This command prepares a database to become primary in a Data Guard configuration.
It sets many recommended parameters:
Oracle PL/SQL
1
2
3
4
5
6
7
8
DB_FILES=1024
LOG_BUFFER=256M
DB_BLOCK_CHECKSUM=TYPICAL
DB_LOST_WRITE_PROTECT=TYPICAL
DB_FLASHBACK_RETENTION_TARGET=120
PARALLEL_THREADS_PER_CPU=1
STANDBY_FILE_MANAGEMENT=AUTO
DG_BROKER_START=TRUE
Sets the RMAN archive deletion policy, enables flashback and force logging, creates the standby logs according to the online redo logs configuration, and creates an spfile if the database is running with an init file.
If you tried this in 21c, you have noticed that there is an automatic restart of the database to set all the static parameters. If you weren’t expecting this, the sudden restart could be a bit brutal approach.
In 23c, we added an additional keyword “restart” to specify that you are OK with the restart of the database. If you don’t specify it, the broker will complain that it cannot proceed without a restart:
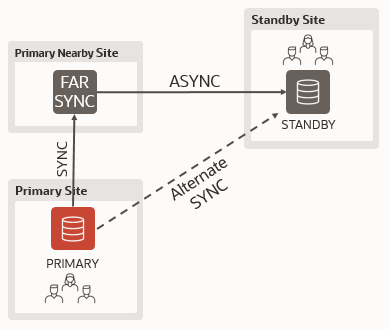
In the following configuration, cdgsima_lhr1pq (primary) sends synchronously to cdgsima_farsync1 (far sync), which forwards the redo stream asynchronously to cdgsima_lhr1bm (physical standby):
But if cdgsima_farsync1 is not available, I want the primary to send synchronously to the physical standby database. I accept a performance penalty, but I do not want to compromise my data protection.
In my config, the Oracle Database version is 19.7 and the databases are actually CDBs. No Grid Infrastructure, non-OMF datafiles.
It is important to highlight that a lot of things have changed since 12.1. And because 19c is the LTS version now, it does not make sense to try anything older.
First, I just want to make sure that my standbys are aligned.
PR00 (PID:6718): Media Recovery Waiting for T-1.S-41
So, yeah, not having OMF might get you some warnings like: WARNING: File being created with same name as in Primary
But it is good to know that the cascade standby deals well with new PDBs.
Of course, this is not of big interest as I know that the problem with Multitenant comes from CLONING PDBs from either local or remote PDBs in read-write mode.
So absolutely the same behavior between the two levels of standby.
According to the documentation: https://docs.oracle.com/en/database/oracle/oracle-database/19/sqlrf/CREATE-PLUGGABLE-DATABASE.html#GUID-F2DBA8DD-EEA8-4BB7-A07F-78DC04DB1FFC
I quote what is specified for the parameter STANDBYS={ALL|NONE|…}: “If you include a PDB in a standby CDB, then during standby recovery the standby CDB will search for the data files for the PDB. If the data files are not found, then standby recovery will stop and you must copy the data files to the correct location before you can restart recovery.”
“Specify ALL to include the new PDB in all standby CDBs. This is the default.”
“Specify NONE to exclude the new PDB from all standby CDBs. When a PDB is excluded from all standby CDBs, the PDB’s data files are unnamed and marked offline on all of the standby CDBs. Standby recovery will not stop if the data files for the PDB are not found on the standby. […]”
So, in order to avoid the MRP to crash, I should have included STANDBYS=NONE
But the documentation is not up to date, because in my case the PDB is skipped automatically and the recovery process DOES NOT STOP:
However, the recovery is marked ENABLED for the PDB on the standby, while usind STANDBYS=NONE it would have been DISABLED.
Oracle PL/SQL
1
2
3
4
5
6
7
1*selectname,recovery_statusfromv$pdbs
NAMERECOVERY
------------------------------ --------
PDB$SEEDENABLED
LATERALUSENABLED
PNEUMAENABLED
So, another difference with the doc who states: “You can enable a PDB on a standby CDB after it was excluded on that standby CDB by copying the data files to the correct location, bringing the PDB online, and marking it as enabled for recovery.”
This reflects the findings of Philippe Fierens in his blog (http://pfierens.blogspot.com/2020/04/19c-data-guard-series-part-iii-adding.html).
This behavior has been introduced probably between 12.2 and 19c, but I could not manage to find exactly when, as it is not explicitly stated in the documentation.
However, I remember well that in 12.1.0.2, the MRP process was crashing.
In my configuration, not on purpose, but interesting for this article, the first standby has the very same directory structure, while the cascaded standby has not.
In any case, there is a potentially big problem for all the customers implementing Multitenant on Data Guard:
With the old behaviour (MRP crashing), it was easy to spot when a PDB was cloned online into a primary database, because a simple dgmgrl “show configuration” whould have displayed a warning because of the increasing lag (following the MRP crash).
With the current behavior, the MRP keeps recovering and the “show configuration” displays “SUCCESS” despite there is a PDB not copied on the standby (thus not protected).
The missing PDB is easy to spot once I know that I have to do it. However, for each PDB to recover (I might have many!), I have to prepare the rename of datafiles and creation of directory (do not forget I am using non-OMF here).
Now, the datafile names on the standby got changed to …/UNNAMEDnnnnn.
So I have to get the original ones from the primary database and do the same replace that db_file_name_convert would do:
Oracle PL/SQL
1
2
3
4
settrimon
colrename_filefora300
setlines400
select'set newname for datafile '||file#||' to '''||replace(name,'/TOOLCDB1/','/TOOLCDX1/')||''';'asrename_filefromv$datafilewherecon_id=6;
and put this in a rman script (this will be for the second standby, the first has the same name so same PATH):
Then, I need to stop the recovery, start it and stopping again, put the datafiles online and finally restart the recover.
These are the same steps used my Philippe in his blog post, just adapted to my taste 🙂
Now, I do not have anymore any datafiles offline on the standby:
Oracle PL/SQL
1
2
3
SQL>select'ERROR: CON_ID '||con_id||' has '||count(*)||' datafiles offline!'fromv$recover_filewhereonline_status='OFFLINE'groupbycon_id;
norowsselected
I will not publish the steps for the second standby, they are exactly the same (same output as well).
At the end, for me it is important to highlight that monitoring the OFFLINE datafiles on the standby becomes a crucial point to guarantee the health of Data Guard in Multitenant. Relying on the Broker status or “PDB recovery disabled” is not enough.
On the bright side, it is nice to see that Cascade Standby configurations do not introduce any variation, so cascaded standbys can be threated the same as “direct” standby databases.
Ok, if you’re reading this post, you may want to read also the previous one that explains something more about the problem.
Briefly said, if you have a CDB running on ASM in a MAA architecture and you do not have Active Data Guard, when you clone a PDB you have to “copy” the datafiles somehow on the standby. The only solution offered by Oracle (in a MOS Note, not in the documentation) is to restore the PDB from the primary to the standby site, thus transferring it over the network. But if you have a huge PDB this is a bad solution because it impacts your network connectivity. (Note: ending up with a huge PDB IMHO can only be caused by bad consolidation. I do not recommend to consolidate huge databases on Multitenant).
So I’ve worked out another solution, that still has many defects and is almost not viable, but it’s technically interesting because it permits to discover a little more about Multitenant and Data Guard.
The three options
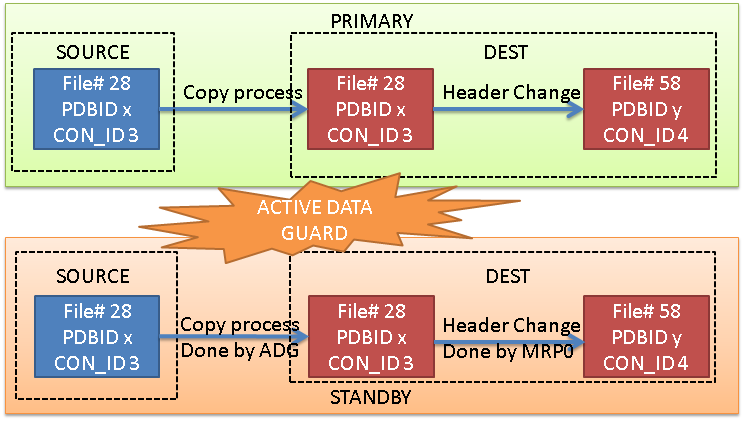
At the primary site, the process is always the same: Oracle copies the datafiles of the source, and it modifies the headers so that they can be used by the new PDB (so it changes CON_ID, DBID, FILE#, and so on).
On the standby site, by opposite, it changes depending on the option you choose:
Option 1: Active Data Guard
If you have ADG, the ADG itself will take care of copying the datafile on the standby site, from the source standby pdb to the destination standby pdb. Once the copy is done, the MRP0 will continue the recovery. The modification of the header block of the destination PDB is done by the MRP0 immediately after the copy (at least this is what I understand).
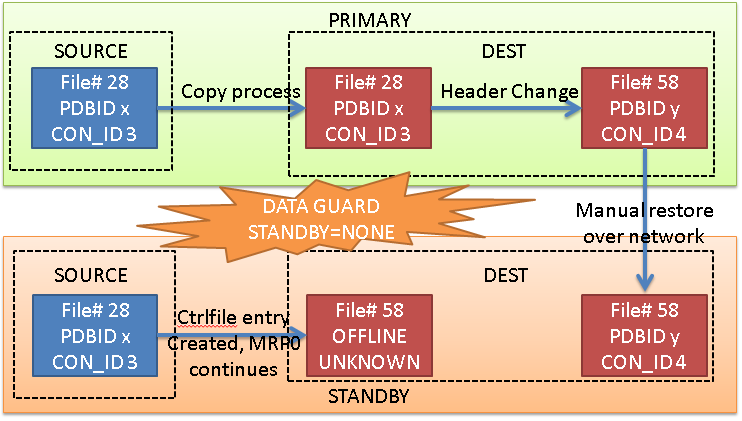
Option 2: No Active Data Guard, but STANDBYS=none
In this case, the copy on the standby site doesn’t happen, and the recovery process just add the entry of the new datafiles in the controlfile, with status OFFLINE and name UNKNOWNxxx. However, the source file cannot be copied anymore, because the MRP0 process will expect to have a copy of the destination datafile, not the source datafile. Also, any tentative of restore of the datafile 28 (in this example) will give an error because it does not belong to the destination PDB. So the only chance is to restore the destination PDB from the primary.
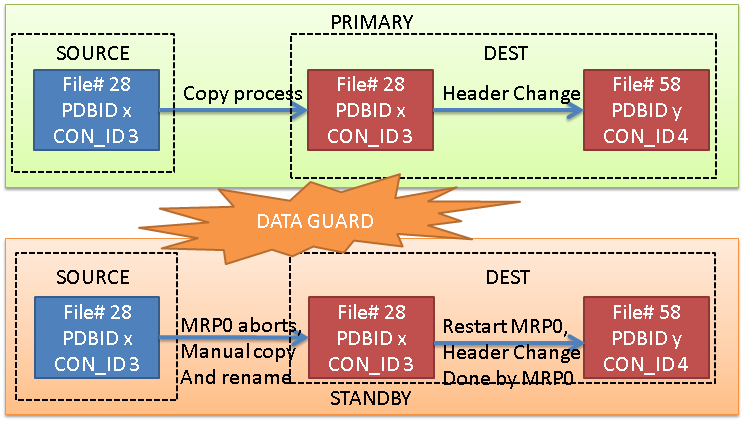
Option 3: No Active Data Guard, no STANDBYS=none
This is the case that I want to explain actually. Without the flag STANDBYS=none, the MRP0 process will expect to change the header of the new datafile, but because the file does not exist yet, the recovery process dies.
We can then copy it manually from the source standby pdb, and restart the recovery process, that will change the header. This process needs to be repeated for each datafile. (that’s why it’s not a viable solution, right now).
We need to fix the datafiles one by one, but most of the steps can be done once for all the datafiles.
Copy the source PDB from the standby
What do we need to do? Well, the recovery process is stopped, so we can safely copy the datafiles of the source PDB from the standby site because they have not moved yet. (meanwhile, we can put the primary source PDB back in read-write mode).
Now there’s the interesting part: we need to assign the datafile copies of the maaz PDB to LUDO.
Sadly, the OMF will create the copies on the bad location (it’s a copy, to they are created on the same location as the source PDB).
We cannot try to uncatalog and recatalog the copies, because they will ALWAYS be affected to the source PDB. Neither we can use RMAN because it will never associate the datafile copies to the new PDB. We need to rename the files manually.
The recovery process will:
– change the new datafile by modifying the header for the new PDB
– create the entry for the second datafile in the controlfile
– crash again because the datafile is missing
This time all the datafiles have been copied (no user datafile for this example) and the recovery process will continue!! 🙂 so we can hit ^C and start it in background.
In my #OOW14 presentation about MAA and Multitenant, more precisely at slide #59, “PDB Creation from other PDB without ADG*”, I list a few commands that you can use to achieve a “correct” Pluggable Database clone in case you’re not using Active Data Guard.
What’s the problem with cloning a PDB in a MAA environment without ADG? If you’ve attended my session you should know the answer…
If you plan to create a PDB as a clone from a different PDB, then copy the data files that belong to the source PDB over to the standby database. (This step is not necessary in an Active Data Guard environment because the data files are copied automatically when the PDB is created on the standby database.)
But because there are good possibilities (99%?) that in a MAA environment you’re using ASM, this step is not so simple: you cannot copy the datafiles exactly where you want, it’s OMF, and the recovery process expects the files to be where the controlfile says they should be.
So, if you clone the PDB, the recovery process on the standby doesn’t find the datafiles at the correct location, thus the recovery process will stop and will not start until you fix manually. That’s why Oracle has implemented the new syntax “STANDBYS=NONE” that disables the recovery on the standby for a specific PDB: it lets you disable the recovery temporarily while the recovery process continues to apply logs on the remaining PDBs. (Note, however, that this feature is not intended as a generic solution for having PDBs not replicated. The recommended solution in this case is having two distinct CDBs, one protected by DG, the other not).
With ADG, when you clone the PDB on the primary, on the standby the ADG takes care of the following steps, no matter if on ASM or FS:
recover up to the point where the file# is registered in the controlfile
copy the datafiles from the source DB ON THE STANDBY DATABASE (so no copy over the network)
rename the datafile in the controlfile
continue with the recovery
If you don’t have ADG, and you’re on ASM, Oracle documentation says nothing with enough detail to let you solve the problem. So in August I’ve worked out the “easy” solution that I’ve also included in my slides (#59 and #60):
SQL> create pluggable database DEST from SRC standbys=none;
RMAN> backup as copy pluggable database DEST format ‘/tmp/dest%f.dbf’;
$ scp /tmp/dest*.dbf remote:/tmp
RMAN> catalog start with ‘/tmp/dest’
RMAN> set newnamefor pluggable database DEST to new;
RMAN> restore pluggable database DEST;
RMAN> switch pluggable database DEST to copy;
DGMGRL> edit database ‘STBY’ set state=’APPLY-OFF’;
SQL> Alter pluggable database DEST enable recovery;
DGMGRL> edit database ‘STBY’ set state=’APPLY-ON’;
Once at #OOW14, after endless conversations at the Demo Grounds, I’ve discovered that Oracle has worked out the very same solution requiring network transfer and that it has been documented in a new note.
Making Use of the STANDBYS=NONE Feature with Oracle Multitenant (Doc ID 1916648.1)
This note is very informative and I recommend to read it carefully!
What changes (better) in comparison with my first solution, is that Oracle suggests to use the new feature “restore from service”:
Oracle PL/SQL
1
2
3
4
5
RMAN>run{
2>setnewnameforpluggabledatabaseDESTtonew;
3>restorepluggabledatabaseDESTfromserviceprim;
4>switchdatafileall;
5>}
I’ve questioned the developers at the Demo Grounds about the necessity to use network transfer (I had the chance to speak directly with the developer who has written this piece of code!! :-)) and they said that they had worked out only this solution. So, if you have a huge PDB to clone, the network transfer from the primary to standby may impact severely your Data Guard environment and/or your whole infrastructure, for the time of the transfer.
Of course, I have a complex, undocumented solution, I hope I will find the time to document it, so stay tuned if you’re curious! 🙂
Here you can find the material related to my session at Oracle Open World 2014. I’m sorry I’m late in publishing them, but I challenge you to find spare time during Oracle Open World! It’s the busiest week of the year! (Hard Work, Hard Play)
select inst_id,con_id,name,open_mode from gv\$pdbswhere con_id!=2order by con_id,inst_id;
exit
EOF
pause"please connect to the RW service"
pause"next... dgmgrl status and validate"
clear
echos"Validate Standby database"
dgmgrl<<EOF
connect sys/racattack
show configuration;
validate database'CDBGVA';
exit
EOF
pause"next... switchover to CDBGVA"
clear
echos"Switchover to CDBGVA! (it takes a while)"
dgmgrl<<EOF
connect sys/racattack
switchover to'CDBGVA';
exit
EOF
There’s one slide describing the procedure for cloning one PDB using the standbys clause. Oracle has released a Note while I was preparing my slides (one month ago) and I wasn’t aware of it, so you may also checkout this note on MOS:
Making Use of the STANDBYS=NONE Feature with Oracle Multitenant (Doc ID 1916648.1)
echo"#### IT MAY TAKE SOME MINUTES BEFORE EVERYTHING START WORKING ####"
read-p""
dgmgrl-echosys/manager<<EOF
show configuration
EOF
For the demo I’ve used 5 machines running 3 database instances and 2 Far Sync instances. I cannot provide the documentation for creating the demo environment, but the scripts may be useful to understand how the demo works.
I feel the strong need to blog abut this very recent problem because I’ve spent a lot of time debugging it… especially because there’s no information about this error on the MOS.
Introduction
For a lab, I have prepared two RAC Container databases in physical stand-by.
Real-time query is configured (real-time apply, standby in read-only mode).
But, on the standby database, the PDB somehow was existing.
Oracle PL/SQL
1
2
3
4
5
6
7
16:20:58SYS@CDBGVA_1>selectnamefromv$pdbs;
NAME
------------------------------
PDB$SEED
MAAZ
LUDO
I’ve tried to play a little, and finally decided to disable the recovery for the PDB (new in 12.1.0.2).
But to disable the recovery I was needing to connect to the PDB, but the PDB was somehow “inexistent”:
Then I’ve shutted down the standby, but one instance hung and I’ve needed to do a shutdown abort (I don’t know if it was related with my original problem..)
So I’ve RESTARTED the recovery for a few seconds, and because the PDB had the recovery disabled, the recovery process has added the datafiles and set them offline.
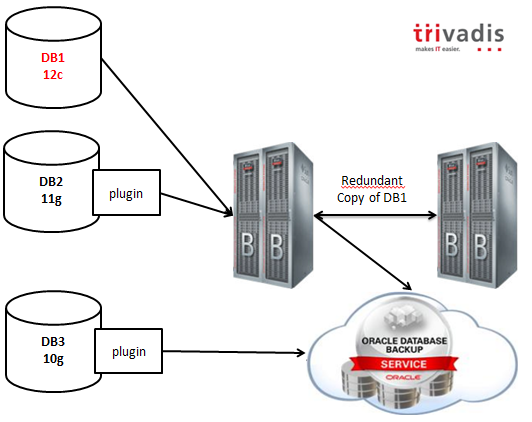
Oracle has announced the new Oracle Database Backup Logging Recovery Appliance at the last Open World 2013, but since then it has not been released to the market yet, and very few information is available on the Oracle website.
During the last IOUG Collaborate 14, Oracle master product manager of Data Guard and MAA, Larry Carpenter, has unveiled something more about the DBRLA (call it “Debra” to simplify your life 🙂 ) , and I’ve had the chance to discuss about it directly with Larry.
At Trivadis we think that this appliance will be a game changer in the world of backup management.
Why?
Well, if you have ever worked for a big company with many hundreds of databases, you have certainly encountered many of those common problems:
Oracle Backup and restore penalized by a shared infrastructure
Poor backup or restore performance
Tape drives busy when you need them urgently
Complex management of backup retentions
That’s not all. As of now, your best recovery point in case of restore is directly related to your backup archive frequency. Oh yes, you have to low down your archive_lag_target parameter, increase your log switch frequency (and thus, the I/O) and still have… 10, 15, 30 minutes of possible data loss? Unless you protect your transactions with a Data Guard. But this will cost you money. For the additional server and storage. For the licenses. And for the effort required to put in place a Data Guard instance for every database that you want to protect. You want to protect your transactions from a storage failure and there’s a price to pay.
The Database Backup Logging Recovery Appliance (wow, I need to copy and paste the name to save time! :-)) overcomes these problems with a simple but brilliant idea: leveraging the existing redo log transport processes and ship the redo stream directly to the backup appliance (the DBLRA, off course) or to its Cloud alter ego, hosted by Oracle.
As you can infer from the picture, 12c databases will work natively with the appliance, while previous releases will have a plugin that will enable all the capabilities.
Backups can be mirrored selectively to another DBLRA, or copied to the cloud or to a 3rd party (Virtual) Tape Library.
The backup retention is enforced by the appliance and the expiration and deletion is done automatically using the embedded RMAN catalog.
Lightning fast backups and restores are guaranteed by the hardware: DBLRA is based on the same hardware used by Exadata, with High Capacity disks. Optional storage extensions can be added to increase the capacity, but all the data, as I’ve said, can be offloaded to VTLs in order to use a cheaper storage for older backups.
To resume, the key values are:
No transaction loss!!
Lightning fast backups and restores
Integrated, Oracle engineered, scalable solution for hundreds to thousands of databases
Looking forward to see it in action!
I cannot cover all the information I have in a single post, but Trivadis is working actively to be ready to implement it at the time of the launch to the market (estimated in 2014), so feel free to contact me if you are interested in boosting your backup environment. 😉
By the way, I expect that the competitors (IBM, Microsoft?) will try to develop a solution with the same characteristics in terms of reliability, or they will lose terrain.
Cheers!
Ludovico
Disclaimer: This post is intended to outline Oracle’s general product direction based on the information gathered through public conferences. It is intended for informational purposes only. The development and release of these functionalities and features including the release dates remain at the sole discretion of Oracle and no documentation is available at this time. The features and commands shown may or may not be accurate when the final product release goes GA (General Availability). Please refer Oracle documentation when it becomes available.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.Accept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.

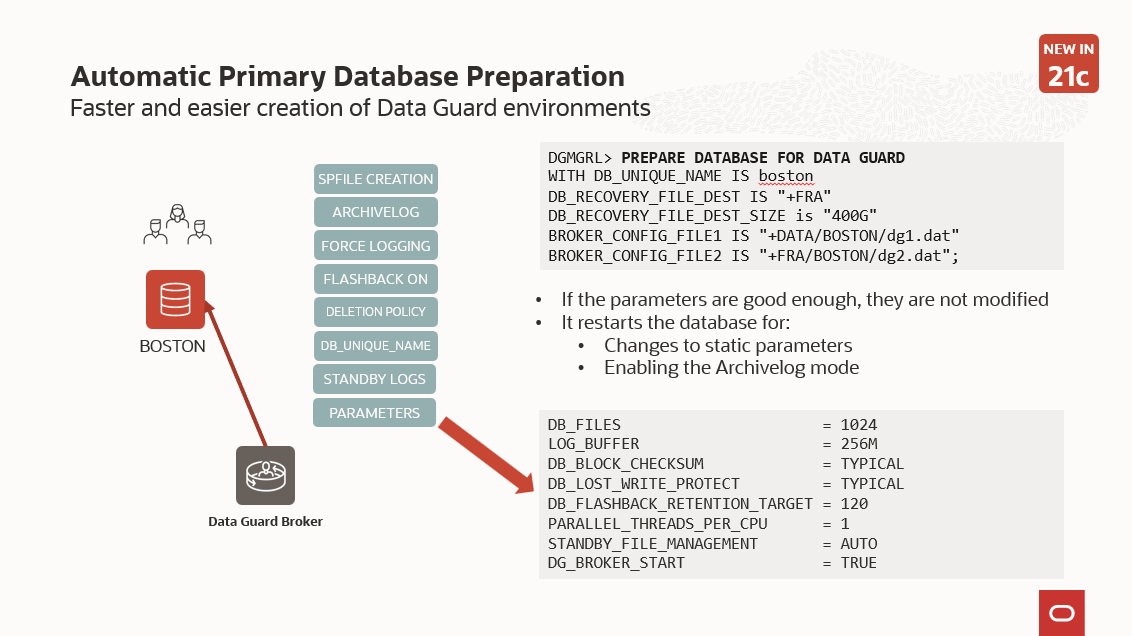 This command prepares a database to become primary in a Data Guard configuration.
This command prepares a database to become primary in a Data Guard configuration.