
 The answer is YES.
The answer is YES.
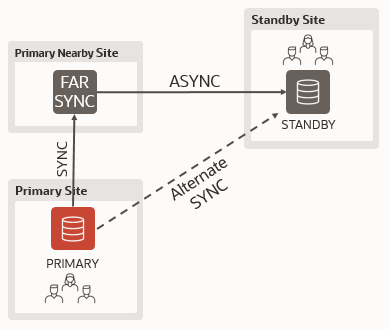
In the following configuration, cdgsima_lhr1pq (primary) sends synchronously to cdgsima_farsync1 (far sync), which forwards the redo stream asynchronously to cdgsima_lhr1bm (physical standby):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
DGMGRL> show configuration verbose Configuration - cdgsima Protection Mode: MaxPerformance Members: cdgsima_lhr1pq - Primary database cdgsima_farsync1 - Far sync instance cdgsima_lhr1bm - Physical standby database cdgsima_lhr1bm - Physical standby database (alternate of cdgsima_farsync1) Members Not Receiving Redo: cdgsima_farsync2 - Far sync instance |
But if cdgsima_farsync1 is not available, I want the primary to send synchronously to the physical standby database. I accept a performance penalty, but I do not want to compromise my data protection.
I just need to set up the Redoroutes as follows:
|
1 2 3 4 5 6 7 |
-- when primary is cdgsima_lhr1pq EDIT DATABASE 'cdgsima_lhr1pq' SET PROPERTY 'RedoRoutes' = '(LOCAL : (cdgsima_farsync1 SYNC PRIORITY=1, cdgsima_lhr1bm SYNC PRIORITY=2 ))'; EDIT FAR_SYNC 'cdgsima_farsync1' SET PROPERTY 'RedoRoutes' = '(cdgsima_lhr1pq : cdgsima_lhr1bm ASYNC)'; -- when primary is cdgsima_lhr1bm EDIT DATABASE 'cdgsima_lhr1bm' SET PROPERTY 'RedoRoutes' = '(LOCAL : (cdgsima_farsync2 SYNC PRIORITY=1, cdgsima_lhr1pq SYNC PRIORITY=2 ))'; EDIT FAR_SYNC 'cdgsima_farsync2' SET PROPERTY 'RedoRoutes' = '(cdgsima_lhr1bm : cdgsima_lhr1pq ASYNC)'; |
This is defined the second part of the RedoRoutes rules:
|
1 |
cdgsima_lhr1bm SYNC PRIORITY=2 |
Let’s test. If I shutdown abort the farsync instance:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
$ rlwrap sqlplus / as sysdba SQL*Plus: Release 19.0.0.0.0 - Production on Sat Mar 26 10:55:31 2022 Version 19.13.0.0.0 Copyright (c) 1982, 2021, Oracle. All rights reserved. Connected to: Oracle Database 19c EE Extreme Perf Release 19.0.0.0.0 - Production Version 19.13.0.0.0 SQL> shutdown abort ORACLE instance shut down. SQL> |
I can see the new SYNC destination being open almost instantaneously (because the old destination fails immediately with ORA-03113):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
2022-03-26T10:55:35.581460+00:00 LGWR (PID:42101): Attempting LAD:2 network reconnect (3113) LGWR (PID:42101): LAD:2 network reconnect abandoned 2022-03-26T10:55:35.602542+00:00 Errors in file /u01/app/oracle/diag/rdbms/cdgsima_lhr1pq/cdgsima/trace/cdgsima_lgwr_42101.trc: ORA-03113: end-of-file on communication channel LGWR (PID:42101): Error 3113 for LNO:3 to 'dgsima1.dbdgsima.misclabs.oraclevcn.com:1521/cdgsima_farsync1.dbdgsima.misclabs.oraclevcn.com' 2022-03-26T10:55:35.608691+00:00 LGWR (PID:42101): LAD:2 is UNSYNCHRONIZED 2022-03-26T10:55:36.610098+00:00 LGWR (PID:42101): Failed to archive LNO:3 T-1.S-141, error=3113 LGWR (PID:42101): Error 1041 disconnecting from LAD:2 standby host 'dgsima1.dbdgsima.misclabs.oraclevcn.com:1521/cdgsima_farsync1.dbdgsima.misclabs.oraclevcn.com' 2022-03-26T10:55:37.143448+00:00 LGWR (PID:42101): LAD:3 is UNSYNCHRONIZED 2022-03-26T10:55:37.143569+00:00 LGWR (PID:42101): LAD:2 no longer supports SYNCHRONIZATION Starting background process NSS3 2022-03-26T10:55:37.227954+00:00 NSS3 started with pid=38, OS id=78251 2022-03-26T10:55:40.733905+00:00 Thread 1 advanced to log sequence 142 (LGWR switch), current SCN: 8068734 Current log# 1 seq# 142 mem# 0: /u03/app/oracle/redo/CDGSIMA_LHR1PQ/onlinelog/o1_mf_1_k251hfvk_.log 2022-03-26T10:55:40.781499+00:00 ARC0 (PID:42266): Archived Log entry 220 added for T-1.S-141 ID 0x9eb046ef LAD:1 2022-03-26T10:55:41.606175+00:00 ALTER SYSTEM SET log_archive_dest_state_3='ENABLE' SCOPE=MEMORY SID='*'; 2022-03-26T10:55:43.747483+00:00 LGWR (PID:42101): LAD:3 is SYNCHRONIZED 2022-03-26T10:55:43.816978+00:00 Thread 1 advanced to log sequence 143 (LGWR switch), current SCN: 8068743 Current log# 2 seq# 143 mem# 0: /u03/app/oracle/redo/CDGSIMA_LHR1PQ/onlinelog/o1_mf_2_k251hfwz_.log |
Indeed, I can see the new NSS process (synchronous redo transport) spawn at that time:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
SQL> r 1 select NAME 2 ,PID 3 ,TYPE 4 ,ROLE ACTION 5 ,CLIENT_PID 6 ,CLIENT_ROLE 7 ,GROUP# 8 ,RESETLOG_ID 9 ,THREAD# 10 ,SEQUENCE# 11 ,BLOCK# 12* from v$dataguard_process where name like 'NSS%' NAME PID TYP ACTION CLIENT_PID CLIENT_ROLE GROUP# RESETLOG_ID THREAD# SEQUENCE# BLOCK# ----- ------------------------ --- ------------------------ ---------- ---------------- ---------- ----------- ---------- ---------- ---------- NSS2 54961 KSB sync 0 none 0 0 0 0 0 NSS3 78251 KSB sync 0 none 0 0 0 0 0 SQL> !ps -eaf | grep ora_nss oracle 54961 1 0 Mar10 ? 00:00:55 ora_nss2_cdgsima oracle 78251 1 0 10:55 ? 00:00:00 ora_nss3_cdgsima |
—
Ludo
Latest posts by Ludovico (see all)
- Data Guard 26ai – #28: Fast-Start Failover Validation - April 17, 2026
- Data Guard 26ai – #27: Enhanced Observer Diagnostics - April 16, 2026
- Data Guard 26ai – #26: Fast-Start Failover Lag Histogram - April 7, 2026
Hi
If there are two physical standby databases how shipping is prioritized between standby databases? By the way , data broker is not configured.
Hi Zulal,
Assuming you have Pri, Sb1, Sb2 as Primary and two standby databases.
In general, there is no priority.
You can have several combinations:
Both direct and sync:
Pri -> Sb1 (SYNC)
Pri -> Sb2 (SYNC)
In this case: both destinations are SYNC and the respective NSS process send the info in parallel. The commit is not returned to the used until the ACK is received from both destinations (unless a timeouts occurs)
Both direct and Async:
Pri -> Sb1 (ASYNC)
Pri -> Sb2 (ASYNC)
In this case: both destinations are ASYNC and one TT process send the info to all destinations in parallel. The commit is returned as soon as it’s written to the ORLs.
Both direct, one ASYNC and the other SYNC:
Pri -> Sb1 (SYNC)
Pri -> Sb2 (ASYNC)
In this case the SYNC one “has the priority” as it’s a sync destination.
Cascaded standby:
Pri -> Sb1 (SYNC or ASYNC)
Sb1 -> Sb2 (ASYNC)
In this case the direct standby “has the priority” as it’s the only one receiving directly from the primary.
HTH