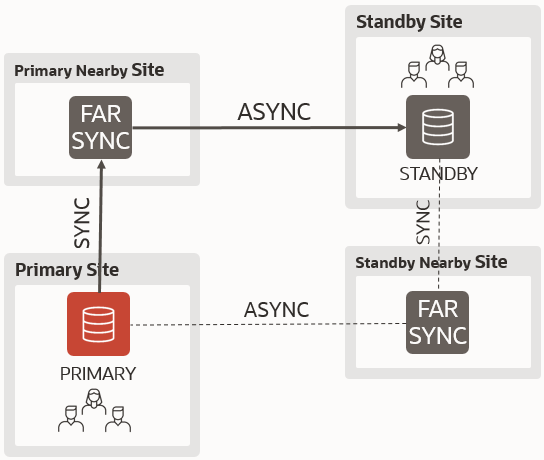
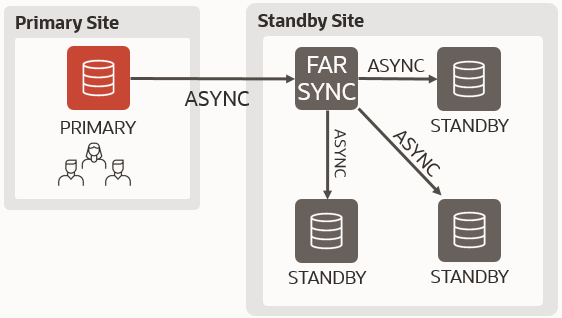
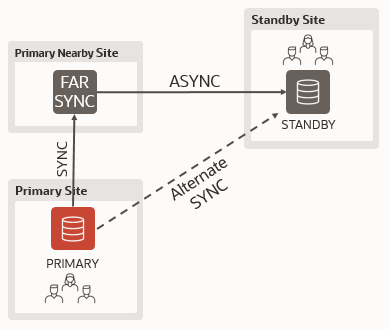
Short answer: yes.
Let’s just see it in action.
First, I have a Data Guard configuration in place. On the primary database, the current incarnation has a single parent (the template from which it has been created):
|
1 2 3 4 5 6 7 8 9 10 11 |
SQL> select * from v$database_incarnation; INCARNATION# RESETLOGS_CHANGE# RESETLOGS PRIOR_RESETLOGS_CHANGE# PRIOR_RES ------------ ----------------- --------- ----------------------- --------- STATUS RESETLOGS_ID PRIOR_INCARNATION# FLASHBACK_DATABASE_ALLOWED CON_ID ------- ------------ ------------------ -------------------------- ---------- 1 1 14-AUG-23 0 PARENT 1144840863 0 NO 0 2 1343420 08-DEC-23 1 14-AUG-23 CURRENT 1155034180 1 NO 0 |
Just to make room for some undo, I increase the undo_retention. On a PDB, that requires LOCAL UNDO to be configured (I hope it’s the default everywhere nowadays).
|
1 2 3 4 5 6 7 |
SQL> alter session set container=PDB1; Session altered. SQL> alter system set undo_retention=86400; System altered. |
Then, I update some data to test flashback query:
|
1 2 3 4 5 6 7 8 9 10 11 |
SQL> alter session set current_schema=HR; Session altered. SQL> update hr.employees set HIRE_DATE=sysdate where employee_id=100; 1 row updated. SQL> commit; Commit complete. |
At this point, I can see the current data, and the data as it was 1 hour ago:
|
1 2 3 4 5 6 7 8 9 10 11 |
SQL> select hire_date from hr.employees where employee_id=100; HIRE_DATE --------- 13-DEC-23 SQL> select hire_date from hr.employees as of timestamp systimestamp-1/24 where employee_id=100; HIRE_DATE --------- 17-JUN-03 |
Now, I kill the primary database and fail over to the standby database:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# on the primary: [ primary ] bash-4.4$ ps -eaf | grep pmon lcaldara 1485907 1 0 10:29 ? 00:00:00 ora_pmon_orcl lcaldara 1486768 1484883 0 10:37 pts/0 00:00:00 grep pmon [ primary ] bash-4.4$ kill -9 1485907 # on the standby: DGMGRL> connect / Connected to "orcl_site2" Connected as SYSDG. DGMGRL> failover to "orcl_site2"; 2023-12-13T10:38:31.179+00:00 Performing failover NOW, please wait... 2023-12-13T10:38:37.728+00:00 Failover succeeded, new primary is "orcl_site2". 2023-12-13T10:38:37.729+00:00 Failover processing complete, broker ready. DGMGRL> |
After connecting to the new primary, I can see the new incarnation due to the open resetlogs after the failover.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
SQL> select * from v$database_incarnation; INCARNATION# RESETLOGS_CHANGE# RESETLOGS PRIOR_RESETLOGS_CHANGE# PRIOR_RES ------------ ----------------- --------- ----------------------- --------- STATUS RESETLOGS_ID PRIOR_INCARNATION# FLASHBACK_DATABASE_ALLOWED CON_ID ------- ------------ ------------------ -------------------------- ---------- 1 1 14-AUG-23 0 PARENT 1144840863 0 NO 0 2 1343420 08-DEC-23 1 14-AUG-23 PARENT 1155034180 1 NO 0 3 2704078 13-DEC-23 1343420 08-DEC-23 CURRENT 1155465511 2 NO 0 |
And I can still query the data as of a previous timestamp:
|
1 2 3 4 5 6 7 8 9 10 11 |
SQL> select hire_date from hr.employees where employee_id=100; HIRE_DATE --------- 13-DEC-23 SQL> select hire_date from hr.employees as of timestamp systimestamp-1/24 where employee_id=100; HIRE_DATE --------- 17-JUN-03 |
Or flash back the table, if required:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
SQL> flashback table hr.employees to timestamp sysdate-1/24; flashback table hr.employees to timestamp sysdate-1/24 * ERROR at line 1: ORA-08189: cannot flashback the table because row movement is not enabled SQL> alter table hr.employees enable row movement; Table altered. SQL> flashback table hr.employees to timestamp sysdate-1/24; Flashback complete. SQL> select hire_date from hr.employees where employee_id=100; HIRE_DATE --------- 17-JUN-03 |
So yes, that works. The caveat is still that you need to retain enough data in the undo tablespace to rebuild the rows in their previous state.
—
Ludo