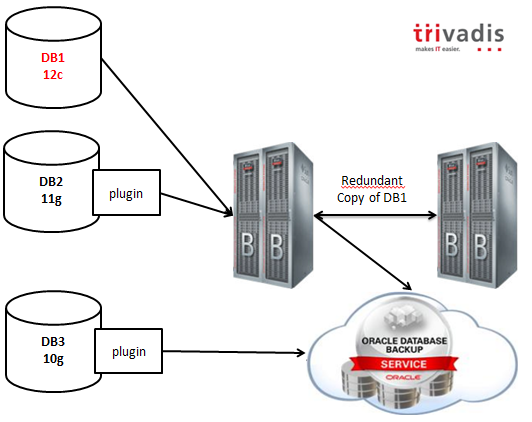
Oracle Database 12.1.0.2 is finally out, and as we all knew in advance, it contains the new in-memory option.
I think that, despite its cost ($23k per processor), this is another great improvement! 🙂
Consistent savings!
This new feature is not to be confused with Times Ten. In-memory is a feature that enable a new memory area inside the SGA that is used to contain a columnar organized copy of segments entirely in memory. Columnar stores organize the data as columns instead of rows and they are ideal for queries that involve a few columns on many rows, e.g. for analytic reports, but they work great also for all extemporary queries that cannot make use of existing indexes.
Columnar stores don’t replace traditional indexes for data integrity or fast single-row look-ups, but they can replace many additional indexes created for the solely purpose of reporting. Hence, if from one side it seems a waste of memory, on the other side using in-memory can lead to consistent memory savings due to all the indexes that have no more reason to exist.
Let’s take an example of a table (in RED) with nine indexes (other colors).

If you try to imagine all the blocks in the buffer cache, you may think about something like this:

Now, with the in-memory columnar store, you can get the rid of many indexes because they’ve been created just for reporting and they are now superseded by the performance of the new feature:

In this case, you’re not only saving blocks on disk, but also in the buffer cache, making room for the in-memory area. With columnar store, the compression factor may allow to easily fit your entire table in the same space that was previously required for a few, query-specific indexes. So you’ll have the buffer cache with traditional row-organized blocks (red, yellow, light and dark blue) and the separate in-memory area with a columnar copy of the segment (gray).
The in-memory store doesn’t make use of undo segments and redo buffer, so you’re also saving undo block buffers and physical I/O!
The added value
In my opinion this option will have much more attention from the customers than Multitenant for a very simple reason.
How many customers (in percentage) would pay to achieve better consolidation of hundreds of databases? A few.
How many would pay or are already paying for having better performance for critical applications? Almost all the customers I know!
Internal mechanisms
In-memory is enabled on a per-segment basis: you can specify a table or a partition to be stored in-memory.
Each column is organized in separate chunks of memory called In Memory Compression Units (IMCU). The number of IMCUs required for each column may vary.
Each IMCU contains the data of the column and a journal used to guarantee read consistency with the blocks in the buffer cache. The data is not modified on the fly in the IMCU, but the row it refers to is marked as stale in a journal that is stored inside the IMCU itself. When the stale data grows above a certain threshold the space efficiency of the columnar store decreases and the in-memory coordinator process ([imco]) may force a re-population of the store.
Re-population may also occur after manual intervention or at the instance startup: because it is memory-only, the data actually need to be populated in the in-memory store from disk.
Whether the data is populated immediately after the startup or not, it actually depends on the priority specified for the specific segment. The higher the priority, the sooner the segment will be populated in-memory. The priority attribute also drives which segments would survive in-memory in case of “in-memory pressure”. Sadly, the parameter inmemory_size that specifies the size of the in-memory area is static and an instance restart is required in order to change it, that’s why you need to plan carefully the size prior to its activation. There is a compression advisor for in-memory that can help out on this.
Conclusion
In this post you’ve seen a small introduction about in-memory. I hope I can publish very soon another post with a few practical examples.
 Après
Après  Agenda
Agenda