A month ago, I saw this article published on the AWS architecture blog:
Disaster Recovery for Oracle Database on Amazon EC2 with Fast-Start Failover
I love seeing people suggesting Oracle Data Guard Fast-Start Failover for high availability. Nevertheless, there are a few problems with the architecture and steps proposed in the article.
I sent my comments via Disqus on the AWS blogging platform, but after a month, my comment was rejected, and the blog content hasn’t changed.
For this reason, I don’t have other places to post my comment but here…
- The link to the setup procedure is from 2009.
We have official documentation that we keep up to date. The Fast-Start Failover part:
https://docs.oracle.com/en/database/oracle/oracle-database/19/dgbkr/using-data-guard-broker-to-manage-switchovers-failovers.html#GUID-D26D79F2-0093-4C0E-98CD-224A5C8CBFA4
and the Best Practices guide:
https://docs.oracle.com/en/database/oracle/oracle-database/19/haovw/oracle-data-guard-best-practices.html#GUID-C3A78B07-6584-4380-8D53-E5B831A5894C - The part about cascading standbys references a step-by-step guide from an external blog written many years ago for 11gR2.
- The DBMS_SERVICE doc is from 12cR1, while other links are from 21c doc or 19c doc. As of today, most implement 19c. That’s probably the version to use.
https://docs.oracle.com/en/database/oracle/oracle-database/19/arpls/DBMS_SERVICE.html#GUID-C11449DC-EEDE-4BB8-9D2C-0A45198C1928 - The steps used to create the database service do not include any HA property, which will make most efforts useless. (see Table 153-6 in the link above).
- The article talks about TAF, but no steps exist to configure it. We don’t recommend TAF since 12c anyway. Today (19c), the recommendation is TAC (Transparent Application Continuity).
https://www.oracle.com/docs/tech/application-checklist-for-continuous-availability-for-maa.pdf - But, most important, TAF (or Oracle connectivity in general) does NOT require a host IP change! There is no need to change the DNS when using the recommended connection string with multiple address_lists.
- Some RedoRoutes examples are not correct. In this video I explain how they work and how to set them up:
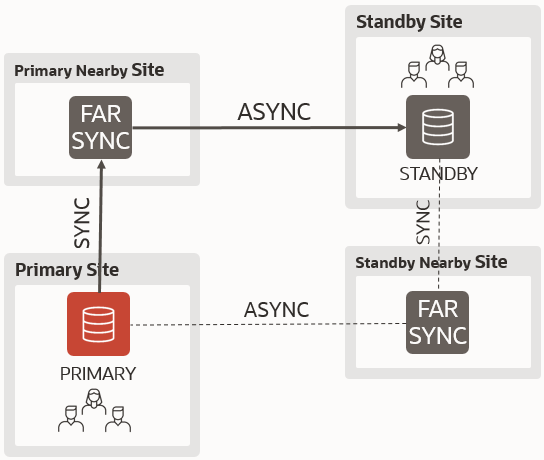
https://www.youtube.com/watch?v=huG8JPu_s4Q - The diagram shows the master observer together with the standby database, which is a bad practice. I explain why and how here:
https://www.youtube.com/watch?v=e81UPLfnLi0
The central message is:
If you need to implement a complex architecture using a software solution, pay attention that the practices suggested by the partner/integrator/3rd party match the ones from the software vendor. In the case of Oracle Data Guard, Oracle knows better 😉
Cheers
—
Ludovico