I have been installing Grid Infrastructure 18c for a while, then switched to 19c when it became GA.
At the beginning I have been overly enthusiast by the shorter installation time:
Grid Infra 19c install process is MUCH faster than 18c/12cR2. Mean time for 2 node clusters @ CERN (incl. volumes, puppet runs, etc.) lowered from 1h30 to 45mins. No GIMR anymore by default!
The GIMR is now optional, that means that deciding to install it is a choice of the customer, and a customer might like to keep it or not, depending on its practices.
Not having the GIMR by default means not having the local-mode automaton. This is also not a problem at all. The default configuration is good for most customers and works really well.
This new simplified configuration reduces some maintenance effort at the beginning, but personally I use a lot the local-mode automaton for out-of-place patching of Grid Infrastructure (read my blog posts to know why I really love the local-mode automaton), so it is something that I definitely need in my clusters.
A choice that makes sense for Oracle and most customers
Oracle vision regarding Grid Infrastructure consists of a central management of clusters, using the Oracle Domain Services Cluster. In this kind of deployment, the Management Repository, TFA, and many other services, are centralized. All the clusters use those services remotely instead of having them configured locally. The local-mode automaton is no exception: the full, enterprise-grade version of Fleet Patching and Provisioning (FPP, formerly Rapid home provisioning or RHP) allows much more than just out-of-place patching of Grid Infrastructure, so it makes perfectly sense to avoid those configurations everywhere, if you use a Domain Cluster architecture. Read more here.
Again, as I said many times in the past, doing out-of-place patching is the best approach in my opinion, but if you keep doing in-place patching, not having the local-mode automaton is not a problem at all and the default behavior in 19c is a good thing for you.
I need local-mode automaton on 19c, what I need to do at install time?
If you have many clusters, you are not installing them by hand with the graphic interface (hopefully!). In the responseFile for 19c Grid Infrastructure installation, this is all you need to change comparing to a 18c:
Registering database with Oracle Grid Infrastructure
14% complete
Copying database files
43% complete
Creating and starting Oracle instance
45% complete
49% complete
54% complete
58% complete
62% complete
Completing Database Creation
66% complete
69% complete
71% complete
Executing Post Configuration Actions
100% complete
Database creation complete. For details check the logfiles at:
/u01/app/oracle/cfgtoollogs/dbca/_mgmtdb.
Database Information:
Global Database Name:_mgmtdb
System Identifier(SID):-MGMTDB
Look at the log file "/u01/app/oracle/cfgtoollogs/dbca/_mgmtdb/_mgmtdb2.log" for further details.
Then, configure the PDB for the cluster. Pay attention to the -local switch that is not documented (or at least it does not appear in the inline help):
Oracle PL/SQL
1
$ mgmtca -local
After that, you might check that you have the PDB for your cluster inside the MGMTDB, I’ll skip this step.
Before creating the rhpserver (local-mode automaton resource), we need the volume and filesystem to make it work (read here for more information).
Again, note that there is a -local switch that is not documented. Specifying it will create the resource as a local-mode automaton and not as a full FPP Server (or RHP Server, damn, this change of name gets me mad when I write blog posts about it 🙂 ).
What I’ve realized by is that Policy Managed Databases are not widely used and there is a lot misunderstanding on how it works and some concerns about implementing it in production.
My current employer Trivadis (@Trivadis, make sure to call us if your database needs a health check :-)) use PMDs as best practice, so it’s worth to spend some words on it. Isn’t it?
Why Policy Managed Databases?
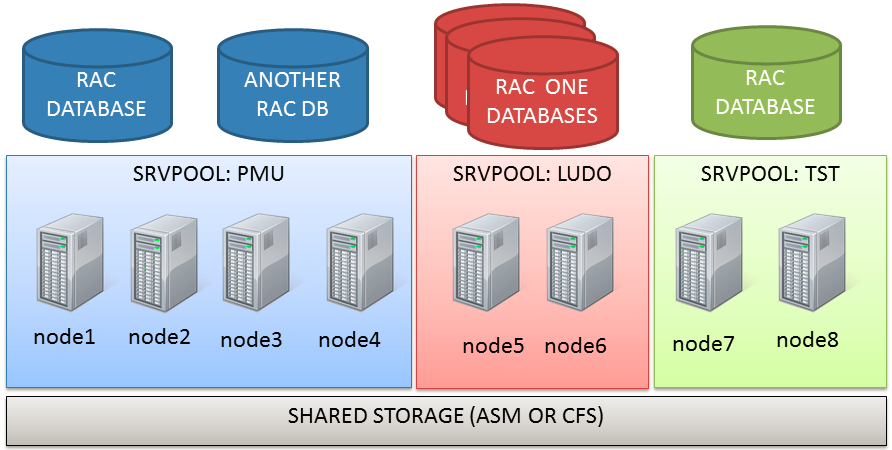
PMDs are an efficient way to manage and consolidate several databases and services with the least effort. They rely on Server Pools. Server pools are used to partition physically a big cluster into smaller groups of servers (Server Pool). Each pool have three main properties:
A minumim number of servers required to compose the group
A maximum number of servers
A priority that make a server pool more important than others
If the cluster loses a server, the following rules apply:
If a pool has less than min servers, a server is moved from a pool that has more than min servers, starting with the one with lowest priority.
If a pool has less than min servers and no other pools have more than min servers, the server is moved from the server with the lowest priority.
Poolss with higher priority may give servers to pools with lower priority if the min server property is honored.
This means that if a serverpool has the greatest priority, all other server pools can be reduced to satisfy the number of min servers.
Generally speaking, when creating a policy managed database (can be existent off course!) it is assigned to a server pool rather than a single server. The pool is seen as an abstract resource where you can put workload on.
Cloud computing is a model for enabling ubiquitous, convenient, on-demand network access to a shared
pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that
can be rapidly provisioned and released with minimal management effort or service provider interaction
There are some major benefits in using policy managed databases (that’s my solely opinion):
PMD instances are created/removed automatically. This means that you can add and remove nodes nodes to/from the server pools or the whole cluster, the underlying databases will be expanded or shrinked following the new topology.
Server Pools (that are the base for PMDs) allow to give different priorities to different groups of servers. This means that if correctly configured, you can loose several physical nodes without impacting your most critical applications and without reconfiguring the instances.
PMD are the base for Quality of Service management, a 11gR2 feature that does resource management cluster-wide to achieve predictable performances on critical applications/transactions. QOS is a really advanced topic so I warn you: do not use it without appropriate knowledge. Again, Trivadis has deep knowledge on it so you may want to contact us for a consulting service (and why not, perhaps I’ll try to blog about it in the future).
RAC One Node databases (RONDs?) can work beside PMDs to avoid instance proliferation for non critical applications.
Oracle is pushing it to achieve maximum flexibility for the Cloud, so it’s a trendy technology that’s cool to implement!
I’ll find some other reasons, for sure! 🙂
What changes in real-life DB administration?
Well, the concept of having a relation Server -> Instance disappears, so at the very beginning you’ll have to be prepared to something dynamic (but once configured, things don’t change often).
As Martin pointed out in his blog, you’ll need to configure server pools and think about pools of resources rather than individual configuration items.
The spfile doesn’t contain any information related to specific instances, so the parameters must be database-wide.
The oratab will contain only the dbname, not the instance name, and the dbname is present in oratab disregarding if the server belongs to a serverpool or another.
1
2
3
+ASM1:/oracle/grid/11.2.0.3:N# line added by Agent
PMU:/oracle/db/11.2.0.3:N# line added by Agent
TST:/oracle/db/11.2.0.3:N# line added by Agent
Your scripts should take care of this.
Also, when connecting to your database, you should rely on services and access your database remotely rather than trying to figure out where the instances are running. But if you really need it you can get it:
1
2
3
4
5
6
7
# srvctl status database -d PMU
Instance PMU_4 isrunning on node node2
Instance PMU_2 isrunning on node node3
Instance PMU_3 isrunning on node node4
Instance PMU_5 isrunning on node node6
Instance PMU_1 isrunning on node node7
Instance PMU_6 isrunning on node node8
An approach for the crontab: every DBA soon or late will need to schedule tasks within the crond. Since the RAC have multiple nodes, you don’t want to run the same script many times but rather choose which node will execute it.
My personal approach (every DBA has his personal preference) is to check the instance with cardinality 1 and match it with the current node. e.g.:
1
2
3
4
5
6
7
# [ `crsctl stat res ora.tst.db -k 1 | grep STATE=ONLINE | awk '{print $NF}'` == `uname -n` ]
# echo $?
0
# [ `crsctl stat res ora.tst.db -k 1 | grep STATE=ONLINE | awk '{print $NF}'` == `uname -n` ]
# echo $?
1
In the example, TST_1 is running on node1, so the first evaluation returns TRUE. The second evaluation is done after the node2, so it returns FALSE.
This trick can be used to have an identical crontab on every server and choose at the runtime if the local server is the preferred to run tasks for the specified database.
A proof of concept with Policy Managed Databases
My good colleague Jacques Kostic has given me the access to a enterprise-grade private lab so I can show you some “live operations”.
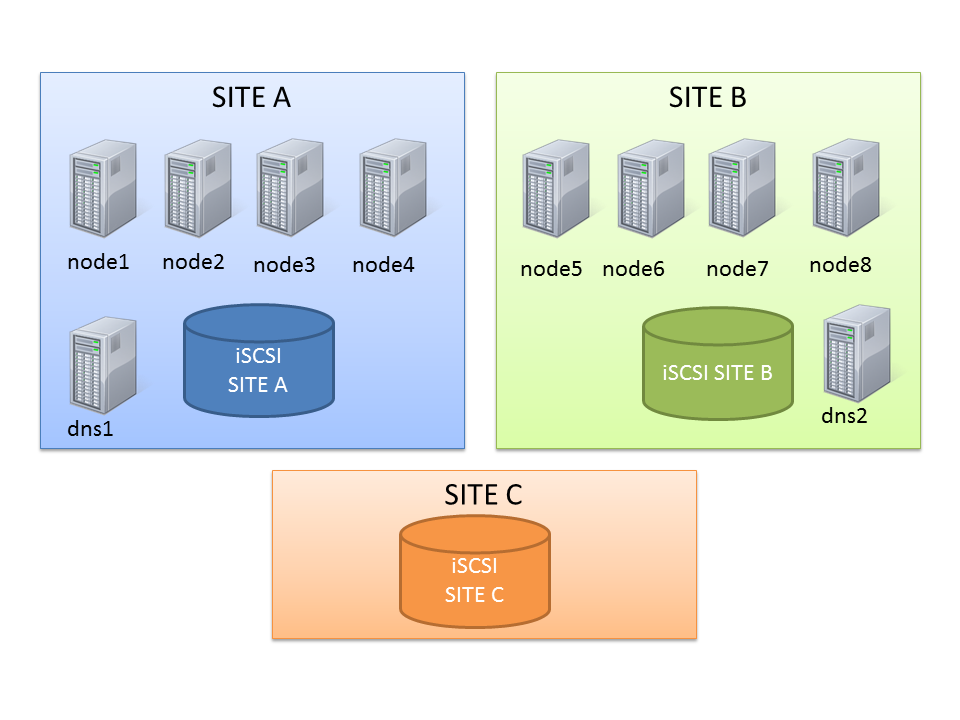
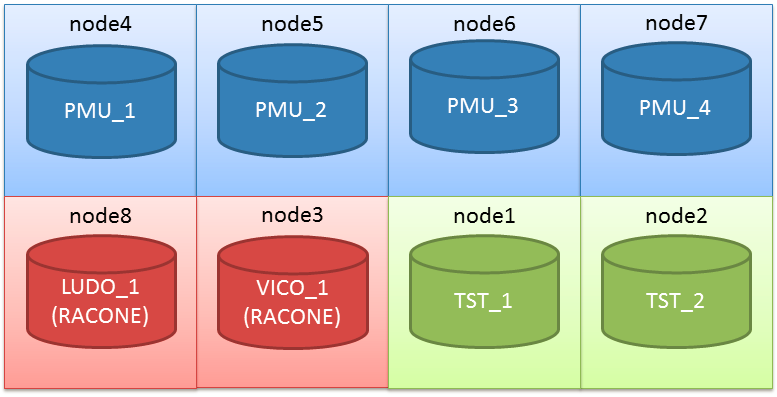
Let’s start with the actual topology: it’s an 8-node stretched RAC with ASM diskgroups with failgroups on the remote site.
This should be enough to show you some capabilities of server pools.
The Generic and Free server pools
After a clean installation, you’ll end up with two default server pools:
The Generic one will contain all non-PMDs (if you use only PMDs it will be empty). The Free one will own servers that are “spare”, when all server pools have reached the maximum size thus they’re not requiring more servers.
New server pools
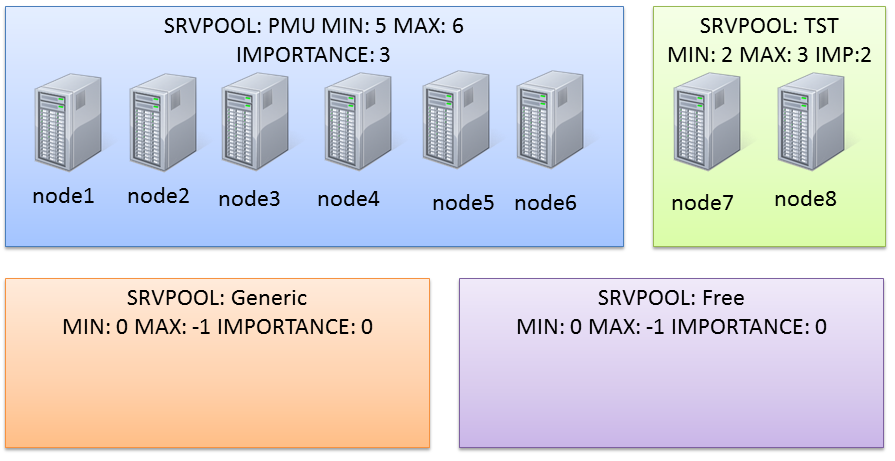
Actually the cluster I’m working on has two serverpools already defined (PMU and TST):
(the node assignment in the graphic is not relevant here).
They have been created with a command like this one:
Oracle PL/SQL
1
#srvctladdserverpool-gPMU-l5-u6-i3
Oracle PL/SQL
1
#srvctladdserverpool-gTST-l2-u3-i2
“srvctl -h ” is a good starting point to have a quick reference of the syntax.
You can check the status with:
1
2
3
4
5
6
7
8
9
# srvctl status serverpool
Server pool name:Free
Active servers count:0
Server pool name:Generic
Active servers count:0
Server pool name:PMU
Active servers count:6
Server pool name:TST
Active servers count:2
and the configuration:
1
2
3
4
5
6
7
8
9
10
11
12
13
# srvctl config serverpool
Server pool name:Free
Importance:0,Min:0,Max:-1
Candidate server names:
Server pool name:Generic
Importance:0,Min:0,Max:-1
Candidate server names:
Server pool name:PMU
Importance:3,Min:5,Max:6
Candidate server names:
Server pool name:TST
Importance:2,Min:2,Max:3
Candidate server names:
Modifying the configuration of serverpools
In this scenario, PMU is too big. The sum of minumum nodes is 2+5=7 nodes, so I have only one server that can be used for another server pool without falling below the minimum number of nodes.
I want to make some room to make another server pool composed of two or three nodes, so I reduce the serverpool PMU:
1
# srvctl modify serverpool -g PMU -l 3
Notice that PMU maxsize is still 6, so I don’t have free servers yet.
Oracle PL/SQL
1
2
3
4
5
6
7
#srvctlstatusdatabase-dPMU
InstancePMU_4isrunningonnodenode2
InstancePMU_2isrunningonnodenode3
InstancePMU_3isrunningonnodenode4
InstancePMU_5isrunningonnodenode6
InstancePMU_1isrunningonnodenode7
InstancePMU_6isrunningonnodenode8
So, if I try to create another serverpool I’m warned that some resources can be taken offline:
1
2
3
4
5
6
# srvctl add serverpool -g LUDO -l 2 -u 3 -i 1
PRCS-1009:Failed tocreate server pool LUDO
PRCR-1071:Failed toregister orupdate server pool ora.LUDO
CRS-2737:Unable toregister server pool'ora.LUDO'asthiswill affect running resources,but the force option was notspecified
The clusterware proposes to stop 2 instances from the db pmu on the serverpool PMU because it can reduce from 6 to 3, but I have to confirm the operation with the flag -f.
Modifying the serverpool layout can take time if resources have to be started/stopped.
1
2
3
4
5
6
7
8
9
10
11
# srvctl status serverpool
Server pool name:Free
Active servers count:0
Server pool name:Generic
Active servers count:0
Server pool name:LUDO
Active servers count:2
Server pool name:PMU
Active servers count:4
Server pool name:TST
Active servers count:2
My new serverpool is finally composed by two nodes only, because I’ve set an importance of 1 (PMU wins as it has an importance of 3).
Inviting RAC One Node databases to the party
Now that I have some room on my new serverpool, I can start creating new databases.
With PMD I can add two types of databases: RAC or RACONDENODE. Depending on the choice, I’ll have a database running on ALL NODES OF THE SERVER POOL or on ONE NODE ONLY. This is a kind of limitation in my opinion, hope Oracle will improve it in the near future: would be great to specify the cardinality also at database level.
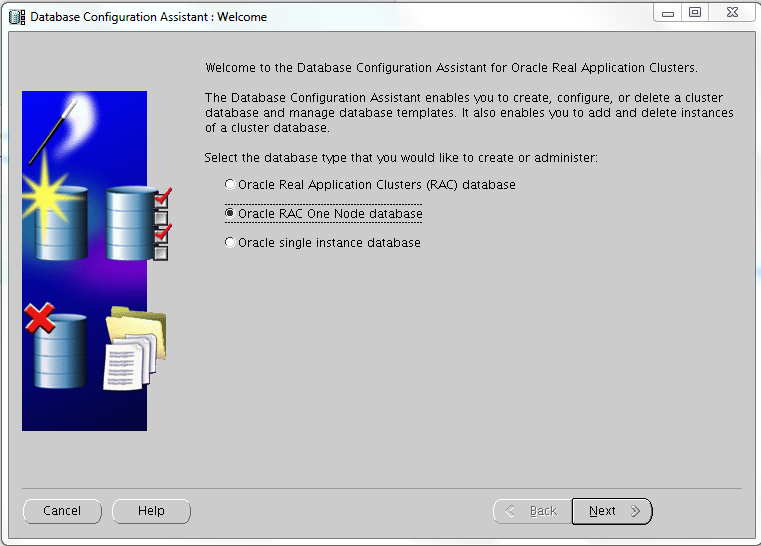
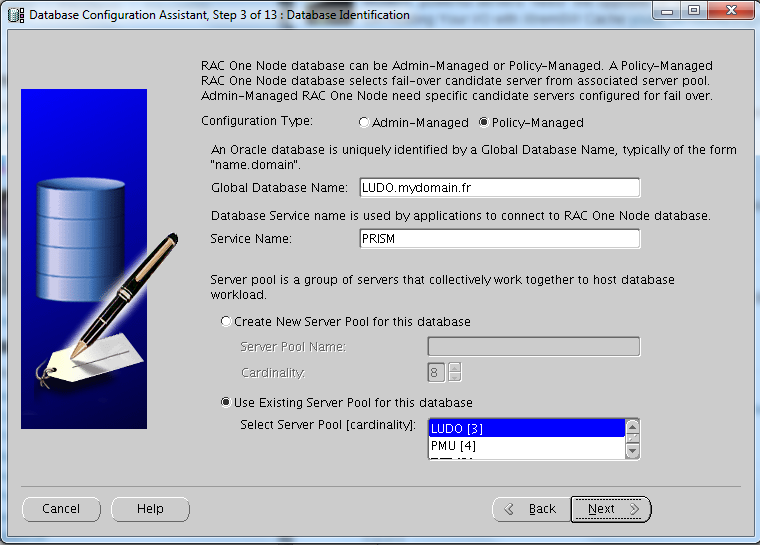
Creating a RAC One DB is as simple as selecting two radio box during in the dbca “standard” procedure:
The Server Pool can be created or you can specify an existent one (as in this lab):
The node was belonging to the pool LUDO, however I have this situation right after:
1
2
3
4
5
6
7
8
9
10
11
# srvctl status serverpool
Server pool name:Free
Active servers count:0
Server pool name:Generic
Active servers count:0
Server pool name:LUDO
Active servers count:2
Server pool name:PMU
Active servers count:3
Server pool name:TST
Active servers count:2
A server has been taken from the pol PMU and given to the pool LUDO. This is because PMU was having one more server than his minimum server requirement.
Now I can loose one node at time, I’ll have the following situation:
1 node lost: PMU 3, TST 2, LUDO 2
2 nodes lost: PMU 3, TST 2, LUDO 1 (as PMU is already on min and has higher priority, LUDO is penalized because has the lowest priority)
3 nodes lost:PMU 3, TST 2, LUDO 0 (as LUDO has the lowest priority)
4 nodes lost: PMU 3, TST 1, LUDO 0
5 nodes lost: PMU 3, TST 0, LUDO 0
So, my hyper-super-critical application will still have three nodes to have plenty of resources to run even with a multiple physical failure, as it is the server pool with the highest priority and a minimum required server number of 3.
What I would ask to Santa if I’ll be on the Nice List (ad if Santa works at Redwood Shores)
Dear Santa, I would like:
To create databases with node cardinality, to have for example 2 instances in a 3 nodes server pool
Server Pools that are aware of the physical location when I use stretched clusters, so I could end up always with “at least one active instance per site”.
Think about it 😉
—
Ludovico
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.Accept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.