This means that you can add and remove nodes nodes to/from the server pools or the whole cluster, the underlying databases will be expanded or shrinked following the new topology.
Server Pools (that are the base for PMDs) allow to give different priorities to different groups of servers. This means that if correctly configured, you can loose several physical nodes without impacting your most critical applications and without reconfiguring the instances.
PMD are the base for Quality of Service management, a 11gR2 feature that does resource management cluster-wide to achieve predictable performances on critical applications/transactions. QOS is a really advanced topic so I warn you: do not use it without appropriate knowledge. Again, Trivadis has deep knowledge on it so you may want to contact us for a consulting service (and why not, perhaps I’ll try to blog about it in the future).
RAC One Node databases (RONDs?) can work beside PMDs to avoid instance proliferation for non critical applications.
Oracle is pushing it to achieve maximum flexibility for the Cloud, so it’s a trendy technology that’s cool to implement!
I’ll find some other reasons, for sure! 🙂
What changes in real-life DB administration?
Well, the concept of having a relation Server -> Instance disappears, so at the very beginning you’ll have to be prepared to something dynamic (but once configured, things don’t change often).
As Martin pointed out in his blog, you’ll need to configure server pools and think about pools of resources rather than individual configuration items.
The spfile doesn’t contain any information related to specific instances, so the parameters must be database-wide.
The oratab will contain only the dbname, not the instance name, and the dbname is present in oratab disregarding if the server belongs to a serverpool or another.
1
2
3
+ASM1:/oracle/grid/11.2.0.3:N# line added by Agent
PMU:/oracle/db/11.2.0.3:N# line added by Agent
TST:/oracle/db/11.2.0.3:N# line added by Agent
Your scripts should take care of this.
Also, when connecting to your database, you should rely on services and access your database remotely rather than trying to figure out where the instances are running. But if you really need it you can get it:
1
2
3
4
5
6
7
# srvctl status database -d PMU
Instance PMU_4 isrunning on node node2
Instance PMU_2 isrunning on node node3
Instance PMU_3 isrunning on node node4
Instance PMU_5 isrunning on node node6
Instance PMU_1 isrunning on node node7
Instance PMU_6 isrunning on node node8
An approach for the crontab: every DBA soon or late will need to schedule tasks within the crond. Since the RAC have multiple nodes, you don’t want to run the same script many times but rather choose which node will execute it.
My personal approach (every DBA has his personal preference) is to check the instance with cardinality 1 and match it with the current node. e.g.:
1
2
3
4
5
6
7
# [ `crsctl stat res ora.tst.db -k 1 | grep STATE=ONLINE | awk '{print $NF}'` == `uname -n` ]
# echo $?
0
# [ `crsctl stat res ora.tst.db -k 1 | grep STATE=ONLINE | awk '{print $NF}'` == `uname -n` ]
# echo $?
1
In the example, TST_1 is running on node1, so the first evaluation returns TRUE. The second evaluation is done after the node2, so it returns FALSE.
This trick can be used to have an identical crontab on every server and choose at the runtime if the local server is the preferred to run tasks for the specified database.
A proof of concept with Policy Managed Databases
My good colleague Jacques Kostic has given me the access to a enterprise-grade private lab so I can show you some “live operations”.
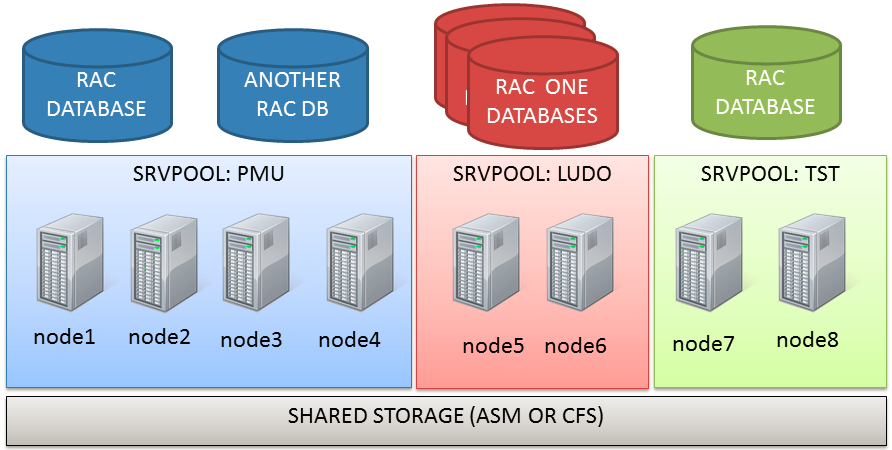
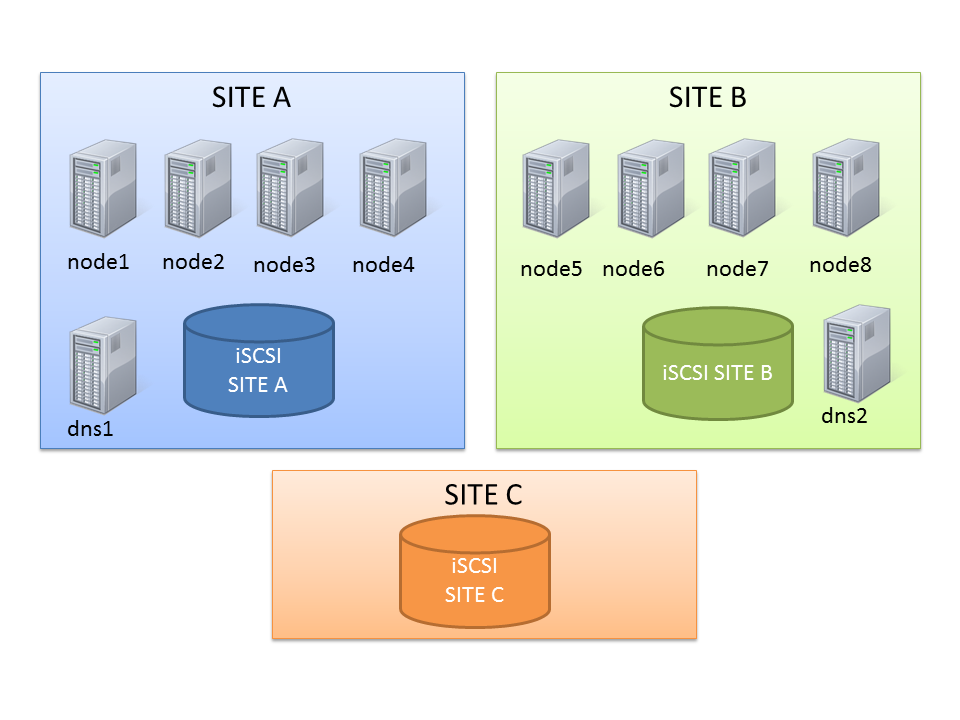
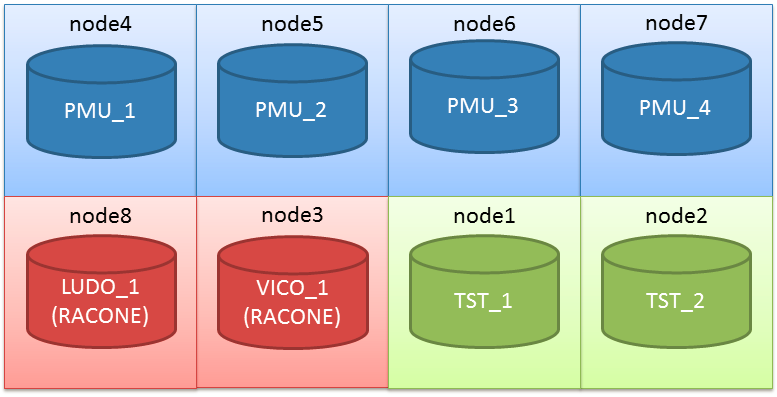
Let’s start with the actual topology: it’s an 8-node stretched RAC with ASM diskgroups with failgroups on the remote site.
This should be enough to show you some capabilities of server pools.
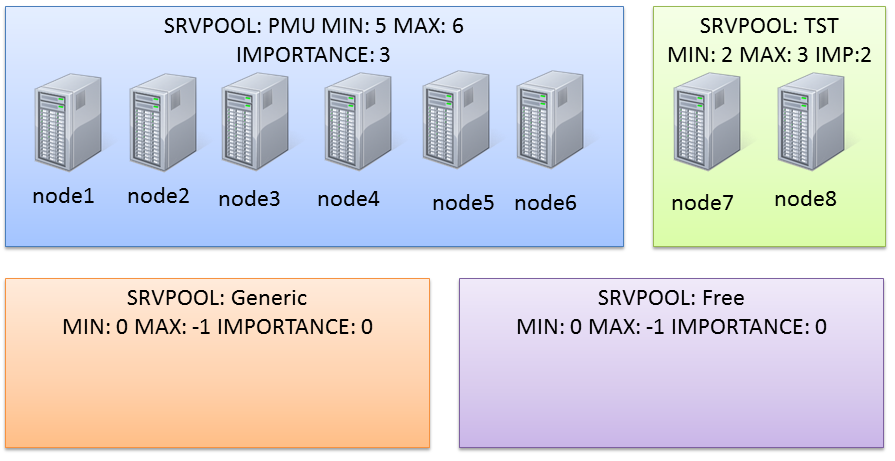
The Generic and Free server pools
After a clean installation, you’ll end up with two default server pools:
The Generic one will contain all non-PMDs (if you use only PMDs it will be empty). The Free one will own servers that are “spare”, when all server pools have reached the maximum size thus they’re not requiring more servers.
New server pools
Actually the cluster I’m working on has two serverpools already defined (PMU and TST):
(the node assignment in the graphic is not relevant here).
They have been created with a command like this one:
Oracle PL/SQL
1
#srvctladdserverpool-gPMU-l5-u6-i3
Oracle PL/SQL
1
#srvctladdserverpool-gTST-l2-u3-i2
“srvctl -h ” is a good starting point to have a quick reference of the syntax.
You can check the status with:
1
2
3
4
5
6
7
8
9
# srvctl status serverpool
Server pool name:Free
Active servers count:0
Server pool name:Generic
Active servers count:0
Server pool name:PMU
Active servers count:6
Server pool name:TST
Active servers count:2
and the configuration:
1
2
3
4
5
6
7
8
9
10
11
12
13
# srvctl config serverpool
Server pool name:Free
Importance:0,Min:0,Max:-1
Candidate server names:
Server pool name:Generic
Importance:0,Min:0,Max:-1
Candidate server names:
Server pool name:PMU
Importance:3,Min:5,Max:6
Candidate server names:
Server pool name:TST
Importance:2,Min:2,Max:3
Candidate server names:
Modifying the configuration of serverpools
In this scenario, PMU is too big. The sum of minumum nodes is 2+5=7 nodes, so I have only one server that can be used for another server pool without falling below the minimum number of nodes.
I want to make some room to make another server pool composed of two or three nodes, so I reduce the serverpool PMU:
1
# srvctl modify serverpool -g PMU -l 3
Notice that PMU maxsize is still 6, so I don’t have free servers yet.
Oracle PL/SQL
1
2
3
4
5
6
7
#srvctlstatusdatabase-dPMU
InstancePMU_4isrunningonnodenode2
InstancePMU_2isrunningonnodenode3
InstancePMU_3isrunningonnodenode4
InstancePMU_5isrunningonnodenode6
InstancePMU_1isrunningonnodenode7
InstancePMU_6isrunningonnodenode8
So, if I try to create another serverpool I’m warned that some resources can be taken offline:
1
2
3
4
5
6
# srvctl add serverpool -g LUDO -l 2 -u 3 -i 1
PRCS-1009:Failed tocreate server pool LUDO
PRCR-1071:Failed toregister orupdate server pool ora.LUDO
CRS-2737:Unable toregister server pool'ora.LUDO'asthiswill affect running resources,but the force option was notspecified
The clusterware proposes to stop 2 instances from the db pmu on the serverpool PMU because it can reduce from 6 to 3, but I have to confirm the operation with the flag -f.
Modifying the serverpool layout can take time if resources have to be started/stopped.
1
2
3
4
5
6
7
8
9
10
11
# srvctl status serverpool
Server pool name:Free
Active servers count:0
Server pool name:Generic
Active servers count:0
Server pool name:LUDO
Active servers count:2
Server pool name:PMU
Active servers count:4
Server pool name:TST
Active servers count:2
My new serverpool is finally composed by two nodes only, because I’ve set an importance of 1 (PMU wins as it has an importance of 3).
Inviting RAC One Node databases to the party
Now that I have some room on my new serverpool, I can start creating new databases.
With PMD I can add two types of databases: RAC or RACONDENODE. Depending on the choice, I’ll have a database running on ALL NODES OF THE SERVER POOL or on ONE NODE ONLY. This is a kind of limitation in my opinion, hope Oracle will improve it in the near future: would be great to specify the cardinality also at database level.
Creating a RAC One DB is as simple as selecting two radio box during in the dbca “standard” procedure:
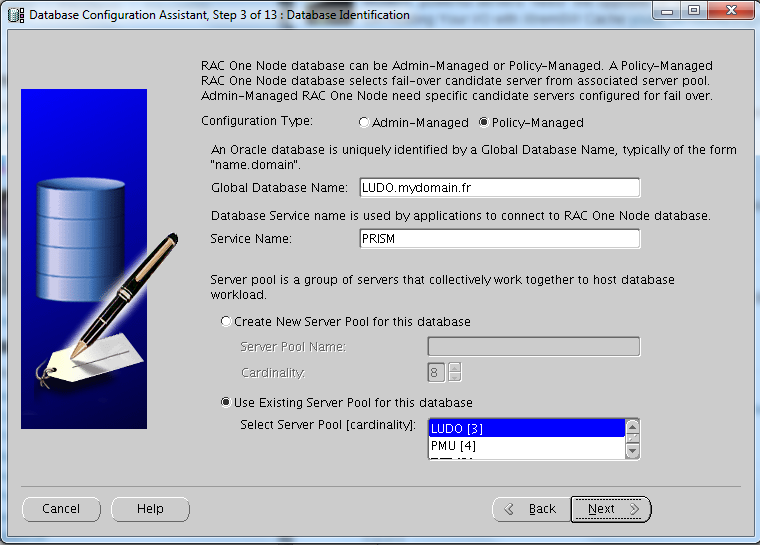
The Server Pool can be created or you can specify an existent one (as in this lab):
The node was belonging to the pool LUDO, however I have this situation right after:
1
2
3
4
5
6
7
8
9
10
11
# srvctl status serverpool
Server pool name:Free
Active servers count:0
Server pool name:Generic
Active servers count:0
Server pool name:LUDO
Active servers count:2
Server pool name:PMU
Active servers count:3
Server pool name:TST
Active servers count:2
A server has been taken from the pol PMU and given to the pool LUDO. This is because PMU was having one more server than his minimum server requirement.
Now I can loose one node at time, I’ll have the following situation:
1 node lost: PMU 3, TST 2, LUDO 2
2 nodes lost: PMU 3, TST 2, LUDO 1 (as PMU is already on min and has higher priority, LUDO is penalized because has the lowest priority)
3 nodes lost:PMU 3, TST 2, LUDO 0 (as LUDO has the lowest priority)
4 nodes lost: PMU 3, TST 1, LUDO 0
5 nodes lost: PMU 3, TST 0, LUDO 0
So, my hyper-super-critical application will still have three nodes to have plenty of resources to run even with a multiple physical failure, as it is the server pool with the highest priority and a minimum required server number of 3.
What I would ask to Santa if I’ll be on the Nice List (ad if Santa works at Redwood Shores)
Dear Santa, I would like:
To create databases with node cardinality, to have for example 2 instances in a 3 nodes server pool
Server Pools that are aware of the physical location when I use stretched clusters, so I could end up always with “at least one active instance per site”.
The installation process of a typical Standard Edition RAC does not differ from the Enterprise Edition. To achieve a successful installation refer to the nice quick guide made by Yury Velikanov and change accordingly the Edition when installing the DB software.
Standard Edition and Feature availability
The first thing that impressed me, is that you’re still able to choose to enable pluggable databases in DBCA even if Multitenant option is not available for the SE.
So I decided to create a container database CDB01 using template files, so all options of EE are normally cabled into the new DB. The Pluggable Database name is PDB01.
1
2
3
4
5
6
7
8
9
10
11
[oracle@se12c01~]$sqlplus
SQL*Plus:Release12.1.0.1.0Production on Wed Jul314:21:472013
With the Real Application Clusters andAutomatic Storage Management options
As you can see, the initial banner contains “Real Application Clusters and Automatic Storage Management options“.
Multitenant option is not avilable. How SE reacts to its usage?
First, on the ROOT db, dba_feature_usage_statistics is empty.
1
2
3
4
5
6
7
8
9
SQL>alter session set container=CDB$ROOT;
Session altered.
SQL>select *from dba_feature_usage_statistics;
no rows selected
SQL>
This is interesting, because all features are in (remember it’s created from the generic template) , so the feature check is moved from the ROOT to the pluggable databases.
On the local PDB I have:
1
2
3
4
5
6
7
8
9
SQL>alter session set container=PDB01;
Session altered.
SQL>select *from dba_feature_usage_statistics where lower(name)like'%multitenant%';
alter database move datafile'DATA/CDB01/E09CA0E26A726D60E043A138A8C0E475/DATAFILE/users.284.819821651'
*
ERROR at line1:
ORA-00439:feature notenabled:online move datafile
Create a Service on the RAC Standard Edition (just to check if it works)
I’ve just followed the steps to do it on an EE. Keep in mind that I’m using admin managed DB (something will come about policy managed DBs, stay tuned).
As you can see it works pretty well. Comparing to 11g you have to specify the -pdb parameter:
With the Real Application Clusters andAutomatic Storage Management options
SQL>show con_name
CON_NAME
------------------------------
PDB02
SQL>
Let me know what do you think about SE RAC on 12c. It is valuable for you?
I’m also on twitter: @ludovicocaldara
Cheers
—
Ludo
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.Accept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.








 Après
Après  Agenda
Agenda