Ok, if you’re reading this post, you may want to read also the previous one that explains something more about the problem.
Briefly said, if you have a CDB running on ASM in a MAA architecture and you do not have Active Data Guard, when you clone a PDB you have to “copy” the datafiles somehow on the standby. The only solution offered by Oracle (in a MOS Note, not in the documentation) is to restore the PDB from the primary to the standby site, thus transferring it over the network. But if you have a huge PDB this is a bad solution because it impacts your network connectivity. (Note: ending up with a huge PDB IMHO can only be caused by bad consolidation. I do not recommend to consolidate huge databases on Multitenant).
So I’ve worked out another solution, that still has many defects and is almost not viable, but it’s technically interesting because it permits to discover a little more about Multitenant and Data Guard.
The three options
At the primary site, the process is always the same: Oracle copies the datafiles of the source, and it modifies the headers so that they can be used by the new PDB (so it changes CON_ID, DBID, FILE#, and so on).
On the standby site, by opposite, it changes depending on the option you choose:
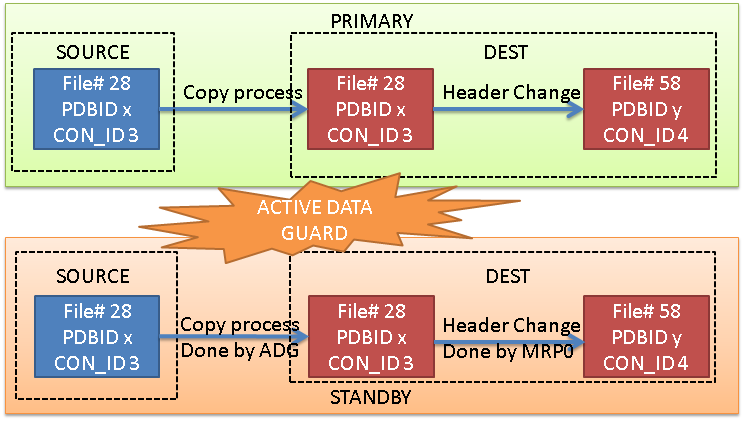
Option 1: Active Data Guard
If you have ADG, the ADG itself will take care of copying the datafile on the standby site, from the source standby pdb to the destination standby pdb. Once the copy is done, the MRP0 will continue the recovery. The modification of the header block of the destination PDB is done by the MRP0 immediately after the copy (at least this is what I understand).
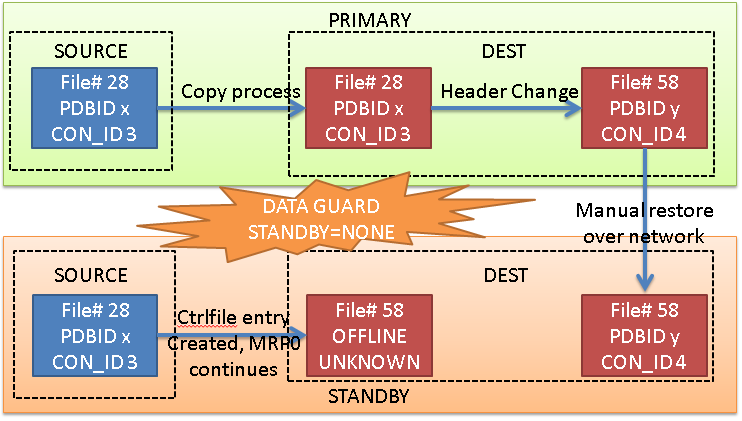
Option 2: No Active Data Guard, but STANDBYS=none
In this case, the copy on the standby site doesn’t happen, and the recovery process just add the entry of the new datafiles in the controlfile, with status OFFLINE and name UNKNOWNxxx. However, the source file cannot be copied anymore, because the MRP0 process will expect to have a copy of the destination datafile, not the source datafile. Also, any tentative of restore of the datafile 28 (in this example) will give an error because it does not belong to the destination PDB. So the only chance is to restore the destination PDB from the primary.
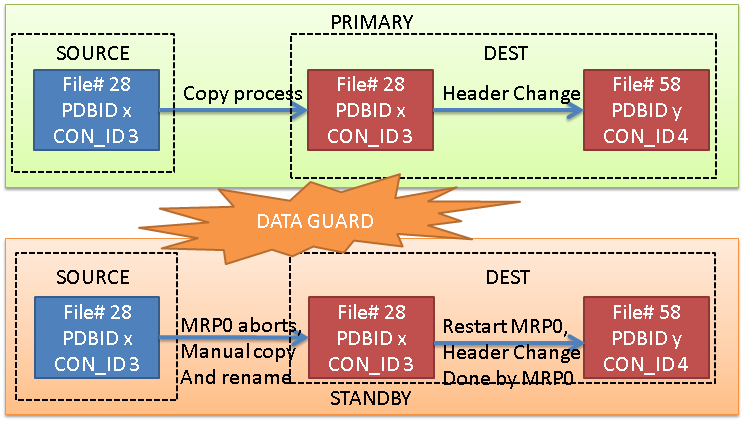
Option 3: No Active Data Guard, no STANDBYS=none
This is the case that I want to explain actually. Without the flag STANDBYS=none, the MRP0 process will expect to change the header of the new datafile, but because the file does not exist yet, the recovery process dies.
We can then copy it manually from the source standby pdb, and restart the recovery process, that will change the header. This process needs to be repeated for each datafile. (that’s why it’s not a viable solution, right now).
Let’s try it together:
The Environment
Primary
|
1 2 3 4 5 6 |
08:13:08 SYS@CDBATL_2> select db_unique_name, instance_name from v$database, gv$instance; DB_UNIQUE_NAME INSTANCE_NAME ------------------------------ ---------------- CDBATL CDBATL_2 CDBATL CDBATL_1 |
Standby
|
1 2 3 4 5 6 |
07:35:56 SYS@CDBGVA_2> select db_unique_name, instance_name from v$database, gv$instance; DB_UNIQUE_NAME INSTANCE_NAME ------------------------------ ---------------- CDBGVA CDBGVA_1 CDBGVA CDBGVA_2 |
The current user PDB (any resemblance to real people is purely coincidental 😉 #haveUSeenMaaz):
|
1 2 3 4 5 6 |
08:14:31 SYS@CDBATL_2> select open_mode, name from gv$pdbs where name='MAAZ'; OPEN_MODE NAME ---------- ------------------------------ OPEN MAAZ OPEN MAAZ |
Cloning the PDB on the primary
First, make sure that the source PDB is open read-only
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
08:45:54 SYS@CDBATL_2> alter pluggable database maaz close immediate instances=all; Pluggable database altered. 08:46:20 SYS@CDBATL_2> alter pluggable database maaz open read only instances=all; Pluggable database altered. 08:46:32 SYS@CDBATL_2> select open_mode, name from gv$pdbs where name='MAAZ' ; OPEN_MODE NAME ---------- ------------------------------ READ ONLY MAAZ READ ONLY MAAZ |
Then, clone the PDB on the primary without the clause STANDBYS=NONE:
|
1 2 3 |
08:46:41 SYS@CDBATL_2> create pluggable database LUDO from MAAZ; Pluggable database created. |
Review the clone on the Standby
At this point, on the standby the alert log show that the SYSTEM datafile is missing, and the recovery process stops.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
Mon Dec 15 17:46:11 2014 Recovery created pluggable database LUDO Mon Dec 15 17:46:11 2014 Errors in file /u01/app/oracle/diag/rdbms/cdbgva/CDBGVA_2/trace/CDBGVA_2_mrp0_16464.trc: ORA-01565: error in identifying file '+DATA' ORA-17503: ksfdopn:2 Failed to open file +DATA ORA-15045: ASM file name '+DATA' is not in reference form Recovery was unable to create the file as: '+DATA' MRP0: Background Media Recovery terminated with error 1274 Mon Dec 15 17:46:11 2014 Errors in file /u01/app/oracle/diag/rdbms/cdbgva/CDBGVA_2/trace/CDBGVA_2_mrp0_16464.trc: ORA-01274: cannot add data file that was originally created as '+DATA/CDBATL/0A4A0048D5321597E053334EA8C0E40A/DATAFILE/system.825.866396765' Mon Dec 15 17:46:11 2014 Managed Standby Recovery not using Real Time Apply Mon Dec 15 17:46:11 2014 Recovery interrupted! Recovery stopped due to failure in applying recovery marker (opcode 17.34). Datafiles are recovered to a consistent state at change 10433175 but controlfile could be ahead of datafiles. Mon Dec 15 17:46:11 2014 Errors in file /u01/app/oracle/diag/rdbms/cdbgva/CDBGVA_2/trace/CDBGVA_2_mrp0_16464.trc: ORA-01274: cannot add data file that was originally created as '+DATA/CDBATL/0A4A0048D5321597E053334EA8C0E40A/DATAFILE/system.825.866396765' Mon Dec 15 17:46:11 2014 MRP0: Background Media Recovery process shutdown (CDBGVA_2) |
One remarkable thing, is that in the standby controlfile, ONLY THE SYSTEM DATAFILE exists:
|
1 2 3 4 5 6 7 8 9 10 11 |
18:02:50 SYS@CDBGVA_2> select con_id from v$pdbs where name='LUDO'; CON_ID ---------- 4 18:03:10 SYS@CDBGVA_2> select name from v$datafile where con_id=4; NAME --------------------------------------------------------------------------- +DATA/CDBATL/0A4A0048D5321597E053334EA8C0E40A/DATAFILE/system.825.866396765 |
We need to fix the datafiles one by one, but most of the steps can be done once for all the datafiles.
Copy the source PDB from the standby
What do we need to do? Well, the recovery process is stopped, so we can safely copy the datafiles of the source PDB from the standby site because they have not moved yet. (meanwhile, we can put the primary source PDB back in read-write mode).
|
1 2 3 4 5 6 7 8 |
-- on primary 08:58:07 SYS@CDBATL_2> alter pluggable database maaz close immediate instances=all; Pluggable database altered. 08:58:15 SYS@CDBATL_2> alter pluggable database maaz open read write instances=all; Pluggable database altered. |
Copy the datafiles:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
## on the standby: RMAN> backup as copy pluggable database MAAZ; Starting backup at 15-DEC-14 using target database control file instead of recovery catalog allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=58 instance=CDBGVA_2 device type=DISK channel ORA_DISK_1: starting datafile copy input datafile file number=00029 name=+DATA/CDBGVA/0243BF7B39D4440AE053334EA8C0E471/DATAFILE/sysaux.463.857404625 output file name=+DATA/CDBGVA/0243BF7B39D4440AE053334EA8C0E471/DATAFILE/sysaux.863.866397043 tag=TAG20141215T175041 RECID=54 STAMP=866397046 channel ORA_DISK_1: datafile copy complete, elapsed time: 00:00:07 channel ORA_DISK_1: starting datafile copy input datafile file number=00028 name=+DATA/CDBGVA/0243BF7B39D4440AE053334EA8C0E471/DATAFILE/system.283.857404623 output file name=+DATA/CDBGVA/0243BF7B39D4440AE053334EA8C0E471/DATAFILE/system.864.866397049 tag=TAG20141215T175041 RECID=55 STAMP=866397051 channel ORA_DISK_1: datafile copy complete, elapsed time: 00:00:03 Finished backup at 15-DEC-14 Starting Control File and SPFILE Autobackup at 15-DEC-14 piece handle=+DATA/CDBGVA/AUTOBACKUP/2014_12_15/s_866396771.865.866397053 comment=NONE Finished Control File and SPFILE Autobackup at 15-DEC-14 |
Do the magic
Now there’s the interesting part: we need to assign the datafile copies of the maaz PDB to LUDO.
Sadly, the OMF will create the copies on the bad location (it’s a copy, to they are created on the same location as the source PDB).
We cannot try to uncatalog and recatalog the copies, because they will ALWAYS be affected to the source PDB. Neither we can use RMAN because it will never associate the datafile copies to the new PDB. We need to rename the files manually.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
RMAN> list datafilecopy all; List of Datafile Copies ======================= Key File S Completion Time Ckp SCN Ckp Time ------- ---- - --------------- ---------- --------------- 55 28 A 15-DEC-14 10295232 14-DEC-14 Name: +DATA/CDBGVA/0243BF7B39D4440AE053334EA8C0E471/DATAFILE/system.864.86639709 Tag: TAG20141215T175041 54 29 A 15-DEC-14 10295232 14-DEC-14 Name: +DATA/CDBGVA/0243BF7B39D4440AE053334EA8C0E471/DATAFILE/sysaux.863.86639703 Tag: TAG20141215T175041 RMAN> select name, guid from v$pdbs; NAME GUID ---------- -------------------------------- PDB$SEED FFBCECBB503D606BE043334EA8C019B7 MAAZ 0243BF7B39D4440AE053334EA8C0E471 LUDO 0A4A0048D5321597E053334EA8C0E40A |
It’s better to uncatalog the datafile copies before, so we keep the catalog clean:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
RMAN> change datafilecopy '+DATA/CDBGVA/0243BF7B39D4440AE053334EA8C0E471/DATAFILE/system.864.866397049' uncatalog; uncataloged datafile copy datafile copy file name=+DATA/CDBGVA/0243BF7B39D4440AE053334EA8C0E471/DATAFILE/system.864.866397049 RECID=55 STAMP=866397051 Uncataloged 1 objects RMAN> change datafilecopy '+DATA/CDBGVA/0243BF7B39D4440AE053334EA8C0E471/DATAFILE/sysaux.863.866397043' uncatalog; uncataloged datafile copy datafile copy file name=+DATA/CDBGVA/0243BF7B39D4440AE053334EA8C0E471/DATAFILE/sysaux.863.866397043 RECID=54 STAMP=866397046 Uncataloged 1 objects |
Then, because we cannot rename files on a standby database with standby file management set to AUTO, we need to put it temporarily to MANUAL.
|
1 2 3 4 5 |
10:24:21 SYS@CDBGVA_2> alter database rename file '+DATA/CDBATL/0A4A0048D5321597E053334EA8C0E40A/DATAFILE/system.825.866396765' to '+DATA/CDBGVA/0243BF7B39D4440AE053334EA8C0E471/DATAFILE/system.864.866397049'; alter database rename file '+DATA/CDBATL/0A4A0048D5321597E053334EA8C0E40A/DATAFILE/system.825.866396765' to '+DATA/CDBGVA/0243BF7B39D4440AE053334EA8C0E471/DATAFILE/system.864.866397049' * ERROR at line 1: ORA-01275: Operation RENAME is not allowed if standby file management is automatic. |
|
1 2 3 4 5 6 |
10:27:49 SYS@CDBGVA_2> select name, ispdb_modifiable from v$parameter where name like 'standby%'; NAME ISPDB ------------------------------------------------------------ ----- standby_archive_dest FALSE standby_file_management FALSE |
standby_file_management is not PDB modifiable, so we need to do it for the whole CDB.
|
1 2 3 4 5 6 7 |
10:31:42 SYS@CDBGVA_2> alter system set standby_file_management=manual; System altered. 18:05:04 SYS@CDBGVA_2> alter database rename file '+DATA/CDBATL/0A4A0048D5321597E053334EA8C0E40A/DATAFILE/system.825.866396765' to '+DATA/CDBGVA/0243BF7B39D4440AE053334EA8C0E471/DATAFILE/system.864.866397049'; Database altered. |
then we need to set back the standby_file_management=auto or the recover will not start:
|
1 2 |
10:34:24 SYS@CDBGVA_2> alter system set standby_file_management=auto; System altered. |
We can now restart the recovery.
The recovery process will:
– change the new datafile by modifying the header for the new PDB
– create the entry for the second datafile in the controlfile
– crash again because the datafile is missing
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
18:11:30 SYS@CDBGVA_2> alter database recover managed standby database; alter database recover managed standby database * ERROR at line 1: ORA-00283: recovery session canceled due to errors ORA-01111: name for data file 61 is unknown - rename to correct file ORA-01110: data file 61: '/u01/app/oracle/product/12.1.0.2/dbhome_1/dbs/UNNAMED00061' ORA-01157: cannot identify/lock data file 61 - see DBWR trace file ORA-01111: name for data file 61 is unknown - rename to correct file ORA-01110: data file 61: '/u01/app/oracle/product/12.1.0.2/dbhome_1/dbs/UNNAMED00061' 18:11:33 SYS@CDBGVA_2> select name from v$datafile where con_id=4; NAME --------------------------------------------------------------------------- +DATA/CDBGVA/0243BF7B39D4440AE053334EA8C0E471/DATAFILE/system.864.866397049 /u01/app/oracle/product/12.1.0.2/dbhome_1/dbs/UNNAMED00061 |
We already have the SYSAUX datafile, right? So we can alter the name again:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
18:14:21 SYS@CDBGVA_2> alter system set standby_file_management=manual; System altered. 18:14:29 SYS@CDBGVA_2> alter database rename file '/u01/app/oracle/product/12.1.0.2/dbhome_1/dbs/UNNAMED00061' to '+DATA/CDBGVA/0243BF7B39D4440AE053334EA8C0E471/DATAFILE/sysaux.863.866397043'; Database altered. 18:14:31 SYS@CDBGVA_2> alter system set standby_file_management=auto; System altered. 18:14:35 SYS@CDBGVA_2> alter database recover managed standby database; |
This time all the datafiles have been copied (no user datafile for this example) and the recovery process will continue!! 🙂 so we can hit ^C and start it in background.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
18:14:35 SYS@CDBGVA_2> alter database recover managed standby database; alter database recover managed standby database * ERROR at line 1: ORA-16043: Redo apply has been canceled. ORA-01013: user requested cancel of current operation 18:18:10 SYS@CDBGVA_2> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT; Database altered. 18:18:19 SYS@CDBGVA_2> |
The Data Guard configuration reflects the success of this operation.
Do we miss anything?
Of course, we do!! The datafile names of the new PDB reside in the wrong ASM path. We need to fix them!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
18:23:07 SYS@CDBGVA_2> alter database recover managed standby database cancel; Database altered. RMAN> backup as copy pluggable database ludo; Starting backup at 15-DEC-14 using target database control file instead of recovery catalog allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=60 instance=CDBGVA_2 device type=DISK channel ORA_DISK_1: starting datafile copy input datafile file number=00061 name=+DATA/CDBGVA/0243BF7B39D4440AE053334EA8C0E471/DATAFILE/sysaux.863.866397043 output file name=+DATA/CDBGVA/0A4A0048D5321597E053334EA8C0E40A/DATAFILE/sysaux.866.866398933 tag=TAG20141215T182213 RECID=56 STAMP=866398937 channel ORA_DISK_1: datafile copy complete, elapsed time: 00:00:07 channel ORA_DISK_1: starting datafile copy input datafile file number=00060 name=+DATA/CDBGVA/0243BF7B39D4440AE053334EA8C0E471/DATAFILE/system.864.866397049 output file name=+DATA/CDBGVA/0A4A0048D5321597E053334EA8C0E40A/DATAFILE/system.867.866398941 tag=TAG20141215T182213 RECID=57 STAMP=866398943 channel ORA_DISK_1: datafile copy complete, elapsed time: 00:00:03 Finished backup at 15-DEC-14 Starting Control File and SPFILE Autobackup at 15-DEC-14 piece handle=+DATA/CDBGVA/AUTOBACKUP/2014_12_15/s_866398689.868.866398945 comment=NONE Finished Control File and SPFILE Autobackup at 15-DEC-14 RMAN> switch pluggable database ludo to copy; using target database control file instead of recovery catalog datafile 60 switched to datafile copy "+DATA/CDBGVA/0A4A0048D5321597E053334EA8C0E40A/DATAFILE/system.867.866398941" datafile 61 switched to datafile copy "+DATA/CDBGVA/0A4A0048D5321597E053334EA8C0E40A/DATAFILE/sysaux.866.866398933" 18:23:54 SYS@CDBGVA_2> select name from v$datafile where con_id=4; NAME ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ +DATA/CDBGVA/0A4A0048D5321597E053334EA8C0E40A/DATAFILE/system.867.866398941 +DATA/CDBGVA/0A4A0048D5321597E053334EA8C0E40A/DATAFILE/sysaux.866.866398933 |
I know there’s no practical use of this procedure, but it helps a lot in understanding how Multitenant has been implemented.
I expect some improvements in 12.2!!
Cheers
—
Ludo