NOTE: The maximum number of database instances per cluster is 512 for Oracle 11g Release 1 and higher. An upper limit of 128 database instances per X2-2 or X3-2 database node and 256 database instances per X2-8 or X3-8 database node is recommended. The actual number of database instances per database node or cluster depends on application workload and their corresponding system resource consumption.
But how many instances are actually beeing consolidated by DBAs from all around the world?
I’ve asked it to the Twitter community
I’ve sent this tweet a couple of weeks ago and I would like to consolidate some replies into a single blog post.
who has done more than this on a single server? $ ps -eaf | grep ora_pmon | wc -l 77 #oracle#consolidation
Does this thread of tweets reply to the question? Are you planning to consolidate your Oracle environment? If you have questions about how to plan your consolidation, don’t hesitate to get in touch! 🙂
In my previous post I’ve talked about some news from the Open World. Now it’s time to talk about MY week and why I’ve loved it…
It’s all about community involvement
The most exciting thing about the OOW is the possibility to interact with great people, bloggers, speakers, experts, and now I can also say friends. In the last decade, I’ve worked hard for customers and dealt with almost all the problems and architectures that an Oracle DBA can face, but I’ve always done few efforts for the community, sometimes because I was having no time, sometimes because I was perceiving it as time-expensive and gainless. I was wrong. It’s time-consuming, yes, but it lets me feel richer.
The first good news
When I’ve landed in the USA, the first mail I’ve read was the following:
Congratulations Bjoern. Bobby, Gokhan and Ludovico on being elected as RAC SIG Office bearers!!!
Vice President: Bjoern Rost
US Conference Events Chair: Bobby Curtis
Website Chair : Gokhan Atil
Regional Chair Europe: Ludovico Cadara
We look forward for you all to take us to the next level. I will include you on our board member email group.
Congratulations again!!
K.P.Singh
Current President, RAC SIG
We’ve made an official announcement on twitter recently:
So I’ve attended my first RAC SIG meeting at OOW13 at the OTN lounge.
RAC SIG meeting at OOW13
Now I’m weekly (or even daily) in contact with the board by e-mail, tomorrow we’ll have a conf-call to put the bases to work on for the next year. Wish us good luck! 🙂
RAC Attack 12c
Well, I’ve talked about the RAC ATTACK in my previous posts. The event has been a success, we’ve had many attendants, curious people and friends coming to do the lab or get in touch. It has been a great opportunity to collaborate with (and be praised by) several community experts including Oracle ACEs and ACE directors:
The Ninjas:
Seth Miller (@Seth_M_Miller)
Bjoern Rost (@brost)
Yury Velikanov (@yvelik)
Leighton Nelson (@leight0nn)
Bertrand Drouvot (@BertrandDrouvot)
Kamran Agayev (@KamranAgayev)
Martin Nash (@mpnsh)
Maaz Anjum (@maaz_anjum)
Hans Forbrich (@HansForbric)
Tim Hall (@oraclebase)
Ludovico Caldara (@ludovicocaldara) that’s me! 🙂
Other contributors and great people that worked on the project:
Laura Ramsey (@OracleDBDev)
Jeremy Schneider (@jer_s)
Osama Mustafa (@OsamaOracle)
Bobby Curtis (@dbasolved)
Alex Gorbachev (@alexgorbachev)
Also note that the RAC Attack will be present at the UKOUG Tech 2013 and RMOUG 2014, so don’t miss it if you plan to attend these conferences.
The Blogger Meetup
This meeting, organized by Pythian and OTN, allows to meet the most famous and active bloggers in the Oracle Community. This GREAT VIDEO from Björn Rost should give you an idea (I appear at 19”):
Here’s another one, always from Björn:
The Swim in the bay
Literally, a meetup of crazy guys willing to freeze themselves in the bay the early morning!
Chet Justice has organized this and he managed to get sponsorship for swim-caps and T-shirts 🙂 I’m the third from the left, you may recognize many famous people here 🙂
Now I’m part of a community, I’m involved, I learn from others and I let others to learn from me… where applicable! 🙂 Interacting with people from all around the world let me feel stronger and more open to new challenges. And I know that if I have a dream is up to me to chase it and make it come true.
PS: This is an incomplete list of the people I’ve met (other than the RAC Attack contributors).
Make sure to follow them!
Vit Spinka (@vitspinka)
Vanessa Simmons (@pythiansimmons)
Riyaj Shamsudeen (@riyajshamsudeen)
Øyvind Isene (@OyvindIsene)
Carlos Sierra (@csierra_usa)
Gregory Guillou (@ArKZoYd)
Heli Helskyaho (@HeliFromFinland)
Marc Fielding (@mfild)
Jonathan Lewis (@JLOracle)
Fuad Arshad (@fuadar)
Chet Justice (@oraclenerd)
Tim Gorman (@timothyjgorman)
Mark W. Farnham (@pudge1954)
Kerry Osborne (@KerryOracleGuy)
Arjen Visser (@dbvisit)
Kyle Hailey (@kylehhailey)
Steve Karam (@OracleAlchemist)
Eric Grancher (@EricGrancher)
Arup Nanda (@arupnanda)
Kent Graziano (@KentGraziano)
Andrey Goryunov (@goryunov)
James Morle (@JamesMorle)
Christo Kutrovsky (@kutrovsky)
Brian Fitzgerald (@ExaGridDba)
Kellyn Pot’Vin (@DBAKevlar)
Karl Arao (@karlarao)
Jason Arneil (@jarneil)
Gustavo Rene Antunez (@grantunez)
Frits Hoogland (@fritshoogland)
Luca Canali (@LucaCanaliDB)
Chris Buckel (@flashdba)
Cary Millsap (@CaryMillsap)
Paul Vallee (@paulvallee)
Tanel Poder (@TanelPoder)
Connor McDonald (@connor_mc_d)
Gwen (Chen) Shapira (@gwenshap)
Christian Antognini (@ChrisAntognini)
Mauro Pagano (@Mautro)
Jérôme Françoisse (@JeromeFr)
Ittichai (@ittichai)
Jeff Smith (@thatjeffsmith)
Michelle Malcher (@malcherm)
Debra Lilley (@debralilley)
Doug Burns (@orcldoug)
I’m back at work now, safely, after the week in San Francisco.
It’s time to sit down, and try to pull out some thought about what I’ve experienced and done.
I’ll start from the new announcements, what is most important for most people, and leave my personal experience for my next post.
In-memory Database Option
Oracle has announced the In-Memory option for the Oracle Database. This feature will store the data simultaneously in traditional row-based and into a new in-memory columnar format, to serve optimally both analytics and OLTP workloads AT THE SAME TIME. Because column-based storage is redundant, it will work without logging mechanism, so the overhead will be minimal. The marketing message claims “ungodly speed”: 100x faster queries for analytics and 2x faster queries in OLTP environments.
By separating Analytics and OLTP with different storage formats, the indexes on the row-based version of the table can be reduced to make the transactions faster, getting the rid of the analytical indexes thank to the columnar format that is already optimized for that kind of workload. The activation of the option will be transparent to the applications.
How it will be activated?
Oracle PL/SQL
1
2
3
inmemory_size=XXXGB
altertablefoo...inmemory;
Now my considerations:
[evil] Will this option make your database faster than putting it on an actual Exadata?
It will be an option, so it will cost extra-money on top of the Enterprise Edition
[I guess] it will be released with 12cR2 because a such big change cannot be introduced simply with a patch set. So I think we’ll not see it before the end of 2014
And, uh, Maria Colgan has given up the Product Management of the Cost Based Optimizer to become the Product Manager of the In-Memory option. Tom Kyte will take the ownership of the CBO.
M6-32 Big Memory Machine
I’ve paid much less attention for this new announcement. The new big super hyper machine engineered by Oracle will have:
1024 DIMMS
32TB of DRAM
12 cores per processors
96 threads per processor
This huge memory machine can be connected through InfiniBand to an Exadata to rely on its storage cells.
But it will cost 3M$, so it’s not really intended for SMBs or for the average DBA, that’s why I don’t care too much about it…
Only 8 minutes in the keynote to introduce this appliance that is really hot, IMHO. This… oh my… let’s call it ODBLRA, is a backup appliance (based on the same HW of Exadata) capable of receiving the stream of redo logging over SQL*Net, the same way as it’s done with DataGuard, except that instead of having a standby database, you’ll have an appliance capable of storing all the redo stream of your entire DB farm and have a real-time backup of your transactions. That’s it: no transactions lost between two backup archives and no need to have hundreds of DataGuard setups or network filesystems as secondary destinations in order to make your redo stream safer.
I guess that it will host an engine RMAN-aware that can create incremental-updated backups, so that you can almost forget about full backups. You can leverage an existent tape infrastructure to offload the appliance if it starts getting full.
Your ODBLRA can also replicate your backups to an another appliance hosted on the Oracle Cloud: ODBLRAaaS! 🙂
To conclude, Oracle is pushing for bigger, dedicated, specialized SPARC machines instead of relying on commodity hardware…
Oracle Multi-tenant Self-Service Provisioning
There’s a new APEX application, now in BETA, that can be downloaded from the Oracle Multitenant Page that provides self-service provisioning of databases in a Multitenant architecture. It’s worth a try… if you plan to introduce the Multitenant option in your environment!
All products in the Cloud
Oracle now offers (as a preview) its Database, Middleware and Applications as a Service, in its public cloud. For a DBA can be of interest:
The Storage aaS, use Java & REST API (Openstack SWIFT) for block level access to the storage.
The Computing aaS allows you to scale the computing power to follow your computing needs.
The Database aaS is the standard, full-featured Oracle Database (in the cloud!) 11gR2 or 12c in all editions (SE, SE1, EE). You can choose five different sizes, up to 17cores and 256Gb of RAM, and choose 3 different formulas:
Single Schema (3 sizes: 5, 20 or 50Gb, with prices from 175$/month to 2000$/month)
Basic Database (user-managed, single-instance preconfigured databases only with a local EM)
Managed Database (single-instance with managed backups & PITR, managed quarterly apply of critical parches)
Premium Managed Database (fully managed RAC, with optional DG or Active DG, PDB and upgrades)
My considerations:
Oracle releases this cloud offering with significant delay comparing to his competitors
It’s still in preview and there’s no information about the billing schema. Depending on that, it can be more or less attractive.
As for other cloud services, the performance will be acceptable only when putting all the stack into the same cloud (WebLogic, DB, etc.)
Oracle on Azure
Microsoft starts offering preconfigured Oracle platforms, Database and WebLogic, on Azure on both Linux and Windows systems. I haven’t seen the price list yet, but IMHO Azure has been around since longtime now, and it appears as a reliable and settled alternative comparing to Oracle Cloud. Nice move Microsoft, I think it deserves special attention.
One of the new features of Oracle 12c is the new is the MySQL C API implementation for Oracle, so that all applications and tools built on this API can use transparently a MySQL or an Oracle database as backend.
Oracle says that this will facilitate the migration from MySQL to Oracle, but I ask myself: Won’t be attractive for many developers to start developing applications with the MySQL API rather than with the Oracle libraries? This can potentially permit new applications to be migrated quickly in the opposite direction… (Oracle -> MySQL).
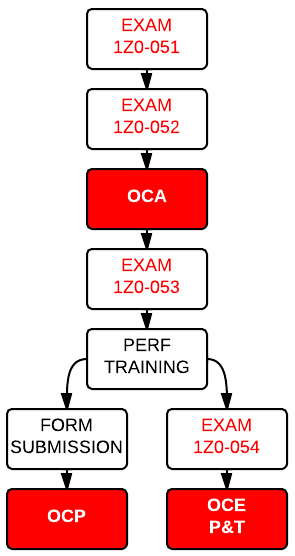
I’ve decided to write about how I’ve got my OCP 11g certification. Why? It’s not always clear that the step order indicated by the official Oracle Certification pages is not mandatory, and that it can be changed to better fit your needs.
What the Certification pages states
According to the page, you should go through the steps in the following order:
Pass the exams 1Z0-051 and 1Z0-052 to get the OCA
Complete an approved course
Pass the 1Z0-053 exam
Complete the course submission form
Get the OCP certification
What you can do
Actually, you can go through the steps in any order, and get your result when all the required steps have been completed
My goal was to achieve the OCP certification first and then get the OCE Performance and Tuning. Since I was longtime and largely prepared for the OCP, I’ve decided to change my path as follows:
Pass the exams 1Z0-051 and 1Z0-052 to get the OCA
Pass the exams 1Z0-053
Get the training on Perf&Tuning (Training On Demand also works, and the course counts toward the OCP since it is included in the list of courses available for the OCM).
Concurrently, I’ve submitted by form for the OCP and passed the exam 1Z0-054 for the OCE, achieving 2 certifications in few days.
By doing it this way, I’ve been able to get the Perf&Tuning exam just after the specific training.
For any question, just contact the Oracle University, they will clarify any doubt about the possible paths.
Note: the P&T training I’ve taken is no more valid for the OCM path since I’ve already submitted it for the OCP. If you plan to do the same you’ll need TWO additional trainings in order to get the OCM.
You’re going to head at OOW this year. Your count down has started and you feel excited about that.
Have you planned carefully your AGENDA? If you’re a RAC geek and you’re not going to attend #RACAttack, the answer is NO!! 🙂 This year the RAC Attack we’ll be mentored by real Ninjas, just come along to be part of them!
Reserve from one to three slots on your agenda and go to the OTN Lounge (@ the lobby of Moscone South)
Launch RAC Attack at OOW 2013 (NINJAS Presentation) On Sunday, from 4PM to 6PM, the OTN will open his lounge. At 4:45PM our team will present himself in just 15 minutes, along with the project. OTN will provide food and drinks (that’s what I’ve heard 😉 ) so don’t miss it for any reason.
RAC Attack at OOW 2013 Day 1 On Tuesday, from 10AM to 2PM, our fearless team of Ninjas will assist you during the installation from scratch of a real RAC environment on your laptop.
RAC Attack at OOW 2013 Day 2 There will be a second slot of 4 hours, the Wednesday, from 10AM to 2PM to give you a second chance to attend (and finalize your installation, start a new one, or just have fun together and discuss about complex RAC topologies, for real RAC geeks!).
What differs this year?
The new book covers the installation of a brand new Oracle RAC in release 12c on Oracle VirtualBox. Still not enough?
Among the volunteers we’ll have 5 Oracle ACEs or ACE Directors, some Certified Masters and a great representative of the RAC SIG board. You’ll recognize us because of our bandanas… Don’t worry, we are not an elite, we’re just good DBAs eager to share our experience, ear from you, and share good time. Sounds good?
If you attend, you’ll earn a special “RAC Attack Ninja” ribbon, so you can go back to work and boast with your colleagues (and your boss!).
And why not, propose a new RAC environment at your company and get it done with a little more confidence, for what it’s worth, that’s the real objective: practice with the RAC technology and get ready for a real scenario.
Make sure that you accomplish some steps before starting your journey to OOW:
Make sure you have a recent laptop to install the full RAC stack. The new 12c is a little more demanding than the 11g, each RAC node would require 4Gb of RAM, but if you have 8Gb of RAM on your laptop we guarantee that it’s enough.
The WI-FI connection at OOW is sub-optimal for heavy downloads (I’m euphemistic), so make sure you get your own copy of the Oracle software (Grid Infrastructure and Database) by following the download instruction from: http://en.wikibooks.org/wiki/RAC_Attack_-_Oracle_Cluster_Database_at_Home/RAC_Attack_12c/Software_Components If you come without your own copy of the software, we won’t give it to you it because of legal concerns, but hopefully we’ll have some spare laptops available to allow you to complete your lab successfully. Just make sure to confirm your presence on the Facebook event page and we’ll try to do our best (but cannot guarantee a laptop for everyone!).
Give us your feedback and spread the word!
If you plan attend (good choice! :-)) , take a business card with you and get in touch with us. It’s a great networking opportunity. Take a lot of pictures, upload them on the social networks (the #RACAttack hashtag on twitter, the facebook page, the RAC SIG group on LinkedIn) and give us your feedback. Other RAC Attack events will be planned, so we can improve thank to your suggestions.
For truth’s sake, I wasn’t planning to head at Oracle Open World this year. I’ve never had this opportunity, and the same days my company is planning it’s great internal conference (Trivadis Tech Event) that I always enjoy and I hope will be made public soon.
But this summer I’ve started contributing heavily to the rewriting of the RAC Attack project, now focusing on Oracle RAC 12c.
So I’ve seized the opportunity and asked my managers to send me at OOW (with partial success). The final result is that I’m attending Oracle Open World and I’ll be glad to meet everyone of you! 🙂 I’ll also mentor the RAC Attack (Operation Ninja) event, so make sure you come at the OTN Lounge, lobby of Moscone South, Tuesday and Wednesday between 10:00AM and 2:00PM and meet the whole team of RAC experts.
My Agenda
I’m very struggled with timing conflicts between the many sessions I would like to attend. It’s a unique opportunity to meet and listen to all my favorite bloggers, technologists and tweeps, and will be a pity to miss many of their sessions.
However, I’ve ended up with this Agenda, it’s a semi-definitive one, but I reserve the right to change things the last minute, so follow me on twitter during these days.
You may notice the two huge slots I’ve reserved for the RAC Attack, and many sessions I’ll follow at the Oak Table World 2013. Most of my favorite technologists will head there.
I’ll also attend to two fitness events on Sunday and Monday, if you’re brave enough you can join us! 🙂
What I’ve realized by is that Policy Managed Databases are not widely used and there is a lot misunderstanding on how it works and some concerns about implementing it in production.
My current employer Trivadis (@Trivadis, make sure to call us if your database needs a health check :-)) use PMDs as best practice, so it’s worth to spend some words on it. Isn’t it?
Why Policy Managed Databases?
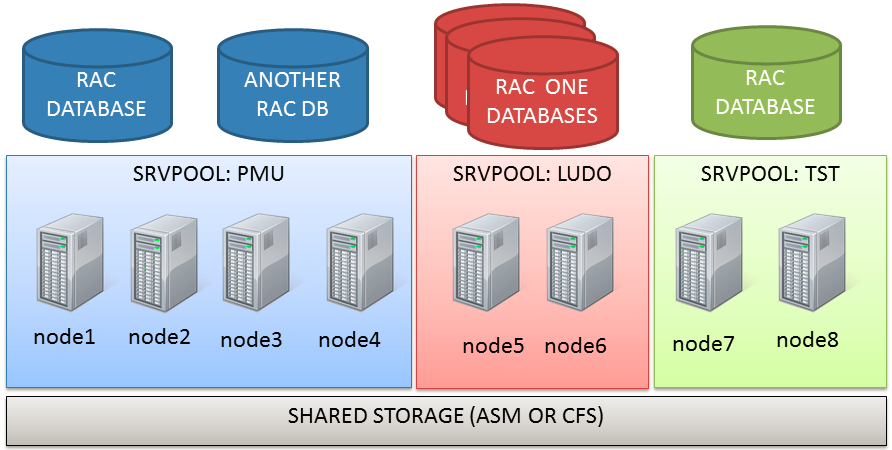
PMDs are an efficient way to manage and consolidate several databases and services with the least effort. They rely on Server Pools. Server pools are used to partition physically a big cluster into smaller groups of servers (Server Pool). Each pool have three main properties:
A minumim number of servers required to compose the group
A maximum number of servers
A priority that make a server pool more important than others
If the cluster loses a server, the following rules apply:
If a pool has less than min servers, a server is moved from a pool that has more than min servers, starting with the one with lowest priority.
If a pool has less than min servers and no other pools have more than min servers, the server is moved from the server with the lowest priority.
Poolss with higher priority may give servers to pools with lower priority if the min server property is honored.
This means that if a serverpool has the greatest priority, all other server pools can be reduced to satisfy the number of min servers.
Generally speaking, when creating a policy managed database (can be existent off course!) it is assigned to a server pool rather than a single server. The pool is seen as an abstract resource where you can put workload on.
Cloud computing is a model for enabling ubiquitous, convenient, on-demand network access to a shared
pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that
can be rapidly provisioned and released with minimal management effort or service provider interaction
There are some major benefits in using policy managed databases (that’s my solely opinion):
PMD instances are created/removed automatically. This means that you can add and remove nodes nodes to/from the server pools or the whole cluster, the underlying databases will be expanded or shrinked following the new topology.
Server Pools (that are the base for PMDs) allow to give different priorities to different groups of servers. This means that if correctly configured, you can loose several physical nodes without impacting your most critical applications and without reconfiguring the instances.
PMD are the base for Quality of Service management, a 11gR2 feature that does resource management cluster-wide to achieve predictable performances on critical applications/transactions. QOS is a really advanced topic so I warn you: do not use it without appropriate knowledge. Again, Trivadis has deep knowledge on it so you may want to contact us for a consulting service (and why not, perhaps I’ll try to blog about it in the future).
RAC One Node databases (RONDs?) can work beside PMDs to avoid instance proliferation for non critical applications.
Oracle is pushing it to achieve maximum flexibility for the Cloud, so it’s a trendy technology that’s cool to implement!
I’ll find some other reasons, for sure! 🙂
What changes in real-life DB administration?
Well, the concept of having a relation Server -> Instance disappears, so at the very beginning you’ll have to be prepared to something dynamic (but once configured, things don’t change often).
As Martin pointed out in his blog, you’ll need to configure server pools and think about pools of resources rather than individual configuration items.
The spfile doesn’t contain any information related to specific instances, so the parameters must be database-wide.
The oratab will contain only the dbname, not the instance name, and the dbname is present in oratab disregarding if the server belongs to a serverpool or another.
1
2
3
+ASM1:/oracle/grid/11.2.0.3:N# line added by Agent
PMU:/oracle/db/11.2.0.3:N# line added by Agent
TST:/oracle/db/11.2.0.3:N# line added by Agent
Your scripts should take care of this.
Also, when connecting to your database, you should rely on services and access your database remotely rather than trying to figure out where the instances are running. But if you really need it you can get it:
1
2
3
4
5
6
7
# srvctl status database -d PMU
Instance PMU_4 isrunning on node node2
Instance PMU_2 isrunning on node node3
Instance PMU_3 isrunning on node node4
Instance PMU_5 isrunning on node node6
Instance PMU_1 isrunning on node node7
Instance PMU_6 isrunning on node node8
An approach for the crontab: every DBA soon or late will need to schedule tasks within the crond. Since the RAC have multiple nodes, you don’t want to run the same script many times but rather choose which node will execute it.
My personal approach (every DBA has his personal preference) is to check the instance with cardinality 1 and match it with the current node. e.g.:
1
2
3
4
5
6
7
# [ `crsctl stat res ora.tst.db -k 1 | grep STATE=ONLINE | awk '{print $NF}'` == `uname -n` ]
# echo $?
0
# [ `crsctl stat res ora.tst.db -k 1 | grep STATE=ONLINE | awk '{print $NF}'` == `uname -n` ]
# echo $?
1
In the example, TST_1 is running on node1, so the first evaluation returns TRUE. The second evaluation is done after the node2, so it returns FALSE.
This trick can be used to have an identical crontab on every server and choose at the runtime if the local server is the preferred to run tasks for the specified database.
A proof of concept with Policy Managed Databases
My good colleague Jacques Kostic has given me the access to a enterprise-grade private lab so I can show you some “live operations”.
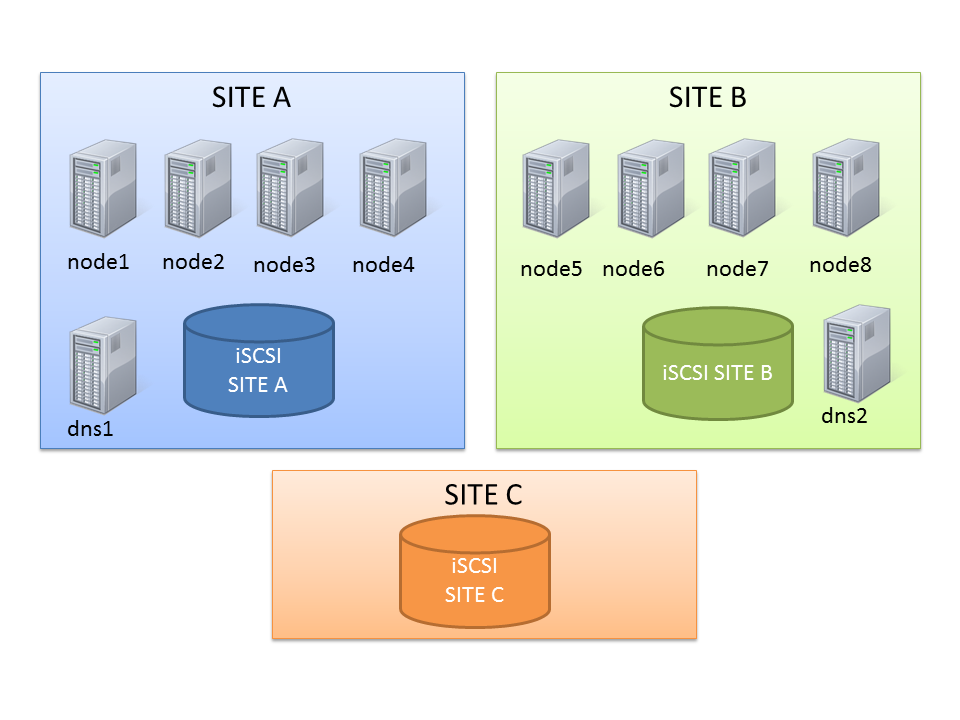
Let’s start with the actual topology: it’s an 8-node stretched RAC with ASM diskgroups with failgroups on the remote site.
This should be enough to show you some capabilities of server pools.
The Generic and Free server pools
After a clean installation, you’ll end up with two default server pools:
The Generic one will contain all non-PMDs (if you use only PMDs it will be empty). The Free one will own servers that are “spare”, when all server pools have reached the maximum size thus they’re not requiring more servers.
New server pools
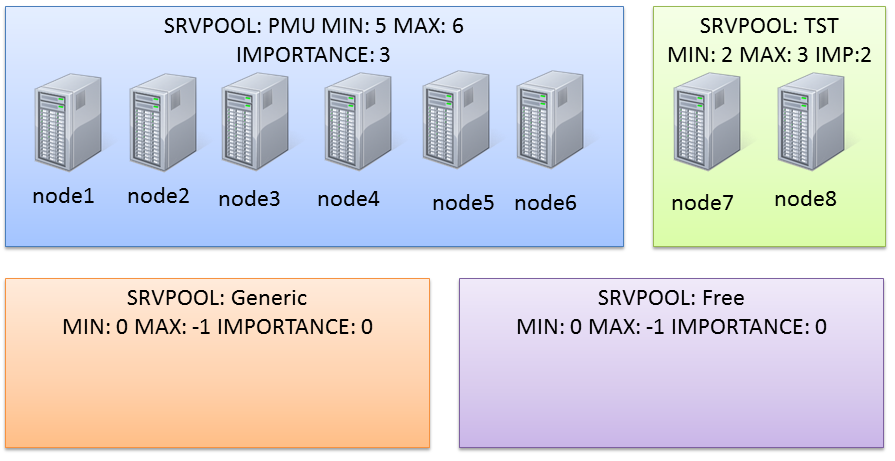
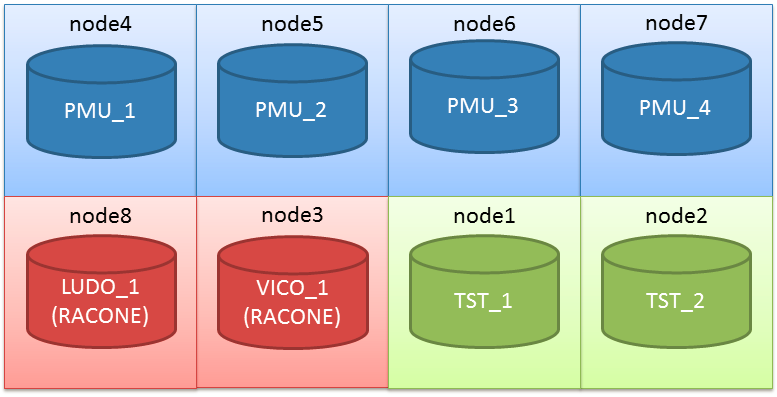
Actually the cluster I’m working on has two serverpools already defined (PMU and TST):
(the node assignment in the graphic is not relevant here).
They have been created with a command like this one:
Oracle PL/SQL
1
#srvctladdserverpool-gPMU-l5-u6-i3
Oracle PL/SQL
1
#srvctladdserverpool-gTST-l2-u3-i2
“srvctl -h ” is a good starting point to have a quick reference of the syntax.
You can check the status with:
1
2
3
4
5
6
7
8
9
# srvctl status serverpool
Server pool name:Free
Active servers count:0
Server pool name:Generic
Active servers count:0
Server pool name:PMU
Active servers count:6
Server pool name:TST
Active servers count:2
and the configuration:
1
2
3
4
5
6
7
8
9
10
11
12
13
# srvctl config serverpool
Server pool name:Free
Importance:0,Min:0,Max:-1
Candidate server names:
Server pool name:Generic
Importance:0,Min:0,Max:-1
Candidate server names:
Server pool name:PMU
Importance:3,Min:5,Max:6
Candidate server names:
Server pool name:TST
Importance:2,Min:2,Max:3
Candidate server names:
Modifying the configuration of serverpools
In this scenario, PMU is too big. The sum of minumum nodes is 2+5=7 nodes, so I have only one server that can be used for another server pool without falling below the minimum number of nodes.
I want to make some room to make another server pool composed of two or three nodes, so I reduce the serverpool PMU:
1
# srvctl modify serverpool -g PMU -l 3
Notice that PMU maxsize is still 6, so I don’t have free servers yet.
Oracle PL/SQL
1
2
3
4
5
6
7
#srvctlstatusdatabase-dPMU
InstancePMU_4isrunningonnodenode2
InstancePMU_2isrunningonnodenode3
InstancePMU_3isrunningonnodenode4
InstancePMU_5isrunningonnodenode6
InstancePMU_1isrunningonnodenode7
InstancePMU_6isrunningonnodenode8
So, if I try to create another serverpool I’m warned that some resources can be taken offline:
1
2
3
4
5
6
# srvctl add serverpool -g LUDO -l 2 -u 3 -i 1
PRCS-1009:Failed tocreate server pool LUDO
PRCR-1071:Failed toregister orupdate server pool ora.LUDO
CRS-2737:Unable toregister server pool'ora.LUDO'asthiswill affect running resources,but the force option was notspecified
The clusterware proposes to stop 2 instances from the db pmu on the serverpool PMU because it can reduce from 6 to 3, but I have to confirm the operation with the flag -f.
Modifying the serverpool layout can take time if resources have to be started/stopped.
1
2
3
4
5
6
7
8
9
10
11
# srvctl status serverpool
Server pool name:Free
Active servers count:0
Server pool name:Generic
Active servers count:0
Server pool name:LUDO
Active servers count:2
Server pool name:PMU
Active servers count:4
Server pool name:TST
Active servers count:2
My new serverpool is finally composed by two nodes only, because I’ve set an importance of 1 (PMU wins as it has an importance of 3).
Inviting RAC One Node databases to the party
Now that I have some room on my new serverpool, I can start creating new databases.
With PMD I can add two types of databases: RAC or RACONDENODE. Depending on the choice, I’ll have a database running on ALL NODES OF THE SERVER POOL or on ONE NODE ONLY. This is a kind of limitation in my opinion, hope Oracle will improve it in the near future: would be great to specify the cardinality also at database level.
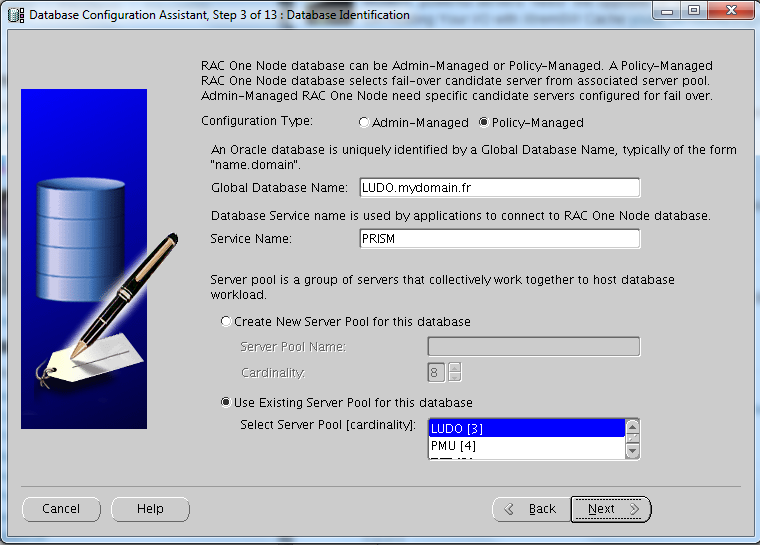
Creating a RAC One DB is as simple as selecting two radio box during in the dbca “standard” procedure:
The Server Pool can be created or you can specify an existent one (as in this lab):
The node was belonging to the pool LUDO, however I have this situation right after:
1
2
3
4
5
6
7
8
9
10
11
# srvctl status serverpool
Server pool name:Free
Active servers count:0
Server pool name:Generic
Active servers count:0
Server pool name:LUDO
Active servers count:2
Server pool name:PMU
Active servers count:3
Server pool name:TST
Active servers count:2
A server has been taken from the pol PMU and given to the pool LUDO. This is because PMU was having one more server than his minimum server requirement.
Now I can loose one node at time, I’ll have the following situation:
1 node lost: PMU 3, TST 2, LUDO 2
2 nodes lost: PMU 3, TST 2, LUDO 1 (as PMU is already on min and has higher priority, LUDO is penalized because has the lowest priority)
3 nodes lost:PMU 3, TST 2, LUDO 0 (as LUDO has the lowest priority)
4 nodes lost: PMU 3, TST 1, LUDO 0
5 nodes lost: PMU 3, TST 0, LUDO 0
So, my hyper-super-critical application will still have three nodes to have plenty of resources to run even with a multiple physical failure, as it is the server pool with the highest priority and a minimum required server number of 3.
What I would ask to Santa if I’ll be on the Nice List (ad if Santa works at Redwood Shores)
Dear Santa, I would like:
To create databases with node cardinality, to have for example 2 instances in a 3 nodes server pool
Server Pools that are aware of the physical location when I use stretched clusters, so I could end up always with “at least one active instance per site”.
The installation process of a typical Standard Edition RAC does not differ from the Enterprise Edition. To achieve a successful installation refer to the nice quick guide made by Yury Velikanov and change accordingly the Edition when installing the DB software.
Standard Edition and Feature availability
The first thing that impressed me, is that you’re still able to choose to enable pluggable databases in DBCA even if Multitenant option is not available for the SE.
So I decided to create a container database CDB01 using template files, so all options of EE are normally cabled into the new DB. The Pluggable Database name is PDB01.
1
2
3
4
5
6
7
8
9
10
11
[oracle@se12c01~]$sqlplus
SQL*Plus:Release12.1.0.1.0Production on Wed Jul314:21:472013
With the Real Application Clusters andAutomatic Storage Management options
As you can see, the initial banner contains “Real Application Clusters and Automatic Storage Management options“.
Multitenant option is not avilable. How SE reacts to its usage?
First, on the ROOT db, dba_feature_usage_statistics is empty.
1
2
3
4
5
6
7
8
9
SQL>alter session set container=CDB$ROOT;
Session altered.
SQL>select *from dba_feature_usage_statistics;
no rows selected
SQL>
This is interesting, because all features are in (remember it’s created from the generic template) , so the feature check is moved from the ROOT to the pluggable databases.
On the local PDB I have:
1
2
3
4
5
6
7
8
9
SQL>alter session set container=PDB01;
Session altered.
SQL>select *from dba_feature_usage_statistics where lower(name)like'%multitenant%';
alter database move datafile'DATA/CDB01/E09CA0E26A726D60E043A138A8C0E475/DATAFILE/users.284.819821651'
*
ERROR at line1:
ORA-00439:feature notenabled:online move datafile
Create a Service on the RAC Standard Edition (just to check if it works)
I’ve just followed the steps to do it on an EE. Keep in mind that I’m using admin managed DB (something will come about policy managed DBs, stay tuned).
As you can see it works pretty well. Comparing to 11g you have to specify the -pdb parameter:
With the Real Application Clusters andAutomatic Storage Management options
SQL>show con_name
CON_NAME
------------------------------
PDB02
SQL>
Let me know what do you think about SE RAC on 12c. It is valuable for you?
I’m also on twitter: @ludovicocaldara
Cheers
—
Ludo
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.Accept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.