If you use Block Change Tracking on your production database and try to duplicate it, you there are good possibilities that you will encounter this error:
The problem is caused by the block change tracking file entry that exists in the target controlfile, but Oracle can’t find the file because the directory structure on the auxiliary server changes.
After the restore and recovery of the auxiliary database, the duplicate process tries to open the DB but the bct file doesn’t exist and the error is thrown.
If you do a quick google search you will find several workarounds:
disable the block change tracking after you get the error and manually open the auxiliary instance (this prevent the possibility to get the duplicate outcome from the rman return code)
disable the BCT on the target before running the duplicate (this forces your incremental backups to read all your target database!)
I don’t like to publish small code snippets, but I’ve just rewritten one of my most used SQL scripts for SQL Server that gets the details about the last backup for every database (for both backup database and backup log).
It now makes use of with () and rank() over() to make it much easier to read and modify.
Ok, if you’re reading this post, you may want to read also the previous one that explains something more about the problem.
Briefly said, if you have a CDB running on ASM in a MAA architecture and you do not have Active Data Guard, when you clone a PDB you have to “copy” the datafiles somehow on the standby. The only solution offered by Oracle (in a MOS Note, not in the documentation) is to restore the PDB from the primary to the standby site, thus transferring it over the network. But if you have a huge PDB this is a bad solution because it impacts your network connectivity. (Note: ending up with a huge PDB IMHO can only be caused by bad consolidation. I do not recommend to consolidate huge databases on Multitenant).
So I’ve worked out another solution, that still has many defects and is almost not viable, but it’s technically interesting because it permits to discover a little more about Multitenant and Data Guard.
The three options
At the primary site, the process is always the same: Oracle copies the datafiles of the source, and it modifies the headers so that they can be used by the new PDB (so it changes CON_ID, DBID, FILE#, and so on).
On the standby site, by opposite, it changes depending on the option you choose:
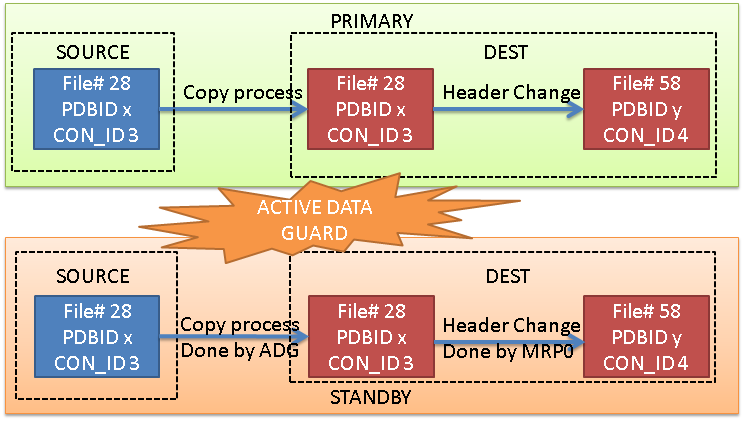
Option 1: Active Data Guard
If you have ADG, the ADG itself will take care of copying the datafile on the standby site, from the source standby pdb to the destination standby pdb. Once the copy is done, the MRP0 will continue the recovery. The modification of the header block of the destination PDB is done by the MRP0 immediately after the copy (at least this is what I understand).
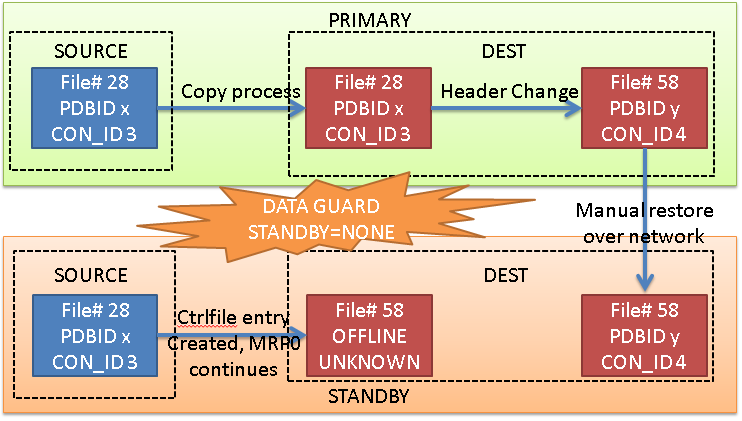
Option 2: No Active Data Guard, but STANDBYS=none
In this case, the copy on the standby site doesn’t happen, and the recovery process just add the entry of the new datafiles in the controlfile, with status OFFLINE and name UNKNOWNxxx. However, the source file cannot be copied anymore, because the MRP0 process will expect to have a copy of the destination datafile, not the source datafile. Also, any tentative of restore of the datafile 28 (in this example) will give an error because it does not belong to the destination PDB. So the only chance is to restore the destination PDB from the primary.
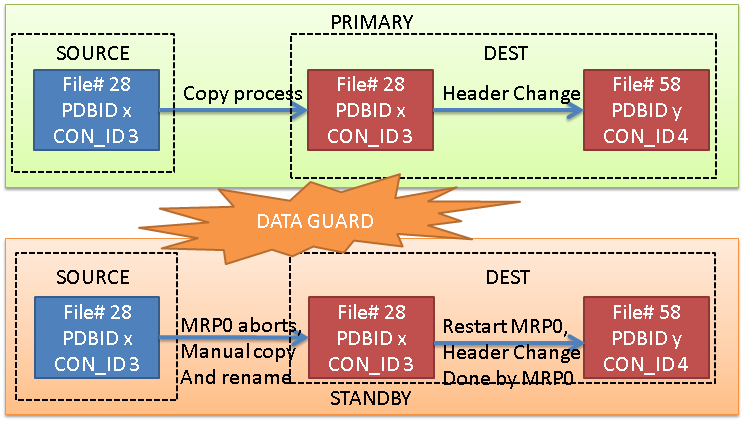
Option 3: No Active Data Guard, no STANDBYS=none
This is the case that I want to explain actually. Without the flag STANDBYS=none, the MRP0 process will expect to change the header of the new datafile, but because the file does not exist yet, the recovery process dies.
We can then copy it manually from the source standby pdb, and restart the recovery process, that will change the header. This process needs to be repeated for each datafile. (that’s why it’s not a viable solution, right now).
We need to fix the datafiles one by one, but most of the steps can be done once for all the datafiles.
Copy the source PDB from the standby
What do we need to do? Well, the recovery process is stopped, so we can safely copy the datafiles of the source PDB from the standby site because they have not moved yet. (meanwhile, we can put the primary source PDB back in read-write mode).
Now there’s the interesting part: we need to assign the datafile copies of the maaz PDB to LUDO.
Sadly, the OMF will create the copies on the bad location (it’s a copy, to they are created on the same location as the source PDB).
We cannot try to uncatalog and recatalog the copies, because they will ALWAYS be affected to the source PDB. Neither we can use RMAN because it will never associate the datafile copies to the new PDB. We need to rename the files manually.
The recovery process will:
– change the new datafile by modifying the header for the new PDB
– create the entry for the second datafile in the controlfile
– crash again because the datafile is missing
This time all the datafiles have been copied (no user datafile for this example) and the recovery process will continue!! 🙂 so we can hit ^C and start it in background.
Oracle has announced the new Oracle Database Backup Logging Recovery Appliance at the last Open World 2013, but since then it has not been released to the market yet, and very few information is available on the Oracle website.
During the last IOUG Collaborate 14, Oracle master product manager of Data Guard and MAA, Larry Carpenter, has unveiled something more about the DBRLA (call it “Debra” to simplify your life 🙂 ) , and I’ve had the chance to discuss about it directly with Larry.
At Trivadis we think that this appliance will be a game changer in the world of backup management.
Why?
Well, if you have ever worked for a big company with many hundreds of databases, you have certainly encountered many of those common problems:
Oracle Backup and restore penalized by a shared infrastructure
Poor backup or restore performance
Tape drives busy when you need them urgently
Complex management of backup retentions
That’s not all. As of now, your best recovery point in case of restore is directly related to your backup archive frequency. Oh yes, you have to low down your archive_lag_target parameter, increase your log switch frequency (and thus, the I/O) and still have… 10, 15, 30 minutes of possible data loss? Unless you protect your transactions with a Data Guard. But this will cost you money. For the additional server and storage. For the licenses. And for the effort required to put in place a Data Guard instance for every database that you want to protect. You want to protect your transactions from a storage failure and there’s a price to pay.
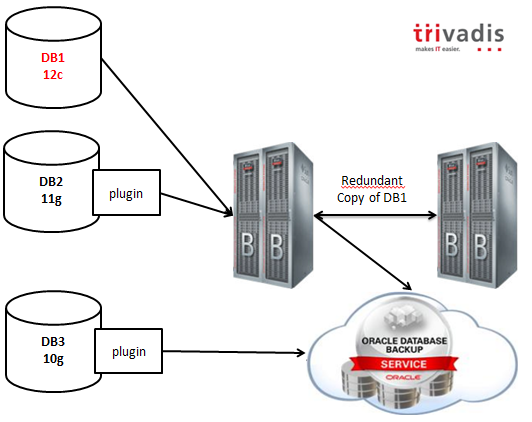
The Database Backup Logging Recovery Appliance (wow, I need to copy and paste the name to save time! :-)) overcomes these problems with a simple but brilliant idea: leveraging the existing redo log transport processes and ship the redo stream directly to the backup appliance (the DBLRA, off course) or to its Cloud alter ego, hosted by Oracle.
As you can infer from the picture, 12c databases will work natively with the appliance, while previous releases will have a plugin that will enable all the capabilities.
Backups can be mirrored selectively to another DBLRA, or copied to the cloud or to a 3rd party (Virtual) Tape Library.
The backup retention is enforced by the appliance and the expiration and deletion is done automatically using the embedded RMAN catalog.
Lightning fast backups and restores are guaranteed by the hardware: DBLRA is based on the same hardware used by Exadata, with High Capacity disks. Optional storage extensions can be added to increase the capacity, but all the data, as I’ve said, can be offloaded to VTLs in order to use a cheaper storage for older backups.
To resume, the key values are:
No transaction loss!!
Lightning fast backups and restores
Integrated, Oracle engineered, scalable solution for hundreds to thousands of databases
Looking forward to see it in action!
I cannot cover all the information I have in a single post, but Trivadis is working actively to be ready to implement it at the time of the launch to the market (estimated in 2014), so feel free to contact me if you are interested in boosting your backup environment. 😉
By the way, I expect that the competitors (IBM, Microsoft?) will try to develop a solution with the same characteristics in terms of reliability, or they will lose terrain.
Cheers!
Ludovico
Disclaimer: This post is intended to outline Oracle’s general product direction based on the information gathered through public conferences. It is intended for informational purposes only. The development and release of these functionalities and features including the release dates remain at the sole discretion of Oracle and no documentation is available at this time. The features and commands shown may or may not be accurate when the final product release goes GA (General Availability). Please refer Oracle documentation when it becomes available.
In my previous post I’ve shown how to collect data and insert it into a database table using PowerShell. Now it’s time to get some information from that data, and I’ve used TSQL for this purpose.
The backup exceptions
Every environment has some backup rules and backup exceptions. For example, you don’t want to check for failures on the model, northwind, adventureworks or distribution databases.
I’ve got the rid of this problem by using the “exception table” created in the previous post. The rules are defined by pattern matching. First we need to define a generic rule for our default backup schedules:
PgSQL
1
2
3
4
5
6
INSERTINTO[Tools].[dbo].[DB_Backup_Exceptions]
([InstanceName],[DatabaseName],[LastFullHours]
,[LastLogHours],[Description],[BestBefore])
VALUES
('%','%',36,12,'Default delays for all databases',NULL)
GO
In the previous example, we’ll check that all databases (‘%’) on all instances (again ‘%’) have been backed up at least every 36 hours, and a backup log have occurred in the last 12 hours. The description is useful to remember why such rule exists.
The “BestBefore” column allows to define the time limit of the rule. For example, if you do some maintenance and you are skipping some schedules, you can safely insert a rule that expires after X days, so you can avoid some alerts while avoiding also to forget to delete the rule.
PgSQL
1
2
3
4
5
6
INSERTINTO[Tools].[dbo].[DB_Backup_Exceptions]
([InstanceName],[DatabaseName],[LastFullHours]
,[LastLogHours],[Description],[BestBefore])
VALUES
('SERVER1','%',1000000,1000000,'Maintenance until 012.05.2013','2013-05-12 00:00:00')
GO
The previous rule will skip backup reports on SERVER1 until May 12th.
Oracle PL/SQL
1
2
3
4
5
6
INSERTINTO[Tools].[dbo].[DB_Backup_Exceptions]
([InstanceName],[DatabaseName],[LastFullHours]
,[LastLogHours],[Description],[BestBefore])
VALUES
('%','Northwind',1000000,1000000,'Don''t care about northwind',NULL)
GO
The previous rule will skip all reports on all Northwind databases.
Important: If multiple rules apply to the same database, the rule with a higher time threshold wins.
The queries
The following query lists the databases with the last backup full older than the defined threshold:
Checking database backups has always been one of the main concerns of DBAs. With Oracle is quite easy with a central RMAN catalog, but with other databases doing it with few effort can be a great challenge.
Some years ago I developed a little framework to control all SQLServer databases. This framework was based on Linux (strange but true!), bash, freetds, sqsh and flat configuration files. It’s still doing well its work, but not all SQLServer DBAs can deal with complex bash scripting, so a customer of mines asked me if I was able to rewrite it with a language Microsoft-like.
So I decided to go for a PowerShell script in conjunction with a couple of tables for the configuration and the data, and a simple TSQL script to provide HTML reporting. I have to say, I’m not an expert on PowerShell, but it’s far from being as flexible as other programming languages (damn, comparing to perl, python or php they have in common only the initial ‘P’). However I managed to do something usable.
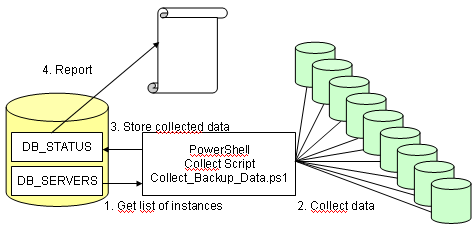
The principle
This is quite simple: the PowerShell script looks up for the list of instance in a reference table, then it sequentially connect to and retrieves the data:
recovery mode
status
creation time
last full backup
last log backup
This data is merged into a table on the central repository. Finally, a TSQL script do some reporting.
Custom classes in powershell
One of the big messes with PowerShell is the lack of the definition for custom classes, this is a special mess if we consider that PowerShell is higly object-oriented. To define your own classes to work with, you have to define them in another language (C# in this example):
PowerShell
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
Add-Type@'
using System;
public class DatabaseBackup
{
public string instanceName;
public string databaseName;
public string recoveryMode;
public string status;
public DateTime creationTime;
public DateTime lastFull;
public DateTime lastLog;
private TimeSpan diff;
public double lastFullTotalHours () {
diff = DateTime.Now - lastFull;
return Math.Round(diff.TotalHours,2);
}
public double lastLogTotalHours () {
diff = DateTime.Now - lastLog;
return Math.Round(diff.TotalHours,2);
}
}
'@
For better code reading, I’ve put this definition in a separate file (DatabaseBackup.ps1).
where type ='L' and backup_finish_date <= getdate()
group by database_name
) c
on d.name = c.database_name
where d.name <> 'Tempdb'
order by [LastFull]";
I’ve also put this snippet in a separate file queries.ps1 to improve readability.
The tables
The first table (DB_Servers) can be as simple as a single column containing the instances to check. This can be any other kind of source like a corporate CMDB or similar.
The second table will contain the data collected. Off course it can be expanded!
The third table will contain some rules for managing exceptions. Such exceptions can be useful if you have situations like “all databases named northwind should not be checked”. I’ll show some examples in the next post.
$instances=invoke-sqlcmd-Query"select [name]=db_instance from db_servers"-ServerInstance$serverName-Database$databasename
Finally, for each instance we have to check, we trigger the function that collects the data and we insert the results in the central repository (I’m using a merge to update the existent records).
You can’t use the internal powershell of SQLServer because it’s not full compatible with powershell 2.0.
Check that the table db_status is getting populated
Limitations
The script use Windows authentication, assuming you are working with a centralized domain user. If you want to use the SQL authentication (example if you are a multi-tenant managed services provider) you need to store your passwords somewhere…
This script is intended to be used with single instances. It should works on clusters but I haven’t tested it.
Check the backup chain up to the tape library. Relying on the information contained in the msdb is not a reliable monitoring solution!!
In my next post we’ll see how to generate HTML reports via email and manage exceptions.
Hope you’ll find it useful.
Again PLEASE, if you improve it, kindly send me back a copy or blog it and post the link in the comments!
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.Accept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.