Cloud. What a wonderful word. Wonderful and gray.
If you are involved in the Oracle Community, blogs and conferences, you certainly care about it and have perhaps your own conception of it or ideas about how to implement it.
My Collaborate 2015 RAC SIG experience
During the last Collaborate Conference, I’ve “tried” to animate the traditional RAC SIG Round-Table with this topic:
In the last few years, cloud computing and infrastructure optimization have been the leading topics that guided the IT innovation. What’s the role of Oracle RAC in this context?
During this meeting leading RAC specialists, product managers, RAC SIG representatives and RAC Attack Ninjas will come together and discuss with you about the new Oracle RAC 12c features for the private cloud and the manageability of RAC environments.
Join us for the great discussion. This is your chance to have a great networking session!
Because it’s the RAC SIG meeting, most of the participants DO HAVE a RAC environment to manage, and are looking for best practices and ideas to improve it, or maybe they want to share their experiences.
I’ve started the session by asking how many people are currently operating a private cloud and how many would like to implement it.
With my biggest surprise (so big that I felt immediately uncomfortable), except one single person, nobody raised the hand.
What?
I’ve spent a very bad minute, I was almost speechless. I was actually asking myself: “is my conception of private cloud wrong?”. Then my good friend Yury came in help and we started the discussion about the RAC features that enable private cloud capabilities. During those 30 minutes, almost no users intervened. Then Oracle Product Managers (RAC, ASM, QoS, Cloud) started explaining their point of view, and I suddenly realized that
when talking about Private Cloud, there is a huge gap between the Oracle Private Cloud implementation best practices and the small customers skills and budgets.
When Oracle product managers talk about Private Cloud, they target big companies and advice to plan the infrastructure using:
Exadata
Full-pack of options for a total of 131k per CPU:
Enterprise Edition (47.5k)
Multitenant (17.5k)
Real Application Clusters (23k)
Partitioning (11.5k)
Diagnostic Pack (7.5k)
Tuning Pack (5k)
Lifecycle Management Pack (12k)
Cloud Management Pack (7.5k)
Flex Cluster
Policy Managed Databases
Quality of Services Management
Rapid Home provisioning
Enterprise Manager and DBaaS Self Service portal
The CapEx needed for such a stack is definitely a show stopper for most small-medium companies. And it’s not only about the cost. When I gave my presentation about Policy Managed Databases at Collaborate in 2014, and later about Multitenant and MAA at Open World, it was clear that “almost” nobody (let’s say less than 5%, just to give an idea) uses these new technologies. Many of them are new and, in some cases, not stable. Notably, Multitenant and QoS are not working together as of now. Qos will work with the new resource manager at PDB level only in release 12.2 (and still not guaranteed).
For the average company (or the average DBA), there is more than enough to be scared about, so private cloud is not seen as easy to implement.
So there’s no private cloud solution for SMBs?
It really depends on what you want to achieve, and at which level.
Based on my experience at Trivadis, I can say that you can achieve Private Cloud for less. Much less.
What a Private Cloud should guarantee? According to its NIST definition, five four things:
On-demand self-service.
Broad network access.
Resource pooling.
Rapid elasticity.
Measured service.
Number 5 is a clear field of EM, and AWR Warehouse new feature may be of great help, for free (but still, you can do a lot on your own with Statspack and some scripting if you are crazy enough to do it without Diagnostic pack).
Numbers 3 and 4 are a peculiarity of RAC, and they are included in the EE+RAC license. By leveraging OVM, there are very good opportunities of savings if the initial sizing of the solution is a problem. With OVM you can start as small as you want.
Number 1 depends on standards and automation already in place at your company. Generally speaking, nowadays scripting automatic provisioning with DBCA and APEX is very simple. If you’re not comfortable with coding, tools like the Trivadis Toolbox make this task easier. Moreover, nobody said that the self-service provisioning must be done through a web interface by the final user. It might be (and usually is) triggered by an event, like the creation of a service request, so you can keep web development outside of your cloud.
Putting all together
You can create a basic Private Cloud that fits perfectly your needs without spending or changing too much in your RAC environment.
Automation doesn’t mean cost, you can do it on your own and keep it simple. If you need an advice, ideas or some help, just drop me an email (myfirstname.mylastname@trivadis.com), it would be great to discuss about your need for private cloud!
Things can be less complex than what we often think. Our imagination is the new limit!
Did I say in some of my previous posts that I love RAC Attack? I love it more during Collaborate conference, because doing it as a pre-conference workshop is just the right way the get people involved and go straight to the goal: learning while having fun together.
We had way less people than expected but it still has been a great success!
The t-shirts have been great for coloring the room: as soon as people finished the installation of the first Linux VM, they’ve got one t-shirt.
Look at the room at the beginning of the workshop:
after a few hours, the room looked better! New ninjas, red stack, happy participants 🙂
We had a very special guest today. Mr. RAC PM in person has tried and validated our installation instructions 😉
We got pizza again, but because of restrictions at the convention center, it has been a beer-free afternoon 🙁
Thank you anyway to the OTN for sponsoring almost everything!!
Looking forward to organize the next RAC Attack, Thank you guys!! 🙂
This technical workshop and networking event (never forget it’s a project created several years ago thanks to an intuition of Jeremy Schneider), confirms to be one of the best, long-living projects in the Oracle Community. It certainly boosted my Community involvement up to becoming an Oracle ACE. This year I’m the coordinator of the organization of the workshop, it’s a double satisfaction and it will certainly be a lot of fun again. Did I said that it’s already full booked? I’ve already blogged about it (and about what the lucky participants will get) here.
One of my favorite presentations, I’ve presented it already at OOW14 and UKOUG Tech14, but it’s still a very new topic for most people, even the most experienced DBAs. You’ll learn how Multitenant, RAC and Data Guard work together. Expect colorful architecture schemas and a live demo! You can read more about it in this post.
Missing this great networking event is not an option! I’m organizing this session as RAC SIG board member (Thanks to the IOUG for this opportunity!). We’ll focus on Real Application Clusters role in the private cloud and infrastructure optimization. We’ll have many special guests, including Oracle RAC PM Markus Michalewicz, Oracle QoS PM Mark Scardina and Oracle ASM PM James Williams.
Can you ever miss it???
A good Trivadis representative!!
This year I’m not going to Las Vegas alone. My Trivadis colleague Markus Flechtner , one of the most expert RAC technologists I have the chance to know, will also come and present a session about RAC diagnostics:
Very recently I had to configure a customer’s RAC private interconnect from bonding to HAIP to get benefit of both NICs.
So I would like to recap here what the hypothetic steps would be if you need to do the same.
In this example I’ll switch from a single-NIC interconnect (eth1) rather than from a bond configuration, so if you are familiar with the RAC Attack! environment you can try to put everything in place on your own.
First, you need to plan the new network configuration in advance, keeping in mind that there are a couple of important restrictions:
Your interconnect interface naming must be uniform on all nodes in the cluster. The interconnect uses the interface name in its configuration and it doesn’t support different names on different hosts
You must bind the different private interconnect interfaces in different subnets (see Note: 1481481.1 – 11gR2 CSS Terminates/Node Eviction After Unplugging one Network Cable in Redundant Interconnect Environment if you need an explanation)
Implementation
The RAC Attack book uses one interface per node for the interconnect (eth1, using network 172.16.100.0)
To make things a little more complex, we’ll not use the eth1 in the new HAIP configuration, so we’ll test also the deletion of the old interface.
What you need to do is add two new interfaces (host only in your virtualbox) and configure them as eth2 and eth3, e.g. in networks 172.16.101.0 and 172.16.102.0)
check that the other nodes has received the new configuration:
Oracle PL/SQL
1
2
3
4
5
[root@collabn2bin]#./oifcfggetif
eth0192.168.78.0globalpublic
eth1172.16.100.0globalcluster_interconnect
eth2172.16.101.0globalcluster_interconnect
eth3172.16.102.0globalcluster_interconnect
Before deleting the old interface, it would be sensible to stop your cluster resources (in some cases, one of the nodes may be evicted), in any case the cluster must be restarted completely in order to get the new interfaces working.
Note: having three interfaces in a HAIP interconnect is perfectly working, HAIP works from 2 to 4 interfaces. I’m showing how to delete eth1 just for information!! 🙂
Once again this year the RAC Attack will be a pre-conference workshop at Collaborate.
Whether you’re a sysadmin, a developer or a DBA, I’m sure you will really enjoy this workshop. Why?
First, you get the opportunity to install a RAC 12c using Virtualbox on your laptop and get coached by many RAC experts, Oracle ACEs and ACE Directors, OCMs and famous bloggers and technologists.
If you’ve never installed it, it will be very challenging because you get hands on network components, shared disks, udev, DNS, Virtual Machine cloning, OS install and so on, and being super-user (root) of your own cluster!! If your a developer, you can then start developing your applications by testing the failover features of RAC and their scalability by checking for global cache wait events.
If you’re already used to RAC, this year we have not one or two, but three deals for you:
Try the semi-automated RAC installation using Vagrant: you’ll be able to have your RAC up and running in minutes and concentrate on advanced features.
Implement advanced labs such as Flex Cluster and Flex ASM or Policy Managed Databases, and discover Hub and Leaf nodes, Server Pools and other features
Ask the ninjas to show you other advanced scenarios or just discuss about other RAC related topics
Isn’t enough?
The participants that will complete at least the Linux install (very first stage of the workshop) will get an OTN-sponsored T-shirt of the event, with the very new RAC SIG Logo (the image is purely indicative, the actual design may change):
Still not enough?
We’ll have free pizza (at lunch) and beer (in the afternoon), again sponsored by the Oracle Technology Network. Can’t believe it? Look at a few images from last year’s edition:
To participate in the workshop, participants need to bring their own laptop. Recommended specification: a) any 64 bit OS that supports Oracle Virtual Box b) 8GB RAM, 45GB free HDD space, SSD recommended.
Important: it’s required to pre-download Oracle Database 12c and Oracle Grid Infrastructure 12c for Linux x86-64 from the Oracle Website http://tinyurl.com/rac12c-dl (four files: linuxamd64_12c_database_1of2.zip linuxamd64_12c_database_2of2.zip linuxamd64_12c_grid_1of2.zip linuxamd64_12c_grid_2of2.zip). Due to license restrictions it’s not be possible to distribute Oracle Sofware.
After almost 1 year, I’ve decided to publish these articles on my Slideshare account. You may have already seen them in the IOUG Collaborate 14 conference content or in the SOUG Newsletter 2014/4. Nothing really new, but I hope you’ll still enjoy them.
Ok, if you’re reading this post, you may want to read also the previous one that explains something more about the problem.
Briefly said, if you have a CDB running on ASM in a MAA architecture and you do not have Active Data Guard, when you clone a PDB you have to “copy” the datafiles somehow on the standby. The only solution offered by Oracle (in a MOS Note, not in the documentation) is to restore the PDB from the primary to the standby site, thus transferring it over the network. But if you have a huge PDB this is a bad solution because it impacts your network connectivity. (Note: ending up with a huge PDB IMHO can only be caused by bad consolidation. I do not recommend to consolidate huge databases on Multitenant).
So I’ve worked out another solution, that still has many defects and is almost not viable, but it’s technically interesting because it permits to discover a little more about Multitenant and Data Guard.
The three options
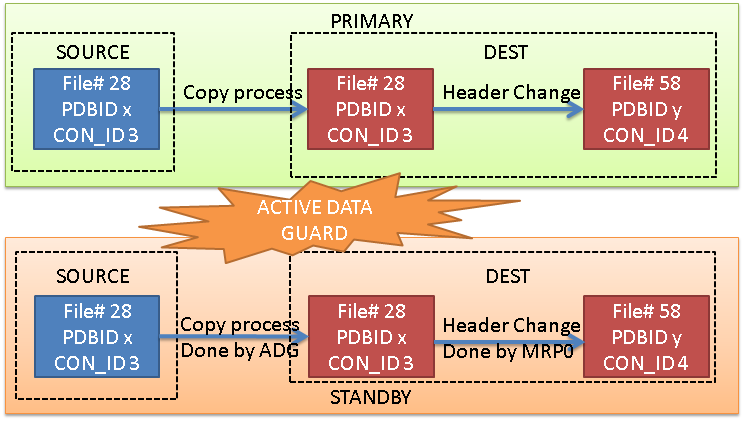
At the primary site, the process is always the same: Oracle copies the datafiles of the source, and it modifies the headers so that they can be used by the new PDB (so it changes CON_ID, DBID, FILE#, and so on).
On the standby site, by opposite, it changes depending on the option you choose:
Option 1: Active Data Guard
If you have ADG, the ADG itself will take care of copying the datafile on the standby site, from the source standby pdb to the destination standby pdb. Once the copy is done, the MRP0 will continue the recovery. The modification of the header block of the destination PDB is done by the MRP0 immediately after the copy (at least this is what I understand).
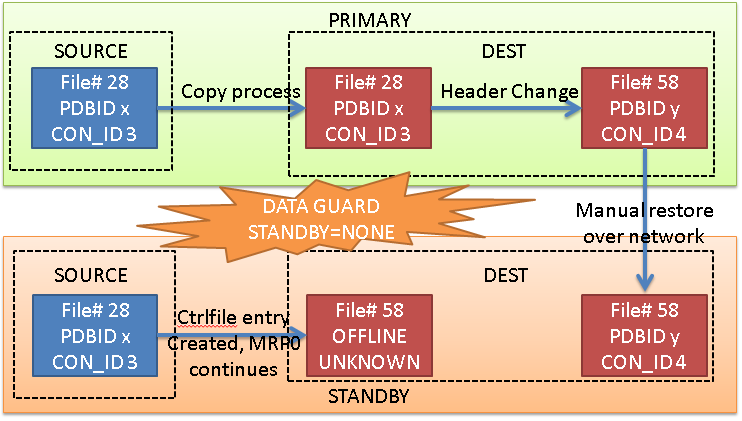
Option 2: No Active Data Guard, but STANDBYS=none
In this case, the copy on the standby site doesn’t happen, and the recovery process just add the entry of the new datafiles in the controlfile, with status OFFLINE and name UNKNOWNxxx. However, the source file cannot be copied anymore, because the MRP0 process will expect to have a copy of the destination datafile, not the source datafile. Also, any tentative of restore of the datafile 28 (in this example) will give an error because it does not belong to the destination PDB. So the only chance is to restore the destination PDB from the primary.
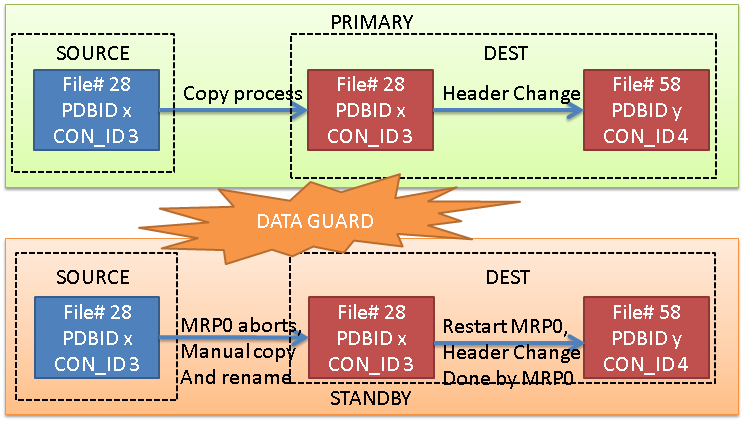
Option 3: No Active Data Guard, no STANDBYS=none
This is the case that I want to explain actually. Without the flag STANDBYS=none, the MRP0 process will expect to change the header of the new datafile, but because the file does not exist yet, the recovery process dies.
We can then copy it manually from the source standby pdb, and restart the recovery process, that will change the header. This process needs to be repeated for each datafile. (that’s why it’s not a viable solution, right now).
We need to fix the datafiles one by one, but most of the steps can be done once for all the datafiles.
Copy the source PDB from the standby
What do we need to do? Well, the recovery process is stopped, so we can safely copy the datafiles of the source PDB from the standby site because they have not moved yet. (meanwhile, we can put the primary source PDB back in read-write mode).
Now there’s the interesting part: we need to assign the datafile copies of the maaz PDB to LUDO.
Sadly, the OMF will create the copies on the bad location (it’s a copy, to they are created on the same location as the source PDB).
We cannot try to uncatalog and recatalog the copies, because they will ALWAYS be affected to the source PDB. Neither we can use RMAN because it will never associate the datafile copies to the new PDB. We need to rename the files manually.
The recovery process will:
– change the new datafile by modifying the header for the new PDB
– create the entry for the second datafile in the controlfile
– crash again because the datafile is missing
This time all the datafiles have been copied (no user datafile for this example) and the recovery process will continue!! 🙂 so we can hit ^C and start it in background.
In my #OOW14 presentation about MAA and Multitenant, more precisely at slide #59, “PDB Creation from other PDB without ADG*”, I list a few commands that you can use to achieve a “correct” Pluggable Database clone in case you’re not using Active Data Guard.
What’s the problem with cloning a PDB in a MAA environment without ADG? If you’ve attended my session you should know the answer…
If you plan to create a PDB as a clone from a different PDB, then copy the data files that belong to the source PDB over to the standby database. (This step is not necessary in an Active Data Guard environment because the data files are copied automatically when the PDB is created on the standby database.)
But because there are good possibilities (99%?) that in a MAA environment you’re using ASM, this step is not so simple: you cannot copy the datafiles exactly where you want, it’s OMF, and the recovery process expects the files to be where the controlfile says they should be.
So, if you clone the PDB, the recovery process on the standby doesn’t find the datafiles at the correct location, thus the recovery process will stop and will not start until you fix manually. That’s why Oracle has implemented the new syntax “STANDBYS=NONE” that disables the recovery on the standby for a specific PDB: it lets you disable the recovery temporarily while the recovery process continues to apply logs on the remaining PDBs. (Note, however, that this feature is not intended as a generic solution for having PDBs not replicated. The recommended solution in this case is having two distinct CDBs, one protected by DG, the other not).
With ADG, when you clone the PDB on the primary, on the standby the ADG takes care of the following steps, no matter if on ASM or FS:
recover up to the point where the file# is registered in the controlfile
copy the datafiles from the source DB ON THE STANDBY DATABASE (so no copy over the network)
rename the datafile in the controlfile
continue with the recovery
If you don’t have ADG, and you’re on ASM, Oracle documentation says nothing with enough detail to let you solve the problem. So in August I’ve worked out the “easy” solution that I’ve also included in my slides (#59 and #60):
SQL> create pluggable database DEST from SRC standbys=none;
RMAN> backup as copy pluggable database DEST format ‘/tmp/dest%f.dbf’;
$ scp /tmp/dest*.dbf remote:/tmp
RMAN> catalog start with ‘/tmp/dest’
RMAN> set newnamefor pluggable database DEST to new;
RMAN> restore pluggable database DEST;
RMAN> switch pluggable database DEST to copy;
DGMGRL> edit database ‘STBY’ set state=’APPLY-OFF’;
SQL> Alter pluggable database DEST enable recovery;
DGMGRL> edit database ‘STBY’ set state=’APPLY-ON’;
Once at #OOW14, after endless conversations at the Demo Grounds, I’ve discovered that Oracle has worked out the very same solution requiring network transfer and that it has been documented in a new note.
Making Use of the STANDBYS=NONE Feature with Oracle Multitenant (Doc ID 1916648.1)
This note is very informative and I recommend to read it carefully!
What changes (better) in comparison with my first solution, is that Oracle suggests to use the new feature “restore from service”:
Oracle PL/SQL
1
2
3
4
5
RMAN>run{
2>setnewnameforpluggabledatabaseDESTtonew;
3>restorepluggabledatabaseDESTfromserviceprim;
4>switchdatafileall;
5>}
I’ve questioned the developers at the Demo Grounds about the necessity to use network transfer (I had the chance to speak directly with the developer who has written this piece of code!! :-)) and they said that they had worked out only this solution. So, if you have a huge PDB to clone, the network transfer from the primary to standby may impact severely your Data Guard environment and/or your whole infrastructure, for the time of the transfer.
Of course, I have a complex, undocumented solution, I hope I will find the time to document it, so stay tuned if you’re curious! 🙂
DISCLAIMER: I’ve got this information by chatting with Oracle developers at the Demo Grounds. The functionality is not documented yet and Oracle may change it at its sole discretion. Please refer to the documentation if/when it will be updated 😉
Here you can find the material related to my session at Oracle Open World 2014. I’m sorry I’m late in publishing them, but I challenge you to find spare time during Oracle Open World! It’s the busiest week of the year! (Hard Work, Hard Play)
select inst_id,con_id,name,open_mode from gv\$pdbswhere con_id!=2order by con_id,inst_id;
exit
EOF
pause"please connect to the RW service"
pause"next... dgmgrl status and validate"
clear
echos"Validate Standby database"
dgmgrl<<EOF
connect sys/racattack
show configuration;
validate database'CDBGVA';
exit
EOF
pause"next... switchover to CDBGVA"
clear
echos"Switchover to CDBGVA! (it takes a while)"
dgmgrl<<EOF
connect sys/racattack
switchover to'CDBGVA';
exit
EOF
There’s one slide describing the procedure for cloning one PDB using the standbys clause. Oracle has released a Note while I was preparing my slides (one month ago) and I wasn’t aware of it, so you may also checkout this note on MOS:
Making Use of the STANDBYS=NONE Feature with Oracle Multitenant (Doc ID 1916648.1)
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.Accept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.