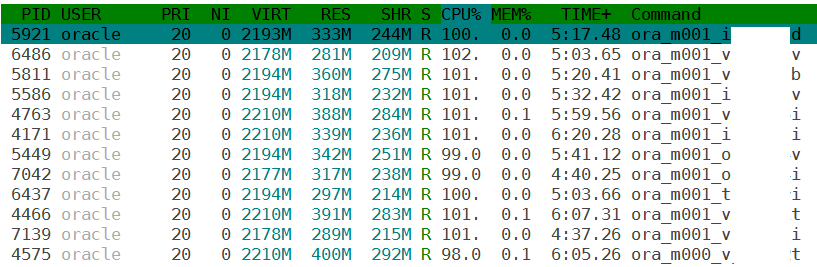
Update 14.03.2018: After some exchanges with Nigel Bayliss, the behaviour described here has been filed as unpublished bug 27626925: OPTIMIZER ADAPTIVE STATS DEFAULT FALSE NOT HONORED WHEN ENABLED IN OCT OR JAN BP. It will be fixed starting with April’s bundle patch.
According to Nigel’s blog post:
The Oracle 12.1.0.2 October 2017 BP and the Adaptive Optimizer
if you installled the patch 22652097 prior to apply the Bundle Patch 171018, the BP apply in the database should recognize that the patch was already in place and keep it activated. This is done through the fix control 26664361.
When fix_control 26664361:0 -> Patch 22652097 is not enabled: the parameter optimizer_adaptive_features (OAF) works
When fix_control 26664361:1 -> Patch 22652097 is enabled; optimizer_adaptive_features is discarded and the two new parameters have the priority: optimizer_adaptive_plans (OAP) and optimizer_adaptive_statistics (OAS).
But at my customer, I had another behavior.
My patching story might be very similar to yours!
When I started upgrading my customer’s database to 12c in early 2015, I experienced very soon the infamous problems with SQL Plan Directives (SPD) and Adaptive Dynamic Sampling (ADS) that I described in my paper: ADAPTIVE FEATURES OR: HOW I LEARNED TO STOP WORRYING AND TROUBLESHOOT THE BOMB .
Early fixes
When I was new to the problem, the quick fix for the problematic applications was to set OAF to FALSE.
Later, I discovered some more details and decided to opt for setting:
|
1 |
_optimizer_dsdir_usage_control=0 |
In other cases, I disabled the specific directives that were causing problems.
But many databases did not have so many problems, and I left the defaults.
Patch 22652097 on top of BP170718
At some point, me and my customer decided to apply the fix 22652097, on top of BP170718 that was our current patch level at that time.
The patch installation on a test database was complaining about the optimizer_adaptive_feature set: this parameter was not used anymore. This issue is nicely explained by Flora in her post Patch 22652097 in 12.1 makes optimizer_adaptive_features parameter obsolete.
In order to apply that patch on the remaining databases, we did:
- alter system reset optimizer_adaptive_features;
- alter system reset “_optimizer_dsdir_usage_control”;
- Applied the patch on binaries and datapatch on the databases.
The result at this point was that:
- optimizer_adaptive_features was not set
- optimizer_adaptive_plans was set to true
- optimizer_adaptive_statistics was set to false.
It might seems superflous to say, but it’s not, the SQL Plan Directives were not used anymore: no Adaptice Dynamic Sampling and no performance problems.
Bundle Patch 180116
Three weeks ago, we installled the last Bundle Patch in order to fix some Grid Infrastructure problems, and the BP, as described in Nigel’s note (and Mike Dietrich and many other bloggers :-)) contains the patch 22652097.
According to Nigel’s post, the patch installation should have detected that the patch 22652097 was already there and activate it.
And indeed, after we applied the BP, the fix_control 26664361 was set to 1 (that means that the patch 22652097 is enabled). So we went live with this setup without additional checks.
One week later, we started experiencing performance problems again. I noticed immediately that the Adaptive Dynamic Sampling was very aggressive again, and the SQL Plan Directives used again.
But the fix was there AND ENABLED!
After a few tests, I realized that the SPD is not used anymore if I set optimizer_adaptive_statistics EXPLICITLY to false.
optimizer_adaptive_statistics must be set explicitly, the default does not work
And here’s the proof:
I use once again the great SPD example by Tim Hall (sorry Tim, it’s not the first time that I steal your work 🙂 ) . You can find here:
SQL Plan Directives in Oracle Database 12c Release 1 (12.1)
After applying the BP, I have the default parameter, not set explicitly, and the fix_control enabled:
|
1 2 3 4 5 6 7 8 9 10 11 |
SQL> select value from v$system_fix_control where bugno = 26664361; VALUE ---------- 1 SQL> select name, value, isdefault, ismodified from v$parameter where name='optimizer_adaptive_statistics'; NAME VALUE ISDEFAULT ISMODIFIED ---------------------------------------- ------------------------------ --------- ---------------------------------------- optimizer_adaptive_statistics FALSE TRUE FALSE |
If I run the test statement (again, find it here https://oracle-base.com/articles/12c/sql-plan-directives-12cr1) the directives are used:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
SQL> SELECT /*+ GATHER_PLAN_STATISTICS */ * 2 FROM tab1 WHERE gender = 'M' AND has_y_chromosome = 'Y'; SET LINESIZE 200 PAGESIZE 100 ... 10 rows selected. SQL> SELECT * FROM TABLE(DBMS_XPLAN.display_cursor(format => 'allstats last')); PLAN_TABLE_OUTPUT -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SQL_ID 5t8y8p5mpb99j, child number 0 ------------------------------------- SELECT /*+ GATHER_PLAN_STATISTICS */ * FROM tab1 WHERE gender = 'M' AND has_y_chromosome = 'Y' Plan hash value: 1552452781 ----------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ----------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 10 |00:00:00.01 | 4 | |* 1 | TABLE ACCESS BY INDEX ROWID BATCHED| TAB1 | 1 | 10 | 10 |00:00:00.01 | 4 | |* 2 | INDEX RANGE SCAN | TAB1_GENDER_IDX | 1 | 10 | 10 |00:00:00.01 | 2 | ----------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("HAS_Y_CHROMOSOME"='Y') 2 - access("GENDER"='M') Note ----- - dynamic statistics used: dynamic sampling (level=2) - 2 Sql Plan Directives used for this statement 26 rows selected. |
but then I set the parameter explicitly:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SQL> alter system flush shared_pool; System altered. SQL> alter system set optimizer_adaptive_statistics=false; System altered. SQL> select name, value, isdefault, ismodified from v$parameter where name='optimizer_adaptive_statistics'; NAME VALUE ISDEFAULT ISMODIFIED ---------------------------------------- ------------------------------ --------- ---------------------------------------- optimizer_adaptive_statistics FALSE TRUE MODIFIED |
and the SPD usage (and consequently, ADS), are gone:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
SQL> SELECT /*+ GATHER_PLAN_STATISTICS */ * FROM tab1 WHERE gender = 'M' AND has_y_chromosome = 'Y'; SET LINESIZE 200 PAGESIZE 100 ID G H ---------- - - 1 M Y 2 M Y 3 M Y 4 M Y 5 M Y 6 M Y 7 M Y 8 M Y 9 M Y 10 M Y 10 rows selected. SQL> SELECT * FROM TABLE(DBMS_XPLAN.display_cursor(format => 'allstats last')); PLAN_TABLE_OUTPUT -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SQL_ID 5t8y8p5mpb99j, child number 0 ------------------------------------- SELECT /*+ GATHER_PLAN_STATISTICS */ * FROM tab1 WHERE gender = 'M' AND has_y_chromosome = 'Y' Plan hash value: 1552452781 ----------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ----------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 10 |00:00:00.01 | 4 | |* 1 | TABLE ACCESS BY INDEX ROWID BATCHED| TAB1 | 1 | 25 | 10 |00:00:00.01 | 4 | |* 2 | INDEX RANGE SCAN | TAB1_GENDER_IDX | 1 | 50 | 10 |00:00:00.01 | 2 | ----------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("HAS_Y_CHROMOSOME"='Y') 2 - access("GENDER"='M') 21 rows selected. |
Conclusion
Set the parameter EXPLICITLY when you apply the BP that contains the fix.
And ALWAYS test the behavior!
You can check how many statements use the dynamic sampling by following this short blog post by Dominic Brooks:
HTH