FPP was still young and lacking many features at that time, but it already changed the way I’ve worked during the next years. I embraced the out of place patching, developed some basic scripts to install Oracle Homes, and sought automation and standardization at all costs:
And discovered that meanwhile, FPP did giant steps, with many new features and fixes for quite a few usability and performance problems.
Last year, when joining the Oracle Database High Availability (HA), Scalability, and Maximum Availability Architecture (MAA) Product Management Team at Oracle, I took (among others) the Product Manager role for FPP.
Becoming an Oracle employee after 20 years of working with Oracle technology is a big leap. It allows me to understand how big the company is, and how collaborative and friendly the Oracle employees are (Yes, I was used to marketing nonsense, insisting salesmen, and unfriendly license auditors. This is slowly changing with Oracle embracing the Cloud, but it is still a fresh wound for many customers. Expect this to change even more! Regarding me… I’ll be the same I’ve always been 🙂 ).
Now I have daily meetings with big customers (bigger than the ones I have ever had in the past), development teams, other product managers, Oracle consultants, and community experts. My primary goal is to make the product better, increasing its adoption, and helping customers having the best experience with it. This includes testing the product myself, writing specs, presentations, videos, collecting feedback from the customers, tracking bugs, and manage escalations.
I am a Product Manager for other products as well, but I have to admit that FPP is the product that takes most of my Product Manager time. Why?
I will give a few reasons in my next blog post(s).
That explains how Dell migrated its many RAC clusters from SuSE to OEL. The problem is that they used a different strategy:
– backup the configuration of the nodes
– then for each node, one at time
– stop the node
– reinstall the OS
– restore the configuration and the Oracle binaries
– relink
– restart
What I want to achieve instead is:
– add one OEL node to the SuSE cluster as new node
– remove one SuSE node from the now-mixed cluster
– install/restore/relink the RDBMS software (RAC) on the new node
– move the RAC instances to the new node (taking care to NOT run more than the number of licensed nodes/CPUs at any time)
– repeat (for the remaining nodes)
because the customer will also migrate to new hardware.
In order to test this migration path, I’ve set up a SINGLE NODE cluster (if it works for one node, it will for two or more).
All nodes have same"search"order defined infile"/etc/resolv.conf"
PRVF-5636:The DNS response timeforan unreachable node exceeded"15000"ms on following nodes:sles01,rhel01
Check forintegrity of file"/etc/resolv.conf"failed
Checking integrity of name service switchconfiguration file"/etc/nsswitch.conf"...
Check forintegrity of name service switchconfiguration file"/etc/nsswitch.conf"passed
Pre-check fornode addition was unsuccessful on all the nodes.
So the problem is not if the check succeed or not (it will not), but what fails.
Solving all the problems not related to the difference SuSE-OEL is crucial, because the addNode.sh will fail with the same errors. I need to run it using -ignorePrereqs and -ignoreSysPrereqs switches. Let’s see how it works:
Execute/u01/app/oraInventory/orainstRoot.shon the following nodes:
[rhel01]
Execute/u01/app/12.1.0/grid/root.shon the following nodes:
[rhel01]
The scripts can be executed inparallel on all the nodes.Ifthere are any policy managed databases managed by cluster,proceed with the addnode procedure without executing the root.shscript.Ensure that root.shscript isexecuted after all the policy managed databases managed by clusterware are extended tothe newnodes.
So yes, it works, but remember that it’s not a supported long-term configuration.
In my case I expect to migrate the whole cluster from SLES to OEL in one day.
NOTE: using OEL6 as new target is easy because the interface names do not change. The new OEL7 interface naming changes, if you need to migrate without cluster downtime you need to setup the new OEL7 nodes following this post: http://ask.xmodulo.com/change-network-interface-name-centos7.html
Otherwise, you need to configure a new interface name for the cluster with oifcfg.
After many years of existence, Standard Edition and Standard Edition One will no longer be part of the Oracle Database Edition portfolio.
The short history
Standard Edition has been for longtime the “stepbrother” of Enterprise Edition, with less features, no options, but cheaper than EE. I can’t remember when SE has been released. It was before 2000s, I guess.
In 2003, Oracle released 10gR1. Many new features as been released for EE only, but:
– RAC as been included as part of Standard Edition
– Standard Edition One has been released, with an even lower price and “almost” the same features of Standard Edition.
For a few years, customers had the possibility to get huge savings (but many compromises) by choosing the cheaper editions.
SE ONE: just two sockets, but with today’s 18-core processors, the possibility to run Oracle on 36 cores (or more?) for less than 12k of licenses.
SE: up to four sockets and the possibility to run on either 72 core servers or RAC composed by a total of 72 cores (max 4 nodes) for less than the price of a 4-core Enterprise Edition deployement.
In 2014, for the first time, Oracle released a new Database version (12.1.0.2) where Standard Edition and SE One were not immediately available.
For months, customers asked: “When will the Oracle 12.1.0.2 SE be available?”
Now the big announcement: SE and SE One will no longer exist. With 12.1.0.2, there’s a new Edition: Oracle Database Standard Edition 2.
– SE is replaced by SE Two that has a limitation of 2 sockets
– SE Two still has RAC feature, with a maximum of two single-socket servers.
– Customers with SE on 4 socket nodes (or clusters) will need to migrate to 2 socket nodes (or clusters)
– Customers with SE One should definitely be prepared to spend some money to upgrade to SE Two, which comes at the same price of the old Standard Edition. ($17,500 per socket).
– the smallest amount of NUP licenses when licensing per named users has been increased to 10 (it was 5 with SE and SE One).
– Each SE2 Database can run max 16 user threads (in RAC, max 8 per instance). This is limited by the database Resource Manager. It does not prevent customers from using all the cores, in case they want to deploy many databases per server.
So, finally, less scalability for the same pricetag.
This technical workshop and networking event (never forget it’s a project created several years ago thanks to an intuition of Jeremy Schneider), confirms to be one of the best, long-living projects in the Oracle Community. It certainly boosted my Community involvement up to becoming an Oracle ACE. This year I’m the coordinator of the organization of the workshop, it’s a double satisfaction and it will certainly be a lot of fun again. Did I said that it’s already full booked? I’ve already blogged about it (and about what the lucky participants will get) here.
One of my favorite presentations, I’ve presented it already at OOW14 and UKOUG Tech14, but it’s still a very new topic for most people, even the most experienced DBAs. You’ll learn how Multitenant, RAC and Data Guard work together. Expect colorful architecture schemas and a live demo! You can read more about it in this post.
Missing this great networking event is not an option! I’m organizing this session as RAC SIG board member (Thanks to the IOUG for this opportunity!). We’ll focus on Real Application Clusters role in the private cloud and infrastructure optimization. We’ll have many special guests, including Oracle RAC PM Markus Michalewicz, Oracle QoS PM Mark Scardina and Oracle ASM PM James Williams.
Can you ever miss it???
A good Trivadis representative!!
This year I’m not going to Las Vegas alone. My Trivadis colleague Markus Flechtner , one of the most expert RAC technologists I have the chance to know, will also come and present a session about RAC diagnostics:
Very recently I had to configure a customer’s RAC private interconnect from bonding to HAIP to get benefit of both NICs.
So I would like to recap here what the hypothetic steps would be if you need to do the same.
In this example I’ll switch from a single-NIC interconnect (eth1) rather than from a bond configuration, so if you are familiar with the RAC Attack! environment you can try to put everything in place on your own.
First, you need to plan the new network configuration in advance, keeping in mind that there are a couple of important restrictions:
Your interconnect interface naming must be uniform on all nodes in the cluster. The interconnect uses the interface name in its configuration and it doesn’t support different names on different hosts
You must bind the different private interconnect interfaces in different subnets (see Note: 1481481.1 – 11gR2 CSS Terminates/Node Eviction After Unplugging one Network Cable in Redundant Interconnect Environment if you need an explanation)
Implementation
The RAC Attack book uses one interface per node for the interconnect (eth1, using network 172.16.100.0)
To make things a little more complex, we’ll not use the eth1 in the new HAIP configuration, so we’ll test also the deletion of the old interface.
What you need to do is add two new interfaces (host only in your virtualbox) and configure them as eth2 and eth3, e.g. in networks 172.16.101.0 and 172.16.102.0)
check that the other nodes has received the new configuration:
Oracle PL/SQL
1
2
3
4
5
[root@collabn2bin]#./oifcfggetif
eth0192.168.78.0globalpublic
eth1172.16.100.0globalcluster_interconnect
eth2172.16.101.0globalcluster_interconnect
eth3172.16.102.0globalcluster_interconnect
Before deleting the old interface, it would be sensible to stop your cluster resources (in some cases, one of the nodes may be evicted), in any case the cluster must be restarted completely in order to get the new interfaces working.
Note: having three interfaces in a HAIP interconnect is perfectly working, HAIP works from 2 to 4 interfaces. I’m showing how to delete eth1 just for information!! 🙂
Once again this year the RAC Attack will be a pre-conference workshop at Collaborate.
Whether you’re a sysadmin, a developer or a DBA, I’m sure you will really enjoy this workshop. Why?
First, you get the opportunity to install a RAC 12c using Virtualbox on your laptop and get coached by many RAC experts, Oracle ACEs and ACE Directors, OCMs and famous bloggers and technologists.
If you’ve never installed it, it will be very challenging because you get hands on network components, shared disks, udev, DNS, Virtual Machine cloning, OS install and so on, and being super-user (root) of your own cluster!! If your a developer, you can then start developing your applications by testing the failover features of RAC and their scalability by checking for global cache wait events.
If you’re already used to RAC, this year we have not one or two, but three deals for you:
Try the semi-automated RAC installation using Vagrant: you’ll be able to have your RAC up and running in minutes and concentrate on advanced features.
Implement advanced labs such as Flex Cluster and Flex ASM or Policy Managed Databases, and discover Hub and Leaf nodes, Server Pools and other features
Ask the ninjas to show you other advanced scenarios or just discuss about other RAC related topics
Isn’t enough?
The participants that will complete at least the Linux install (very first stage of the workshop) will get an OTN-sponsored T-shirt of the event, with the very new RAC SIG Logo (the image is purely indicative, the actual design may change):
Still not enough?
We’ll have free pizza (at lunch) and beer (in the afternoon), again sponsored by the Oracle Technology Network. Can’t believe it? Look at a few images from last year’s edition:
To participate in the workshop, participants need to bring their own laptop. Recommended specification: a) any 64 bit OS that supports Oracle Virtual Box b) 8GB RAM, 45GB free HDD space, SSD recommended.
Important: it’s required to pre-download Oracle Database 12c and Oracle Grid Infrastructure 12c for Linux x86-64 from the Oracle Website http://tinyurl.com/rac12c-dl (four files: linuxamd64_12c_database_1of2.zip linuxamd64_12c_database_2of2.zip linuxamd64_12c_grid_1of2.zip linuxamd64_12c_grid_2of2.zip). Due to license restrictions it’s not be possible to distribute Oracle Sofware.
Here you can find the material related to my session at Oracle Open World 2014. I’m sorry I’m late in publishing them, but I challenge you to find spare time during Oracle Open World! It’s the busiest week of the year! (Hard Work, Hard Play)
select inst_id,con_id,name,open_mode from gv\$pdbswhere con_id!=2order by con_id,inst_id;
exit
EOF
pause"please connect to the RW service"
pause"next... dgmgrl status and validate"
clear
echos"Validate Standby database"
dgmgrl<<EOF
connect sys/racattack
show configuration;
validate database'CDBGVA';
exit
EOF
pause"next... switchover to CDBGVA"
clear
echos"Switchover to CDBGVA! (it takes a while)"
dgmgrl<<EOF
connect sys/racattack
switchover to'CDBGVA';
exit
EOF
There’s one slide describing the procedure for cloning one PDB using the standbys clause. Oracle has released a Note while I was preparing my slides (one month ago) and I wasn’t aware of it, so you may also checkout this note on MOS:
Making Use of the STANDBYS=NONE Feature with Oracle Multitenant (Doc ID 1916648.1)
This year I will have the honor to present at Collaborate14, from April 7th to 11th. First of all, many thanks to Trivadis that has kindly agreed to send me to the conference.
My session (#603): Oracle Data Guard 12c: Real-Time Cascade, Far Sync Instances and other goodies has been accepted, so if you plan to attend Collaborate, I will be glad to see you there!
My paper and presentation are ready, but I’ll wait the post-conference before publishing them. Meanwhile, you can get a little sneak peak of my live demo (I’ll cut something, somewhere, but my new SSD disk should reduce the time elapsed, I have to do it again with the new hardware to get correct timings 🙂 ). There’s no audio, since it’s supposed to be my failover demo if I’ll have problems during my session.
Part I
Part II
I’ve submitted another abstract about Policy Managed Databases, but it has been put in the waiting list, assuming that Data Guard has a lot more users and the interest in new Data Guard 12c features will be higher than PMDBs that are rarely used in production environments (and I’m sad about it, keep in touch if you want to know more about this great technology).
RAC Attack 12c!
I’ll be organizing the RAC Attack again, along with Seth Miller, Yury Velikanov and Kamran Agayev. Sharing this exciting role with an Oracle ACE and two ACE Directors makes me proud of what I’m doing, but more than this, I’m happy to repeat another exciting experience like I had at OOW13.
This Year RAC Attack will be an official pre-conference workshop. We have been contacted directly by the IOUG, and we’re making improvements. We’ll install RAC 12c and discuss about advanced topics, have a lot of fun, drink a beer together and jump a lot! 🙂
NOTE: The maximum number of database instances per cluster is 512 for Oracle 11g Release 1 and higher. An upper limit of 128 database instances per X2-2 or X3-2 database node and 256 database instances per X2-8 or X3-8 database node is recommended. The actual number of database instances per database node or cluster depends on application workload and their corresponding system resource consumption.
But how many instances are actually beeing consolidated by DBAs from all around the world?
I’ve asked it to the Twitter community
I’ve sent this tweet a couple of weeks ago and I would like to consolidate some replies into a single blog post.
who has done more than this on a single server? $ ps -eaf | grep ora_pmon | wc -l 77 #oracle#consolidation
Does this thread of tweets reply to the question? Are you planning to consolidate your Oracle environment? If you have questions about how to plan your consolidation, don’t hesitate to get in touch! 🙂
What I’ve realized by is that Policy Managed Databases are not widely used and there is a lot misunderstanding on how it works and some concerns about implementing it in production.
My current employer Trivadis (@Trivadis, make sure to call us if your database needs a health check :-)) use PMDs as best practice, so it’s worth to spend some words on it. Isn’t it?
Why Policy Managed Databases?
PMDs are an efficient way to manage and consolidate several databases and services with the least effort. They rely on Server Pools. Server pools are used to partition physically a big cluster into smaller groups of servers (Server Pool). Each pool have three main properties:
A minumim number of servers required to compose the group
A maximum number of servers
A priority that make a server pool more important than others
If the cluster loses a server, the following rules apply:
If a pool has less than min servers, a server is moved from a pool that has more than min servers, starting with the one with lowest priority.
If a pool has less than min servers and no other pools have more than min servers, the server is moved from the server with the lowest priority.
Poolss with higher priority may give servers to pools with lower priority if the min server property is honored.
This means that if a serverpool has the greatest priority, all other server pools can be reduced to satisfy the number of min servers.
Generally speaking, when creating a policy managed database (can be existent off course!) it is assigned to a server pool rather than a single server. The pool is seen as an abstract resource where you can put workload on.
Cloud computing is a model for enabling ubiquitous, convenient, on-demand network access to a shared
pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that
can be rapidly provisioned and released with minimal management effort or service provider interaction
There are some major benefits in using policy managed databases (that’s my solely opinion):
PMD instances are created/removed automatically. This means that you can add and remove nodes nodes to/from the server pools or the whole cluster, the underlying databases will be expanded or shrinked following the new topology.
Server Pools (that are the base for PMDs) allow to give different priorities to different groups of servers. This means that if correctly configured, you can loose several physical nodes without impacting your most critical applications and without reconfiguring the instances.
PMD are the base for Quality of Service management, a 11gR2 feature that does resource management cluster-wide to achieve predictable performances on critical applications/transactions. QOS is a really advanced topic so I warn you: do not use it without appropriate knowledge. Again, Trivadis has deep knowledge on it so you may want to contact us for a consulting service (and why not, perhaps I’ll try to blog about it in the future).
RAC One Node databases (RONDs?) can work beside PMDs to avoid instance proliferation for non critical applications.
Oracle is pushing it to achieve maximum flexibility for the Cloud, so it’s a trendy technology that’s cool to implement!
I’ll find some other reasons, for sure! 🙂
What changes in real-life DB administration?
Well, the concept of having a relation Server -> Instance disappears, so at the very beginning you’ll have to be prepared to something dynamic (but once configured, things don’t change often).
As Martin pointed out in his blog, you’ll need to configure server pools and think about pools of resources rather than individual configuration items.
The spfile doesn’t contain any information related to specific instances, so the parameters must be database-wide.
The oratab will contain only the dbname, not the instance name, and the dbname is present in oratab disregarding if the server belongs to a serverpool or another.
1
2
3
+ASM1:/oracle/grid/11.2.0.3:N# line added by Agent
PMU:/oracle/db/11.2.0.3:N# line added by Agent
TST:/oracle/db/11.2.0.3:N# line added by Agent
Your scripts should take care of this.
Also, when connecting to your database, you should rely on services and access your database remotely rather than trying to figure out where the instances are running. But if you really need it you can get it:
1
2
3
4
5
6
7
# srvctl status database -d PMU
Instance PMU_4 isrunning on node node2
Instance PMU_2 isrunning on node node3
Instance PMU_3 isrunning on node node4
Instance PMU_5 isrunning on node node6
Instance PMU_1 isrunning on node node7
Instance PMU_6 isrunning on node node8
An approach for the crontab: every DBA soon or late will need to schedule tasks within the crond. Since the RAC have multiple nodes, you don’t want to run the same script many times but rather choose which node will execute it.
My personal approach (every DBA has his personal preference) is to check the instance with cardinality 1 and match it with the current node. e.g.:
1
2
3
4
5
6
7
# [ `crsctl stat res ora.tst.db -k 1 | grep STATE=ONLINE | awk '{print $NF}'` == `uname -n` ]
# echo $?
0
# [ `crsctl stat res ora.tst.db -k 1 | grep STATE=ONLINE | awk '{print $NF}'` == `uname -n` ]
# echo $?
1
In the example, TST_1 is running on node1, so the first evaluation returns TRUE. The second evaluation is done after the node2, so it returns FALSE.
This trick can be used to have an identical crontab on every server and choose at the runtime if the local server is the preferred to run tasks for the specified database.
A proof of concept with Policy Managed Databases
My good colleague Jacques Kostic has given me the access to a enterprise-grade private lab so I can show you some “live operations”.
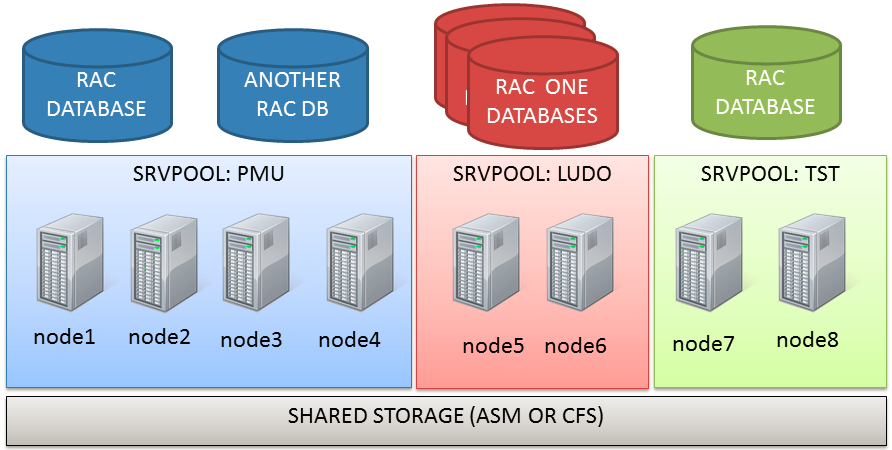
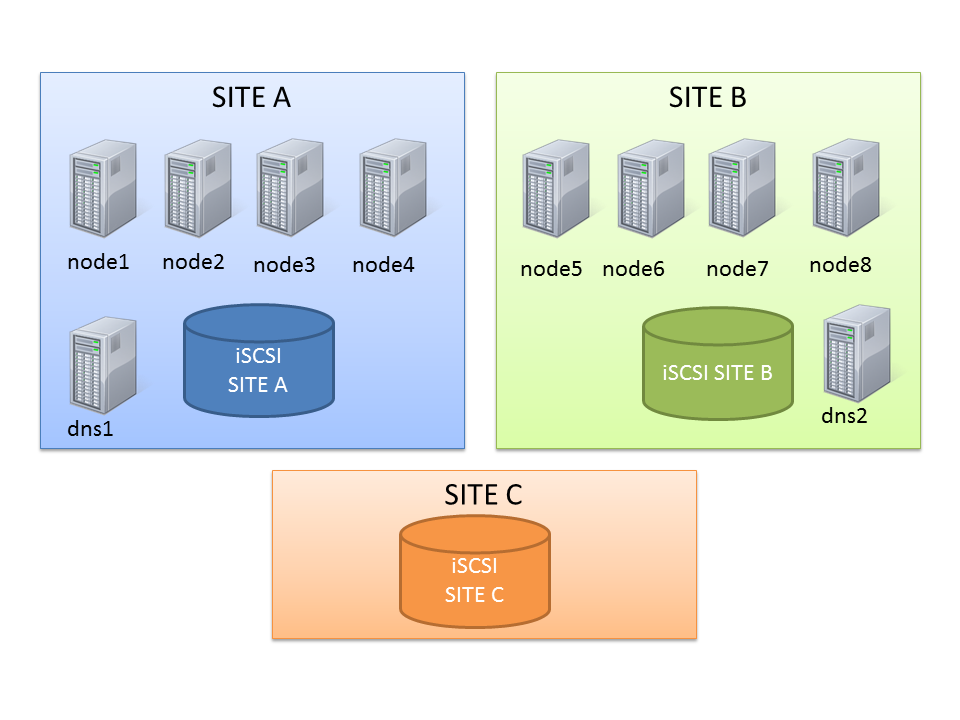
Let’s start with the actual topology: it’s an 8-node stretched RAC with ASM diskgroups with failgroups on the remote site.
This should be enough to show you some capabilities of server pools.
The Generic and Free server pools
After a clean installation, you’ll end up with two default server pools:
The Generic one will contain all non-PMDs (if you use only PMDs it will be empty). The Free one will own servers that are “spare”, when all server pools have reached the maximum size thus they’re not requiring more servers.
New server pools
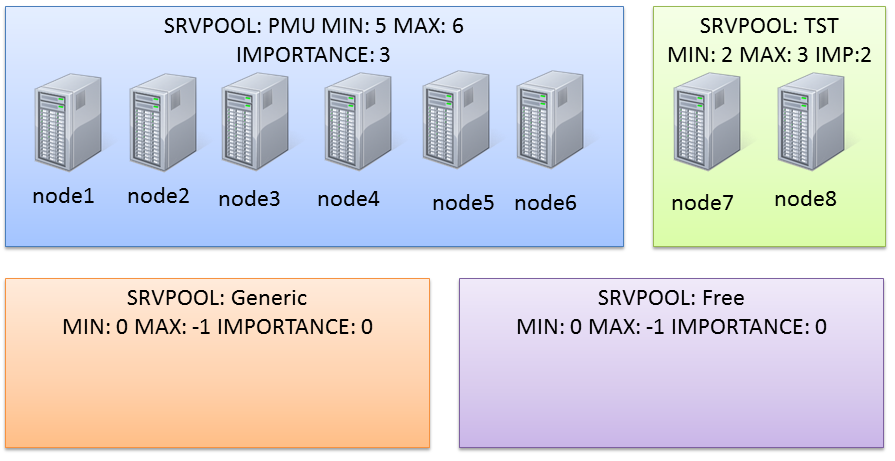
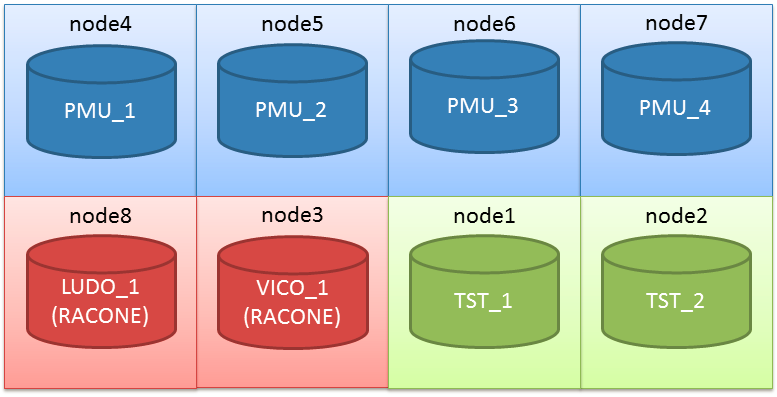
Actually the cluster I’m working on has two serverpools already defined (PMU and TST):
(the node assignment in the graphic is not relevant here).
They have been created with a command like this one:
Oracle PL/SQL
1
#srvctladdserverpool-gPMU-l5-u6-i3
Oracle PL/SQL
1
#srvctladdserverpool-gTST-l2-u3-i2
“srvctl -h ” is a good starting point to have a quick reference of the syntax.
You can check the status with:
1
2
3
4
5
6
7
8
9
# srvctl status serverpool
Server pool name:Free
Active servers count:0
Server pool name:Generic
Active servers count:0
Server pool name:PMU
Active servers count:6
Server pool name:TST
Active servers count:2
and the configuration:
1
2
3
4
5
6
7
8
9
10
11
12
13
# srvctl config serverpool
Server pool name:Free
Importance:0,Min:0,Max:-1
Candidate server names:
Server pool name:Generic
Importance:0,Min:0,Max:-1
Candidate server names:
Server pool name:PMU
Importance:3,Min:5,Max:6
Candidate server names:
Server pool name:TST
Importance:2,Min:2,Max:3
Candidate server names:
Modifying the configuration of serverpools
In this scenario, PMU is too big. The sum of minumum nodes is 2+5=7 nodes, so I have only one server that can be used for another server pool without falling below the minimum number of nodes.
I want to make some room to make another server pool composed of two or three nodes, so I reduce the serverpool PMU:
1
# srvctl modify serverpool -g PMU -l 3
Notice that PMU maxsize is still 6, so I don’t have free servers yet.
Oracle PL/SQL
1
2
3
4
5
6
7
#srvctlstatusdatabase-dPMU
InstancePMU_4isrunningonnodenode2
InstancePMU_2isrunningonnodenode3
InstancePMU_3isrunningonnodenode4
InstancePMU_5isrunningonnodenode6
InstancePMU_1isrunningonnodenode7
InstancePMU_6isrunningonnodenode8
So, if I try to create another serverpool I’m warned that some resources can be taken offline:
1
2
3
4
5
6
# srvctl add serverpool -g LUDO -l 2 -u 3 -i 1
PRCS-1009:Failed tocreate server pool LUDO
PRCR-1071:Failed toregister orupdate server pool ora.LUDO
CRS-2737:Unable toregister server pool'ora.LUDO'asthiswill affect running resources,but the force option was notspecified
The clusterware proposes to stop 2 instances from the db pmu on the serverpool PMU because it can reduce from 6 to 3, but I have to confirm the operation with the flag -f.
Modifying the serverpool layout can take time if resources have to be started/stopped.
1
2
3
4
5
6
7
8
9
10
11
# srvctl status serverpool
Server pool name:Free
Active servers count:0
Server pool name:Generic
Active servers count:0
Server pool name:LUDO
Active servers count:2
Server pool name:PMU
Active servers count:4
Server pool name:TST
Active servers count:2
My new serverpool is finally composed by two nodes only, because I’ve set an importance of 1 (PMU wins as it has an importance of 3).
Inviting RAC One Node databases to the party
Now that I have some room on my new serverpool, I can start creating new databases.
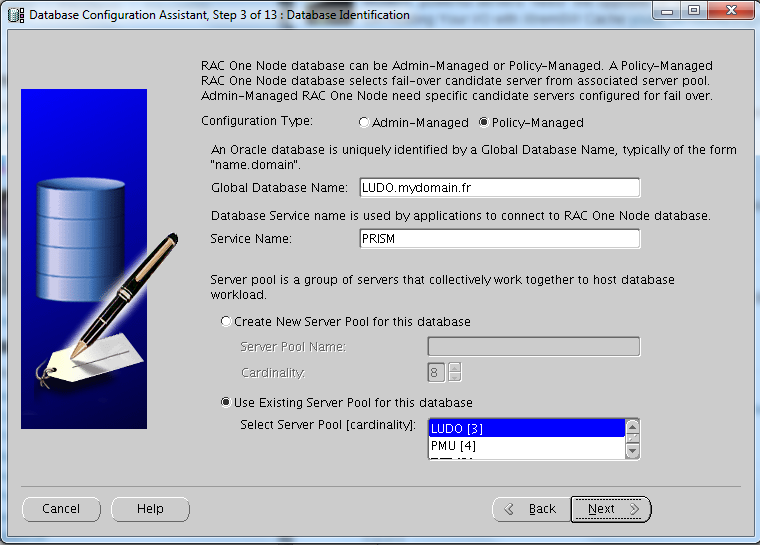
With PMD I can add two types of databases: RAC or RACONDENODE. Depending on the choice, I’ll have a database running on ALL NODES OF THE SERVER POOL or on ONE NODE ONLY. This is a kind of limitation in my opinion, hope Oracle will improve it in the near future: would be great to specify the cardinality also at database level.
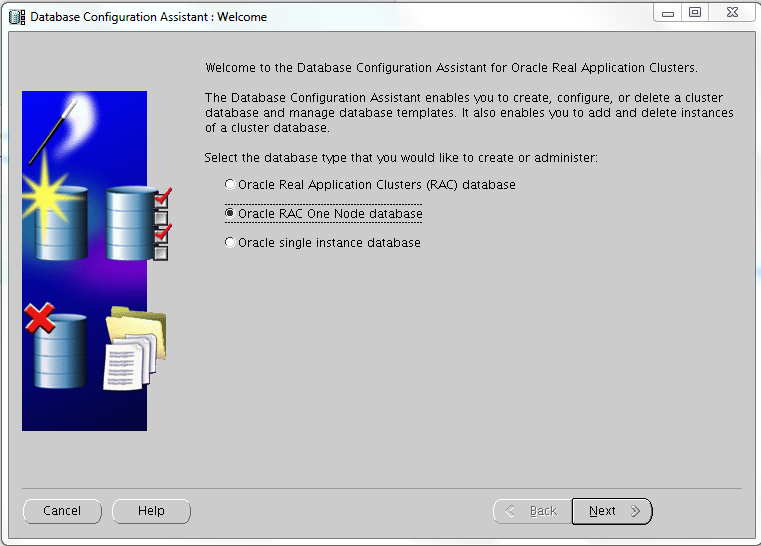
Creating a RAC One DB is as simple as selecting two radio box during in the dbca “standard” procedure:
The Server Pool can be created or you can specify an existent one (as in this lab):
The node was belonging to the pool LUDO, however I have this situation right after:
1
2
3
4
5
6
7
8
9
10
11
# srvctl status serverpool
Server pool name:Free
Active servers count:0
Server pool name:Generic
Active servers count:0
Server pool name:LUDO
Active servers count:2
Server pool name:PMU
Active servers count:3
Server pool name:TST
Active servers count:2
A server has been taken from the pol PMU and given to the pool LUDO. This is because PMU was having one more server than his minimum server requirement.
Now I can loose one node at time, I’ll have the following situation:
1 node lost: PMU 3, TST 2, LUDO 2
2 nodes lost: PMU 3, TST 2, LUDO 1 (as PMU is already on min and has higher priority, LUDO is penalized because has the lowest priority)
3 nodes lost:PMU 3, TST 2, LUDO 0 (as LUDO has the lowest priority)
4 nodes lost: PMU 3, TST 1, LUDO 0
5 nodes lost: PMU 3, TST 0, LUDO 0
So, my hyper-super-critical application will still have three nodes to have plenty of resources to run even with a multiple physical failure, as it is the server pool with the highest priority and a minimum required server number of 3.
What I would ask to Santa if I’ll be on the Nice List (ad if Santa works at Redwood Shores)
Dear Santa, I would like:
To create databases with node cardinality, to have for example 2 instances in a 3 nodes server pool
Server Pools that are aware of the physical location when I use stretched clusters, so I could end up always with “at least one active instance per site”.
Think about it 😉
—
Ludovico
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.Accept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.