I develop a lot of shell scripts. I would not define myself an old dinosaur that keeps avoiding python or other modern languages. It is just that most of my scripts automate OS commands that I would normally run interactively in an interactive shell… tar, cp, expdp, rman, dgmgrl, etc… and of course, some SQL*Plus executions.
For database calls, the shell is not appropriate: no drivers, no connection, no statement, no resultset… that’s why I need to make SQL*Plus executions (with some hacks to make them work correctly), and that’s also why I normally use python or perl for data-related tasks.
Using SQL*Plus in shell scripts
For SQL*Plus executions within a shell scripts there are some hacks, as I have said, that allow to get the data correctly.
As example, let’s use this table (that you might have found in my recent posts):
echo"doing something with variables $L_GI_Name $L_GI_Date $L_GI_Path $L_GI_Version"
done
As you can see, there are several hacks:
The credentials must be defined somewhere (I recommend putting them in a wallet)
All the output goes in a variable (or looping directly)
SQL*Plus formatting can be a problem (both sqlplus settings and concatenating fields)
Loop and get, for each line, the variables (using awk in my case)
It is not rock solid (unexpected data might compromise the results) and there are dependencies (sqlplus binary, credentials, etc.). But for many simple tasks, that’s more than enough.
Here’s the output:
Oracle PL/SQL
1
2
3
$ sh sqlplus_test.sh
doing something with values 18_3_0_cerndb1 2018-08-19 /test/path/18_3_0_cerndb1.zip 18.3.0
doing something with values 18_3_0_cerndb2 2018-08-28 /test/path/18_3_0_cerndb2.zip 18.3.0
Using ORDS instead
Recently I have come across a situation where I had no Oracle binaries but needed to get some data from a table. That is often a situation where I use python or perl, but even in these cases, I need compatible software and drivers!
So I used ORDS instead (that by chance, was already configured for the databases I wanted to query), and used curl and jq to get the data in the shell script.
First, I have defined the service in the database:
Oracle PL/SQL
1
2
3
4
5
6
7
8
9
10
11
12
BEGIN
ORDS.DEFINE_SERVICE(
p_module_name=>'ohctl',
p_base_path=>'ohctl/',
p_pattern=>'list/',
p_method=>'GET',
p_source_type=>ORDS.source_type_collection_feed,
p_source=>'SELECT name, version, fullpath, TO_CHAR(created,''YYYY-MM-DD'') as created FROM oh_golden_images WHERE oh_type=''RDBMS'' order by created',
Last part of the blog series… let’s see how to put everything together and have a single script that creates and provisions Oracle Home golden images:
Review of the points
The scripts will:
let create a golden image based on the current Oracle Home
save the golden image metadata into a repository (an Oracle schema somewhere)
list the avilable golden images and display whether they are already deployed on the current host
let provision an image locally (pull, not push), either with the default name or a new name
Todo:
Run as root in order to run root.sh automatically (or let specify the sudo command or a root password)
Manage Grid Infrastructure homes
Assumptions
There is an available Oracle schema where the golden image metadata will be stored
There is an available NFS share that contains the working copies and golden images
Some variables must be set accordingly to the environment in the script
The function setoh is defined in the environment (it might be copied inside the script)
The Instant Client is installed and “setoh ic” correctly sets its environment. This is required because there might be no sqlplus binaries available at the very first deploy
Oracle Home name and path’s basename are equal for all the Oracle Homes
Repository table
First we need a metadata table. Let’s keep it as simple as possible:
Oracle PL/SQL
1
2
3
4
5
6
CREATETABLE"OH_GOLDEN_IMAGES"(
NAMEVARCHAR2(50BYTE)
,FULLPATHVARCHAR2(200BYTE)
,CREATEDTIMESTAMP(6)
,CONSTRAINTPK_OH_GOLDEN_IMAGESPRIMARYKEY(NAME)
);
Helpers
The script has some functions that check stuff inside the central inventory.
checks if a specific Oracle Home (name) is present in the central inventory. It is helpful to check, for every golden image in the matadata repository, if it is already provisioned or not:
The image creation would be as easy as creating a zip file, but there are some files that we do not want to include in the golden image, therefore we need to create a staging directory (working copy) to clean up everything:
Home provisioning requires, beside some checks, a runInstaller -clone command, eventually a relink, eventually a setasmgid, eventually some other tasks, but definitely run root.sh. This last task is not automated yet in my deployment script.
Shell
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
# ... some checks ...
# if no new OH name specified, get the golden image name
...
# - check if image to install exists
...
# - check if OH name to install is not already installed
Checking swap space: must be greater than 500 MB. Actual 16383 MB Passed
Preparing to launch Oracle Universal Installer from /tmp/OraInstall2018-02-06_06-04-33PM. Please wait ...Oracle Universal Installer, Version 12.1.0.2.0 Production
Copyright (C) 1999, 2014, Oracle. All rights reserved.
Checking swap space: must be greater than 500 MB. Actual 16383 MB Passed
Preparing to launch Oracle Universal Installer from /tmp/OraInstall2018-02-07_12-49-50PM. Please wait ...Oracle Univers al Installer, Version 12.1.0.2.0 Production
Copyright (C) 1999, 2014, Oracle. All rights reserved.
Applying sub-patch '26717470' to OH '/u01/app/oracle/product/12_1_0_2_BP180116'
ApplySession: Optional component(s) [ oracle.oid.client, 12.1.0.2.0 ] , [ oracle.has.crs, 12.1.0.2.0 ] n ot present in the Oracle Home or a higher version is found.
I hope you find it useful! The cool thing is that once you have the golden images ready in the golden image repository, then the provisioning to all the servers is striaghtforward and requires just a couple of minutes, from nothing to a full working and patched Oracle Home.
Why applying the patch manually?
If you read everything carefully, I automated the golden image creation and provisioning, but the patching is still done manually.
The aim of this framework is not to patch all the Oracle Homes with the same patch, but to install the patch ONCE and then deploy the patched home everywhere. Because each patch has different conflicts, bugs, etc, it might be convenient to install it manually the first time and then forget it. At least this is my opinion 🙂
Of course, patch download, conflict detection, etc. can also be automated (and it is a good idea, if you have the time to implement it carefully and bullet-proof).
In the addendum blog post, I will show some scripts made by Hutchison Austria and why I find them really useful in this context.
As I explained in the previous blog posts, from a manageability perspective, you should not change the patch level of a deployed Oracle Home, but rather install and patch a new Oracle Home.
With the same principle, Oracle Homes deployed on different hosts should have an identical patch level for the same name. For example, an Oracle Home /u01/app/oracle/product/EE12_1_0_2_BP171018 should have the same patch level on all the servers.
To guarantee the same binaries and patch levels everywhere, the simple solution that I am shoing in this series is to store copies of the Oracle Homes somewhere and use them as golden images. (Another approach, really different and cool, is used by Ilmar Kerm: he explains it here https://ilmarkerm.eu/blog/2018/05/oracle-home-management-using-ansible/ )
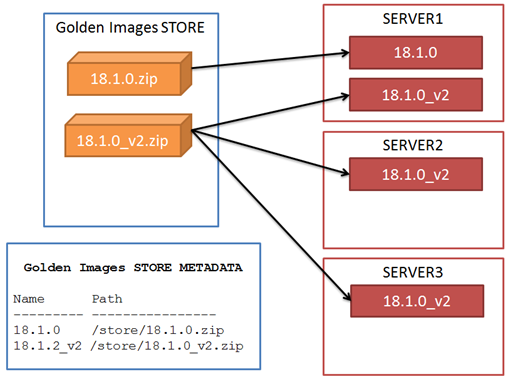
For this, we will use a Golden Image store (that could be a NFS share mounted on the Oracle Database servers, or a remote host accessible with scp, or other) and a metadata store.
When all the software is deployed from golden images, there is the guarantee that all the Homes are equal; therefore the information about patches and bugfixes might be centralized in one place (golden image metadata).
A typical Oracle Home lifecycle:
Install the software manually the first time
Create automatically a golden image from the Oracle Home
Deploy automatically the golden image on the other servers
When a new patch is needed:
Deploy automatically the golden image to a new Oracle Home
Patch manually (or automatically!) the new Oracle Home
Create automatically the new golden image with the new name
Deploy automatically the new golden image to the other servers
The script that automates this lifecycle does just two main actions:
Automates the creation of a new golden image
Deploys an existing image to an Oracle Home (either with a new path or the default one)
(optional: uninstall an existing Home)
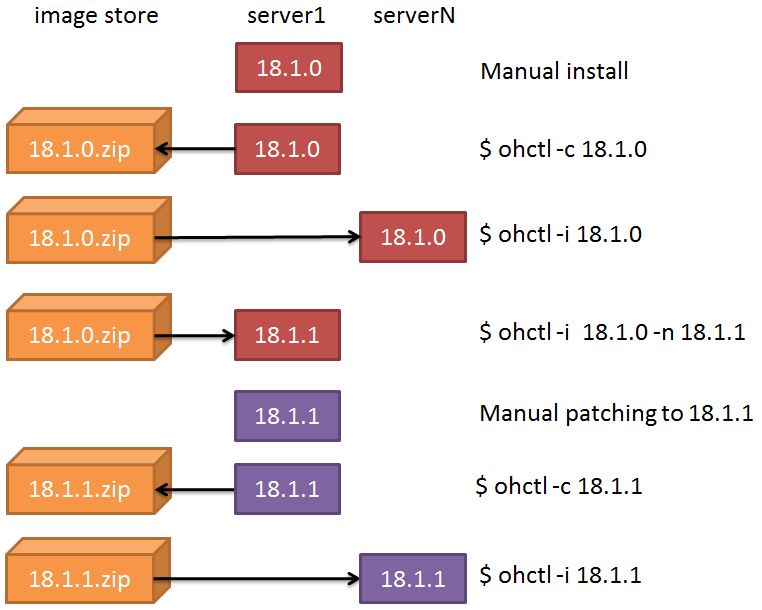
Let’s make a graphical example of the previously described steps:
Here, the script ohctl takes two actions: -c (creates a Golden Image) and -i (installs a Golden Image)).
The create action does the following steps:
Copies the content to a working directory
Cleans up logs, audits, etc.
Creates the zip file
Stores the zip file in a shared NFS repository
Inserts the metadata of the new golden image in a repository
The install action does the following steps:
Checks if the image is already deployed (plus other security checks)
Creates the new path based on the name of the image or the new name passed as argument
Unzips the content in the new Oracle Home
Runs the runInstaller –clone to attach the home in the central inventory and (optionally) set a new Home name
(optionally) Relinks the oracle binary with the RAC option
Run setasmgid if found
Other environment-specific tasks (e.g. dealing with TNS_ADMIN links)
By following this pattern, Oracle Home names and paths are clean and the same everywhere. This facilitates the deployment and the patching.
You can find the Oracle Home cloning steps in the Oracle Database documentation:
In the next blog post I will explain parts of the ohctl source code and give some examples of how I use it (and publish a link to the full source code 🙂 )
Having the capability of managing multiple Oracle Homes is fundamental for the following reasons:
Out-of-place patching: cloning and patching a new Oracle Home usually takes less downtime than stopping the DBs and patching in-place
Better control of downtime windows: if the databases are consolidated on a single server, having multiple Oracle Homes allows moving and patching one database at a time instead of stopping everything and doing a “big bang” patch.
Make sure that you have a good set of scripts that help you to switch correctly from one environment to the other one. Personally, I recommend TVD-BasEnv, as it is very powerful and supports OFA and non-OFA environments, but for this blog series I will show my personal approach.
Get your Home information from the Inventory!
I wrote a blog post sometimes ago that shows how to get the Oracle Homes from the Central Inventory (Using Bash, OK, not the right tool to query XML files, but you get the idea):
It uses a different approach from the oraenv script privided by Oracle, where you set the environment based on the ORACLE_SID variable and getting the information from the oratab. My setoh function gets the Oracle Home name as input. Although you can convert it easily to set the environment for a specific ORACLE_SID, there are some reason why I like it:
You can set the environment for an Oracle Home that it is not associated to any database (yet)
You can set the environment for an upgrade to a new release without changing (yet) the oratab
It works for OMS, Grid and Agent homes as well…
Most important, it will let you specify correctly the environment when you need to use a fresh install (for patching it as well)
In the previous example, there are two Database homes that have been installed without a specific naming convention (OraDb11g_home1, OraDB12Home1) and two that follow a specific one (12_1_0_2_BP170718_RON, 12_1_0_2_BP180116_OCW).
Naming conventions play an important role
If you want to achieve an effective Oracle Home management, it is important that you have everywhere the same ORACLE_HOME paths, names and patch levels.
The Oracle Home path should not include only the release number:
Oracle PL/SQL
1
/u01/app/oracle/product/12.1.0.2
If we have many Oracle Homes with the same release, how shall we call the other ones? There are several variables that might influence the naming convention:
Edition (EE, SE), RAC Option or other options, the patch type (formerly PSU, BP: now RU and RUR), eventual additional one-off patches.
Some ideas might be:
Oracle PL/SQL
1
2
3
/u01/app/oracle/product/EE12.1.0.2
/u01/app/oracle/product/EE12.1.0.2_BP171019
/u01/app/oracle/product/EE12.1.0.2_BP171019_v2
The new release model will facilitate a lot the definition of a naming convention as we will have names like:
Oracle PL/SQL
1
2
3
/u01/app/oracle/product/EE18.1.0
/u01/app/oracle/product/EE18.2.1
/u01/app/oracle/product/EE18.2.1_v2
Of course, the naming convention is not universal and can be adapted depending on the customer (e.g., if you have only Enterprise Editions you might omit this information).
Replacing dots with underscores?
You will see, at the end of the series, that I use Oracle Home paths with underscores instead of dots:
Oracle PL/SQL
1
2
3
/u01/app/oracle/product/EE12_1_0_2
/u01/app/oracle/product/EE12_1_0_2_BP171019
/u01/app/oracle/product/EE12_1_0_2_BP171019_v2
Why?
From a naming perspective, there is no need to have the Home that corresponds to the release number. Release, version and product information can be collected through the inventory.
What is really important is to have good naming conventions and good manageability. In my ideal world, the Oracle Home name inside the central inventory and the basename of the Oracle Home path are the same: this facilitates tremendously the scripting of the Oracle Home provisioning.
Sadly, the Oracle Home name cannot contain dots, it is a limitation of the Oracle Inventory, here’s why I replaced them with underscores.
In the next blog post, I will show how to plan a framework for automated Oracle Home provisioning.
With this post, I am starting a new blog series about Oracle Database home management, provisioning, patching… Best (and worst) practices, common practices and blueprints from my point of view as consultant and, sometimes, as operational DBA.
I hope to find the time to continue (and finish) it 🙂
How often should you upgrade/patch?
Database patching and upgrading is not an easy task, but it is really important.
Many companies do not have a clear patching strategy, for several reasons.
Patching is time consuming
It is complex
It introduces some risks
It is not always really necesary
It leads to human errors
Oracle, of course, recommends to apply the patches quarterly, as soon as they are released. But the reality is that it is (still) very common to find customers that do not apply patches regularly.
With January 2018 Bundle Patch, you can fix 1883 bugs, including 56 “wrong results”bugs! I hope I will talk more about this kind of bugs, but for now consider that if you are not patching often, you are taking serious risks, including putting at risk your data consistency.
I will not talk about bugs, upgrade procedures, new releases here… For this, I recommend to follow Mike Dietrich’s blog: Upgrade your Database – NOW!
I would like rather to talk, as the title of this blog series states, about the approaches of maintaining the Oracle Homes across your Oracle server farm.
Common worst practices in maintaining homes
Maintaining a plethora of Oracle Homes across different servers requires thoughtful planning. This is a non-exhaustive list of bad practices that I see from time to time.
Installing by hand every new Oracle Home
Applying different patch levels on Oracle Homes with the same path
Not tracking the installed patches
Having Oracle Home paths hard-coded in the operational scripts
Not minding about Oracle Home path naming convention
Not minding about Oracle Home internal names
Copying Oracle Homes without minding about the Central Inventory
All these worst practices lead to what I like to call “patching madness”… that monster that makes regular patching very difficult / impossible.
THIS IS A SITUATION THAT YOU NEED TO AVOID:
Oracle PL/SQL
1
2
3
4
5
6
7
8
9
10
Server A
/u01/app/oracle/product/12.1.0 -> Home "OraHOme12C", contains clean 12.1.0.2
Server B
/u01/app/oracle/product/12.1.0.2 -> Home "OraHome1", contains 12.1.0.2.PSU161018
/u01/app/oracle/product/12.1.0.2.BP170117 -> Home "OraHome2", contains 12.1.0.2.BP170117
Server C
/u01/app/oracle/product/12.1.0 -> Home "OraHome1", contains clean 12.1.0.1
/u01/app/oracle/product/12.1.0.2 -> Home "DBHome_1", contains 12.1.0.2.BP170117
A better approach, would be starting having some naming conventions, e.g.:
Oracle PL/SQL
1
2
3
4
5
6
7
8
9
10
Server A
/u01/app/oracle/product/12.1.0.2 -> Home "Ora12cR2", contains clean 12.1.0.2
Server B
/u01/app/oracle/product/12.1.0.2.PSU161018 -> Home "Ora12cR2_PSU161018", contains 12.1.0.2.PSU161018
/u01/app/oracle/product/12.1.0.2.BP170117 -> Home "Ora12cR2_BP170117", contains 12.1.0.2.BP170117
Server C
/u01/app/oracle/product/12.1.0.1 -> Home "Ora12cR1", contains clean 12.1.0.1
/u01/app/oracle/product/12.1.0.2.BP170117 -> Home "Ora12cR2_BP170117", contains 12.1.0.2.BP170117
In the next blog post, I will talk about common patching patterns and their pitfalls.
The nice thing, (beside speeding up the creation and basic configuration) is the organization of the directories. The configuration at the beginning of the script will result in 5 virtual machines:
Oracle PL/SQL
1
2
3
4
5
6
7
8
9
10
your VM directory
|- lab_bigdata
|- hadoop
|- hadoop01 (ol7)
|- hadoop02 (ol7)
|- hadoop03 (ol7)
|- kafka
|- kafka01 (ol7)
|- postgres
|- postgres01 (ubuntu 16.04)
It is based, in part (but modified and simplified a lot), from the RAC Attack automation scripts by Alvaro Miranda.
I have a more complex version that automates all the tasks for a full multi-cluster RAC environment, but if this is your requirement, I would rather check oravirt scripts on github (https://github.com/oravirt) . They are much more powerful and complete (and complex…) than my Vagrantfile. 🙂
Very often I encounter customers that include Oracle account passwords in their scripts in order to connect to the database.
For DBAs, sometimes things are
easier when they run scripts locally using the oracle account, since the “connect / as sysdba” usually do the job, even with some security concerns. But what if we need other users or we need to connect remotely?
Since longtime Oracle supplies secure wallets and the proxy authentication. Let’s see what they are and how to use them.
Secure Wallet
Secure wallets are managed through the tool mkstore. They allow to store a username and password in a secure wallet accessible only by its owner. The wallet is then accessed by the Oracle Client to connect to a remote database, meaning that you DON’T HAVE to specify any username and password!
Let’s see how to implement this the quick way:
Create a directory that will contain your wallet:
Shell
1
$mkdir.wlt
Create the wallet, use an arbitrary complex password to protect it:
Shell
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
$mkstore-wrl/home/ludovico/.wlt-create
Oracle Secret Store Tool:Version12.1.0.1
Copyright(c)2004,2012,Oracle and/orits affiliates.All rights reserved.
Keep in mind that you can have multiple credentials in the wallet for different remote descriptors (connect strings), but if you want many credentials for the very same connect string you need to create different wallets in different directories.
Now you need to tell your Oracle Client to use that wallet by using the wallet_location parameter in your sqlnet.ora, so you need to have a private TNS_ADMIN:
Attention: when mkstore modifies the wallet, only the clients with the same or above versions will be able to access the wallet, so if you access your wallet with a 11g client you shouldn’t modify the wallet with a 12c version of mkstore. This is not documented by Oracle, but you can infer it from different “not a bug” entries on MOS 🙂
Proxy Users You can push things a little farther, and hook your wallet with a proxy user, in order to connect to arbitrary users. That’s it, a proxy user is entitled to connect to the database on behalf of other users. In this example, we’ll see how, through the batch account, we can connect as OE, SH or HR:
Oracle PL/SQL
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
SYSTEM@PROD>alteruserOEgrantconnectthroughBATCH;
Useraltered.
SYSTEM@PROD>alteruserHRgrantconnectthroughBATCH;
Useraltered.
SYSTEM@PROD>alteruserSHgrantconnectthroughBATCH;
Useraltered.
SYSTEM@PROD>selectproxy,clientfromdba_proxies;
PROXYCLIENT
---------- --------------------
BATCHHR
BATCHSH
BATCHOE
Now I can specify with which user I want to work on the DB, connect to it through the batch account, without specifying the password thanks to the wallet:
But Oracle has fixed this twice, in the new release it’s possible to use identity columns as well, avoiding the necessity to create explicitly a new sequence:
I’ve said “explicitly” because actually a sequence is created with a system-generated name, so you’ll still need to deal with sequences.
PgSQL
1
2
3
TABLE_NAMETABLE_TYPE
------------------------------- -----------
ISEQ$$_23657SEQUENCE
cheers
Ludo
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.Accept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.