This post is part of a blog series.
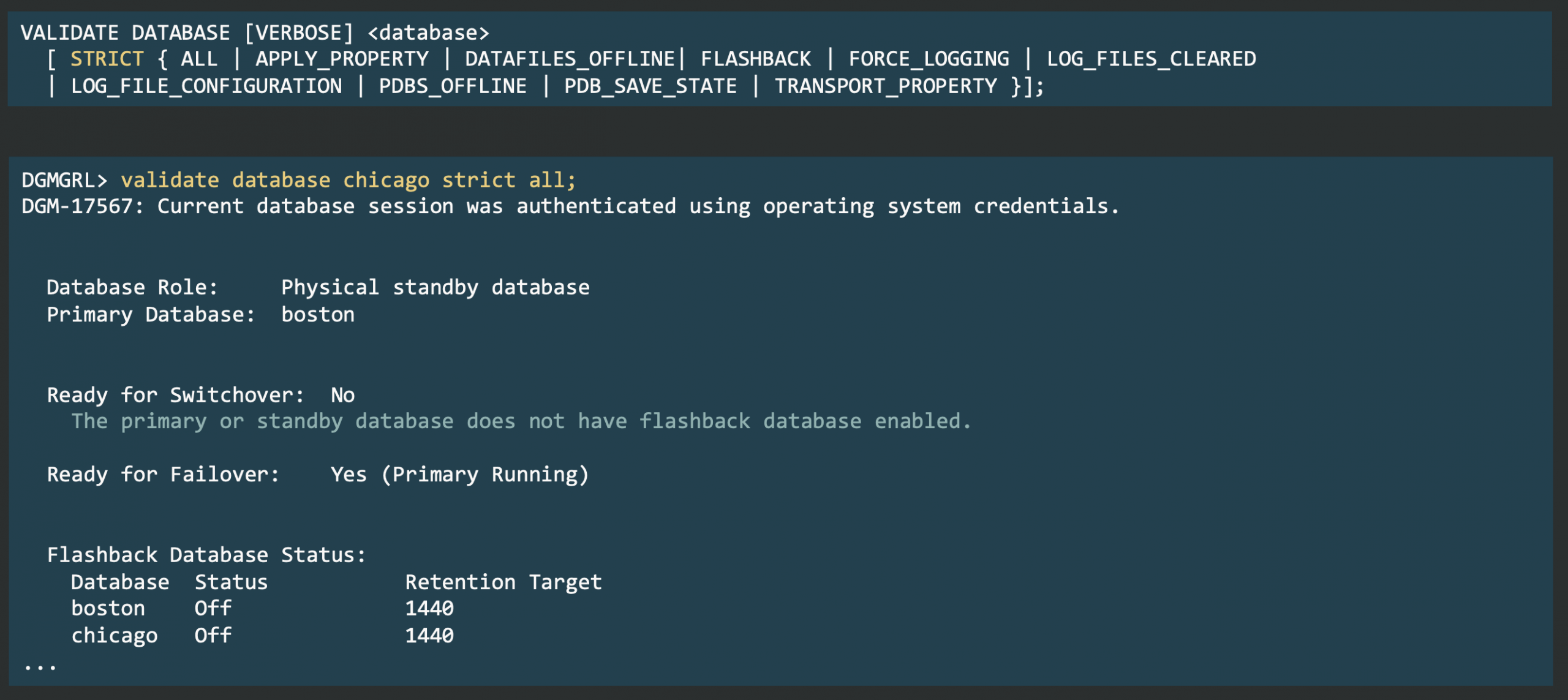
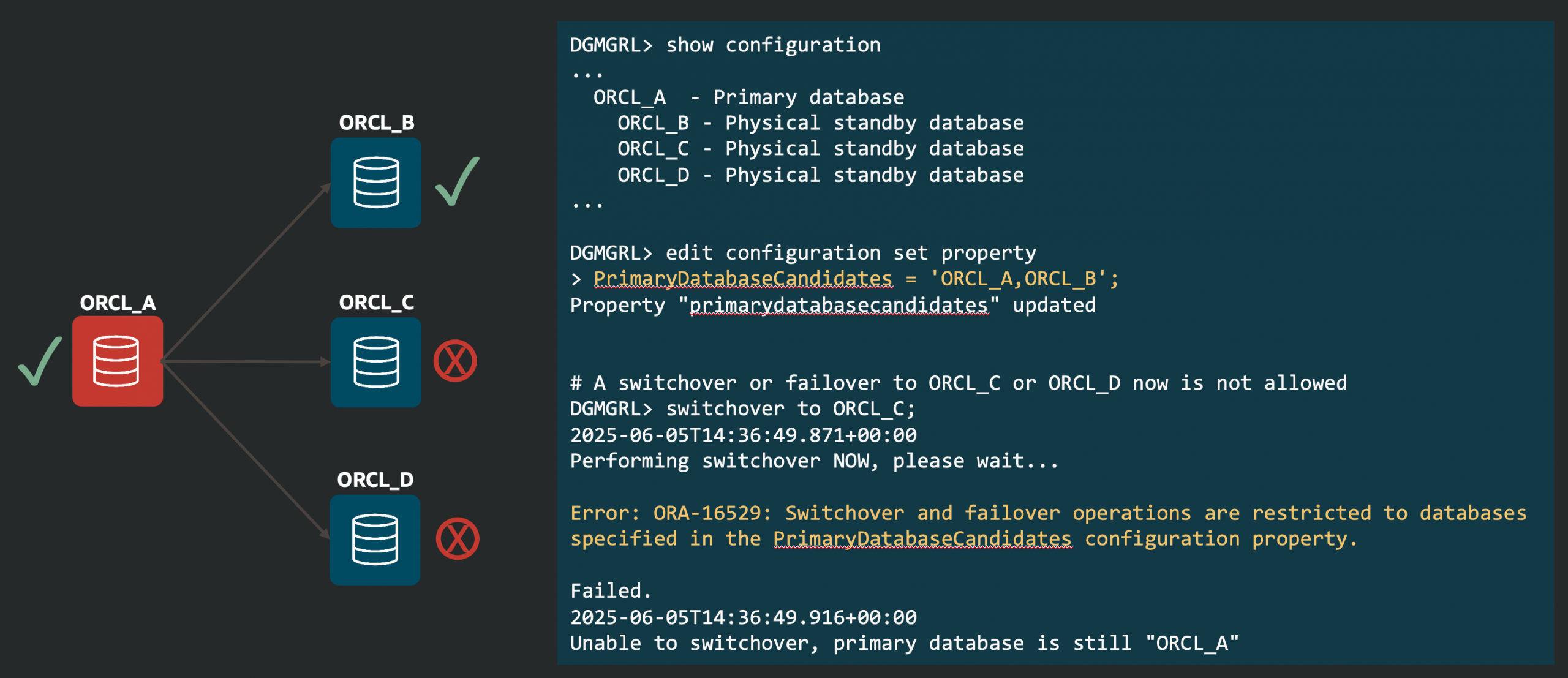
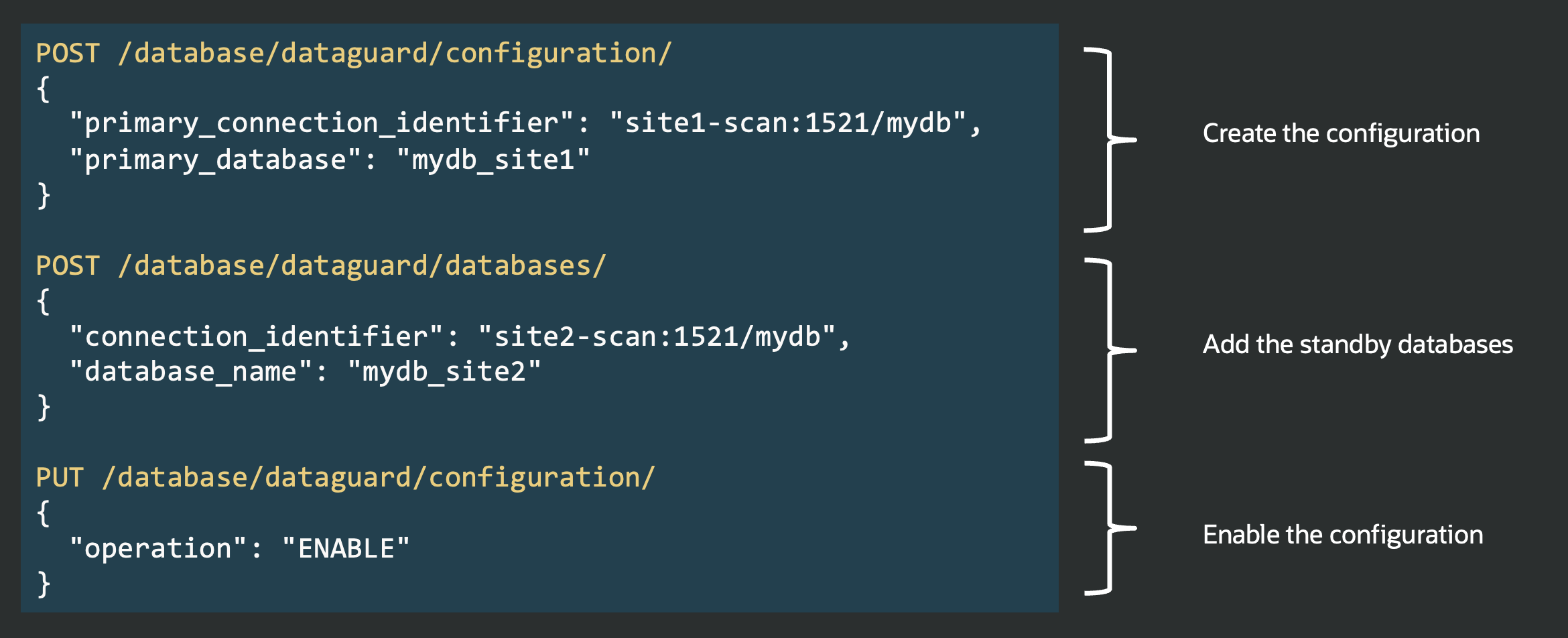
Until now, checking whether a database was ready to switch over or fail over meant running the VALIDATE DATABASE command through DGMGRL: there was no direct SQL alternative, and the VALIDATE DATABASE command isn’t available with other broker interfaces.
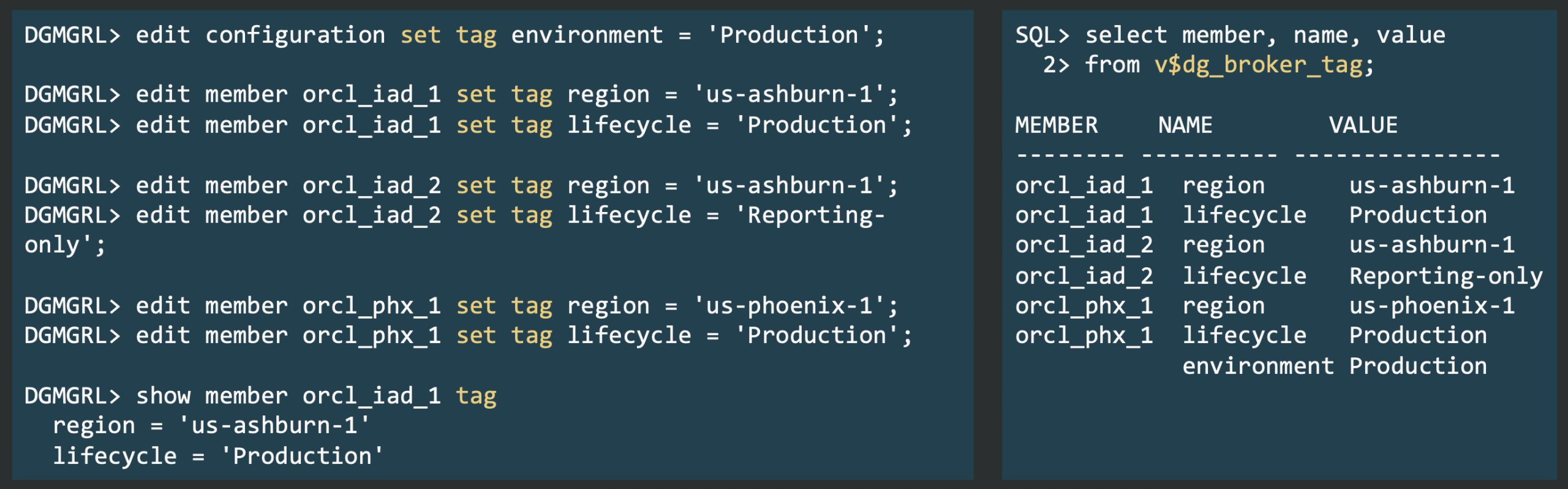
In Data Guard 26ai, the V$DG_BROKER_CONFIG view now includes two new columns: SWITCHOVER_READY and FAILOVER_READY. These columns, updated every minute by the Data Guard Broker’s health check, provide the status for switchover and failover readiness.
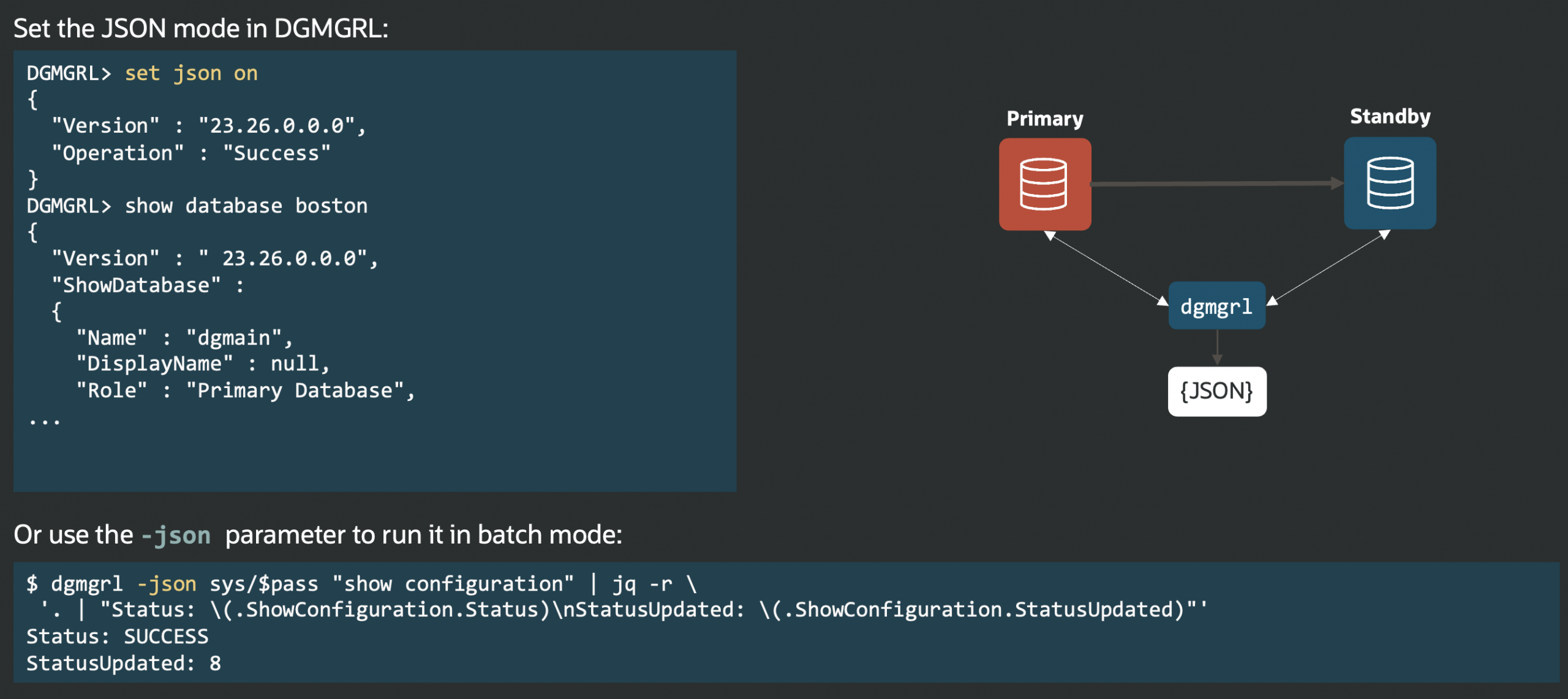
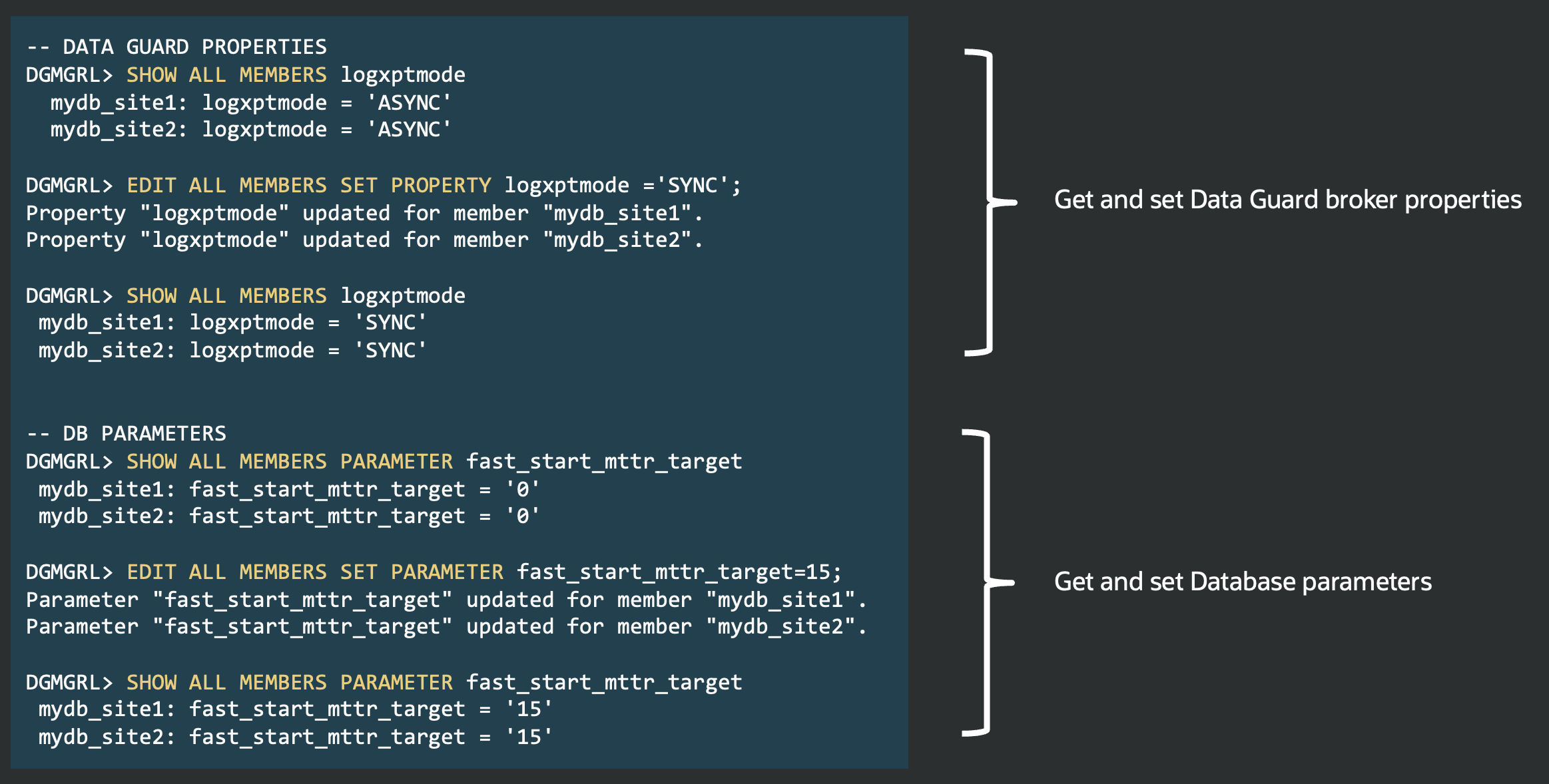
This means you can now monitor configuration topology, member status, and role change readiness directly with a SQL query, streamlining observability and monitoring through any SQL*Net client, without relying on DGMGRL.

For now, if either column shows “NO”, you still need DGMGRL for detailed diagnostics.