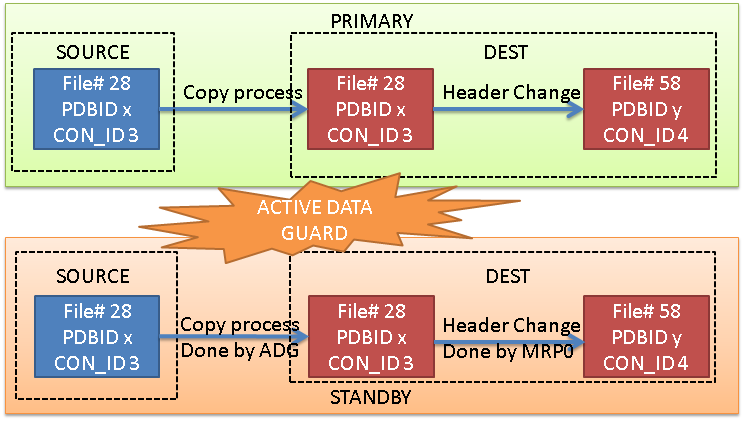
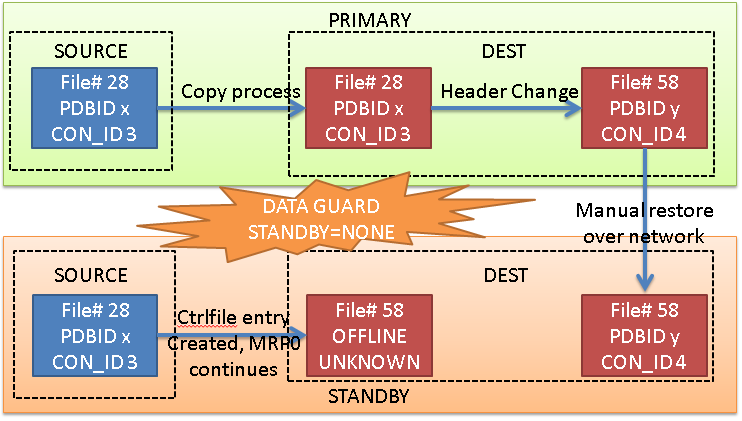
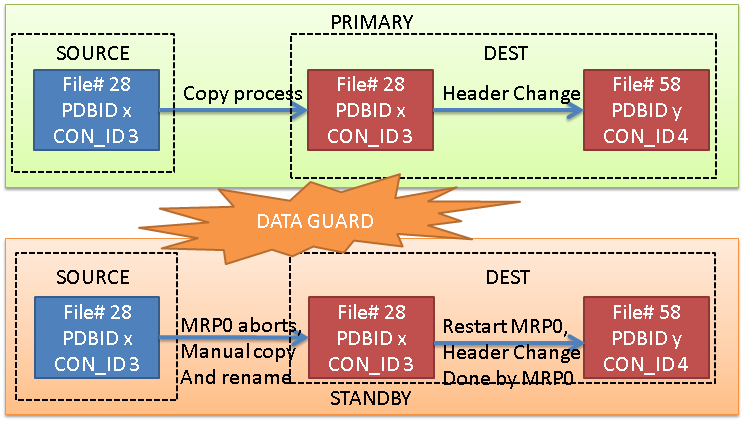
Here we go: as usual, the feedback that I usually get after my talks (specifically, after POUG High Five conference), is if I will share my demo scripts and material.
Sadly, the demos I am doing for my presentation “Get the most out of Oracle Data Guard” are quite tied to an environment built for the purpose of the demos. So, do not expect to get scripts easy to use as is, but rather to get some ideas beyond the demo themselves.
I hope they will help to get the whole picture.
Of course, if you need to implement a cloning strategy based on Data Guard or any other solution that I describe in this post, please feel free to contact me, I will be glad to help you implement it in your environment.
Slides
Demo 1
Video:
Scripts:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 |
#!/bin/bash function tt () { title=$@ pad=$(printf '%0.1s' "-"{1..60}) echo echo echo $pad echo "- $title" echo $pad } . .bash_profile PAUSE=/home/oracle/pause.sh SYSPWD=Vagrant1_ clear sid sour_ludo sudo sed -i -e '/sour-s/d' /var/named/trivadistraining.com sudo sed -i '$ a\ sour-s1 IN CNAME ludo01\ sour-s2 IN CNAME ludo01' /var/named/trivadistraining.com sudo systemctl reload named.service tt "Naming resolution" tnsping sour_smart nslookup sour-s1 nslookup sour-s2 $PAUSE tt "Connect to sour_smart in another terminal" $PAUSE clear tt "Creating Data Guard Configuration resolution" dgmgrl -echo <<EOF connect sys/$SYSPWD show configuration; EOF $PAUSE dgmgrl -echo <<EOF connect sys/$SYSPWD create configuration sour as primary database is sour_ludo connect identifier is sour_ludo.trivadistraining.com; add database sour_vico as connect identifier is sour_vico.trivadistraining.com; enable database sour_vico; enable configuration; host sleep 5; show configuration; EOF $PAUSE clear tt "Modifying the DNS configuration" sudo sed -i -e '/sour-s2/d' /var/named/trivadistraining.com sudo sed -i '$ a\ sour-s2 IN CNAME vico01' /var/named/trivadistraining.com sudo systemctl reload named.service tt "Naming resolution" tnsping sour_smart nslookup sour-s1 nslookup sour-s2 $PAUSE clear tt "Switchover to sour_vico" dgmgrl -echo <<EOF connect sys/$SYSPWD switchover to sour_vico; EOF $PAUSE tt "Did the session fail over?" $PAUSE clear tt "Modifying the DNS configuration" sudo sed -i -e '/sour-s1/d' /var/named/trivadistraining.com sudo sed -i '$ a\ sour-s1 IN CNAME vico01' /var/named/trivadistraining.com sudo systemctl reload named.service tt "Naming resolution" tnsping sour_smart nslookup sour-s1 nslookup sour-s2 $PAUSE tt "Removing Data Guard configuration" dgmgrl -echo <<EOF connect sys/$SYSPWD remove configuration; show configuration; EOF |
Demo 2
Video:
Scripts:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 |
#!/bin/bash function tt () { title=$@ pad=$(printf '%0.1s' "-"{1..60}) echo echo echo $pad echo "- $title" echo $pad } . .bash_profile clear sid stout_vico SYSPWD=Vagrant1_ PAUSE=/home/oracle/pause.sh tt "Current configuration" dgmgrl -echo <<EOF connect sys/$SYSPWD show configuration; EOF $PAUSE clear tt "Instance and redo apply status" sqlplus / as sysdba <<EOF select instance_name, status from v\$instance; select db_unique_name, database_role from v\$database; select process, status, client_process, sequence#, block#, delay_mins from v\$managed_standby order by process; EOF $PAUSE clear tt "Inserting something in the primary" sqlplus ludo/ludo@stout_ludo <<EOF DROP TABLE demo1; CREATE TABLE demo1 ( id NUMBER GENERATED AS IDENTITY , foo DATE DEFAULT (sysdate) , CONSTRAINT demo1_pk PRIMARY KEY (id) ); INSERT INTO demo1 (foo) VALUES(sysdate); INSERT INTO demo1 (foo) VALUES(sysdate); INSERT INTO demo1 (foo) VALUES(sysdate); INSERT INTO demo1 (foo) VALUES(sysdate); INSERT INTO demo1 (foo) VALUES(sysdate); COMMIT; ALTER SESSION SET NLS_DATE_FORMAT='YYYY-MM-DD HH24:MI:SS'; SELECT * FROM demo1 ORDER BY id; exit EOF $PAUSE clear tt "Converting physical standby to snapshot standby" dgmgrl -echo <<EOF connect sys/$SYSPWD show configuration; convert database stout_vico to snapshot standby; show configuration; EOF $PAUSE tt "Let's check the alert log (another window)" $PAUSE clear tt "Instance and redo apply status" sqlplus / as sysdba <<EOF SELECT instance_name, status FROM v\$instance; SELECT db_unique_name, database_role FROM v\$database; set lines 180 col name for a80 SELECT scn, name FROM v\$restore_point; SELECT process, status, client_process, sequence#, block#, delay_mins FROM v\$managed_standby ORDER BY process; set feedback off SELECT process, status, client_process, sequence#, block#, delay_mins FROM v\$managed_standby WHERE client_process='LGWR'; EXEC dbms_lock.sleep(2); SELECT process, status, client_process, sequence#, block#, delay_mins FROM v\$managed_standby WHERE client_process='LGWR'; EXEC dbms_lock.sleep(2); SELECT process, status, client_process, sequence#, block#, delay_mins FROM v\$managed_standby WHERE client_process='LGWR'; EOF $PAUSE clear tt "Let's do something in the PRIMARY database!" sqlplus ludo/ludo@stout_ludo <<EOF ALTER TABLE demo1 ADD test VARCHAR(20) DEFAULT ('PRIMARY'); INSERT INTO demo1 (foo) VALUES(sysdate); INSERT INTO demo1 (foo) VALUES(sysdate); COMMIT; ALTER SESSION SET NLS_DATE_FORMAT='YYYY-MM-DD HH24:MI:SS'; SELECT * FROM demo1 ORDER BY id; exit EOF $PAUSE clear tt "Let's do something in the snapshot standby!" sqlplus ludo/ludo@stout_vico <<EOF ALTER TABLE demo1 ADD test VARCHAR(20) DEFAULT ('STANDBY'); INSERT INTO demo1 (foo) VALUES(sysdate); INSERT INTO demo1 (foo) VALUES(sysdate); COMMIT; ALTER SESSION SET NLS_DATE_FORMAT='YYYY-MM-DD HH24:MI:SS'; SELECT * FROM demo1 ORDER BY id; exit EOF $PAUSE clear tt "Convert back to physical standby" dgmgrl -echo <<EOF connect sys/$SYSPWD show configuration; convert database stout_vico to physical standby; show configuration; EOF $PAUSE clear tt "Instance and redo apply status" sqlplus / as sysdba <<EOF SELECT instance_name, status FROM v\$instance; SELECT db_unique_name, database_role FROM v\$database; set lines 180 col name for a80 SELECT scn, name FROM v\$restore_point; SELECT process, status, client_process, sequence#, block#, delay_mins FROM v\$managed_standby ORDER BY process; EOF |
Demo 3
Video:
Scripts:
Preparation:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#!/bin/bash NUM=`echo $$ | cut -c 1-4` export NEWNAME=${1:-poug$NUM} export ORACLE_SID=$NEWNAME export ORACLE_HOME=/u01/app/oracle/product/12.2.0.1/dbhome_1 [[ -L /u02/$NEWNAME ]] && rm $/u02/$NEWNAME ln -s /u02/acfs/.ACFS/snaps/$NEWNAME /u02/$NEWNAME set -x $ORACLE_HOME/bin/srvctl add database -db $NEWNAME -oraclehome $ORACLE_HOME -dbtype SINGLE -instance $NEWNAME -spfile /u02/$NEWNAME/spfile$NEWNAME.ora -dbname $NEWNAME -policy MANUAL -acfspath "/u02/acfs,/u02/fra" -node $HOSTNAME set +x |
snap_acfs.pl
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 |
#!/u01/app/oracle/tvdtoolbox/tvdperl-Linux-x86-64-02.04.00-05.08.04/bin/tvd_perl # # Purpose..........: Create a new snapshot with rotating name # # snap_acfs.pl # -p <parent> : name of the parent snapshot # -n <name> : prefix of the snapshot # -s <suffix> : optional, use "weekday" to have the day name as suffix (Sun - Sat) # # e.g. snap_acfs.pl -p stout -n stout -s "weekday" # will clone from /u02/acfs/.ACFS/snaps/stout # to /u02/acfs/.ACFS/snaps/stout.Tue (or whatever the day is) # # e.g. snap_acfs.pl -n stout -p stout.Mon # will clone from /u02/acfs/.ACFS/snaps/stout.Mon # to /u02/acfs/.ACFS/snaps/stout # # e.g. snap_acfs.pl -n stout2 -p stout # will clone from /u02/acfs/.ACFS/snaps/stout # to /u02/acfs/.ACFS/snaps/stout2 # # EXISTING SNAPSHOT WILL BE DROPPED!! # # # use strict; use File::Copy; use Net::SMTP; use Sys::Hostname; use Getopt::Std 'getopts'; use File::Basename; my $CloneDIR; # predefine rootDir variable BEGIN { use FindBin qw($Bin); # get the current path of script use Cwd 'abs_path'; $CloneDIR = abs_path("$Bin/.."); # get the absolut rood path to clone directory } my $CloneLOGDir = $CloneDIR."/log"; # LOG Directory my $baseACFS = "/u02/acfs/"; my $ORA_CRS_HOME = "/u01/app/grid/12.2.0.1"; my $acfsutil = "/usr/sbin/acfsutil"; my $basename = basename($0, ".pl"); my $ParentSnapName; my $ParentSnap=0; ## no parent snapshots by default my $PrefixName; my $NewName; my $SuffixName; my %opts; my $MountPoint; my $SnapCreate; ################################################################################ # Main ################################################################################ my $StartDate = localtime; &DoMsg ("Start of $basename.pl"); unless ( open (MAINLOG, ">>$CloneLOGDir/$basename.log") ) { &DoMsg ("Can't open Main Logfile $CloneLOGDir/$basename.log"); exit 1; } # Process command line arguments if ( ! defined @ARGV ) { &Usage; exit 1; } getopts('n:p:s:b:', \%opts); if ($opts{"p"}) { $ParentSnapName = lc($opts{"p"}); } else { &DoMsg ("Parent snapshot name not given!"); &Usage; exit 1; } if ($opts{"n"}) { $PrefixName = lc($opts{"n"}); } else { &DoMsg ("New snapshot prefix not given! Defaults to ${ParentSnapName}"); $PrefixName = "${ParentSnapName}"; } if ($opts{"s"}) { $SuffixName = lc($opts{"s"}); if ( $SuffixName eq "weekday" ) { $SuffixName = lc(&getWeekDay); } $SuffixName = "." . $SuffixName; } else { $SuffixName = ""; } $NewName = "${PrefixName}${SuffixName}"; &DoMsg ("Parent: $ParentSnapName"); &DoMsg ("Prefix: $PrefixName"); &DoMsg ("Suffix: $SuffixName"); &DoMsg ("New Name: $NewName"); $MountPoint = $baseACFS; $SnapCreate = "$acfsutil snap create -w -p $ParentSnapName $NewName $MountPoint"; &DoMsg ("Create Command: $SnapCreate "); my $cmd = "$acfsutil snap info $NewName $MountPoint"; &DoMsg ($cmd); open( CMD, $cmd . " |"); &DoMsg (join("", <CMD>)); close CMD; if ( $? != 0 ) { &DoMsg ("Snapshot $NewName does not exist inside mount point $MountPoint. Continuing."); } else { &DoMsg ("Snapshot $NewName already exists inside mount point $MountPoint. Now it will be deleted."); $cmd = "$acfsutil snap delete $NewName $MountPoint"; &DoMsg ($cmd); open( CMD, $cmd . " |"); &DoMsg (join("", <CMD>)); close CMD; if ( $? != 0 ) { &DoMsg ("Cannot delete Snapshot $NewName in mount point $MountPoint. Script will exit."); exit 1; } } &DoMsg ("Creating the new snapshot:"); &DoMsg ($SnapCreate); open( CMD, $SnapCreate . " |"); &DoMsg (join("", <CMD>)); close CMD; if ( $? != 0 ) { &DoMsg ("Cannot create Snapshot $NewName in mount point $MountPoint. Script will exit."); exit 1; } #else { #&DoMsg ("Current snapshots:"); #open( CMD, "$acfsutil snap info $MountPoint |"); #&DoMsg (join("", <CMD>)); #close CMD; #} #------------------------------------------------------------------------------- # DoMsg # # PURPOSE : echo with timestamp YYYY-MM-DD_H24:MI:SS # PARAMS : $*: the messages # GLOBAL VARS: none #------------------------------------------------------------------------------- sub DoMsg { my $msg = shift; my $timestamp = &getTimestamp; print ("$timestamp $msg\n"); if (fileno(MAINLOG)) {print MAINLOG "$timestamp $msg\n";} } #------------------------------------------------------------------------------- # getTimestamp # # PURPOSE : returns timestamp in different formats # PARAMS : format_parm # GLOBAL VARS: none #------------------------------------------------------------------------------- sub getTimestamp { # # Format 1: dd-mm-yyyy_hh24:mi:ss # Format 2: dd.mm.yyyy_hh24miss # Format 3: dd.mm.yyyy # Format 4: hh24:mi:ss # Rest: dd.mm.yyyy hh24:mi:ss (default) # my $Parm = shift; my $date; my $date2; my $heure; my $heure2; my ($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst); if ( length($Parm) > 1 ) { ($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime($Parm); } else { ($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime; } $date = (sprintf "%2.0d",($mday)).".".(sprintf "%2.0d",($mon+1)).".".($year+1900); $date =~ s/ /0/g; $date2 = (sprintf "%2.0d",($mday))."-".(sprintf "%2.0d",($mon+1))."-".($year+1900); $date2 =~ s/ /0/g; $heure = (sprintf "%2.0d",($hour)).":".(sprintf "%2.0d",($min)).":".(sprintf "%2.0d",($sec)); $heure =~ s/ /0/g; $heure2 = (sprintf "%2.0d",($hour)).(sprintf "%2.0d",($min)).(sprintf "%2.0d",($sec)); $heure2 =~ s/ /0/g; if ($Parm eq "1") { return ($date2."_".$heure) } elsif ($Parm eq "2") { return ($date."_".$heure2) } elsif ($Parm eq "3") { return ($date) } elsif ($Parm eq "4") { return ($heure) } else { return ($date." ".$heure) }; } #------------------------------------------------------------------------------- # getWeekDay # # PURPOSE : returns weekday (Sun - Sat) # GLOBAL VARS: none #------------------------------------------------------------------------------- sub getWeekDay{ my @date = split(" ", localtime(time)); my $day = $date[0]; return ($day); } #------------------------------------------------------------------------------- # Usage # # PURPOSE : print the Usage # PARAMS : none # GLOBAL VARS: none #------------------------------------------------------------------------------- sub Usage { print <<EOF Usage: $basename -b <base> [Optional Arguments] -p <parent> : name of the parent snapshot Optional Arguments: -n <prefix_name> : prefix of the new snapshot name (defaults to parent.18H) -s <suffix> : use "weekday" to have the day name as suffix (Sun - Sat) e.g. snap_acfs.pl -p scprod -n stout -s "weekday" will clone from /u02/acfs/.ACFS\snaps\stout to /u02/acfs/.ACFS\snaps\stout.Tue (or whatever the day is) e.g. snap_acfs.pl -n stout -p stout.Mon will clone from /u02/acfs/.ACFS\snaps\stout.Mon to /u02/acfs/.ACFS\snaps\stout e.g. snap_acfs.pl -n stout2 -p stout will clone from /u02/acfs/.ACFS\snaps\stout to /u02/acfs/.ACFS\snaps\stout2 EXISTING SNAPSHOT WILL BE DROPPED!! EOF } |
snap_databasae.pl
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 |
#!/u01/app/oracle/tvdtoolbox/tvdperl-Linux-x86-64-02.04.00-05.08.04/bin/tvd_perl # # Purpose..........: Create a new snapshot of a standby database by apply-off, backup controlfile to trace, copy init, acfs snap, apply-on # # snap_database.pl # -b <base> # -n <name> : prefix of the snapshot # -s <suffix> : optional, use "weekday" to have the day name as suffix (Sun - Sat) # # e.g. snap_database.pl -b stout -n stout_save -s "weekday" # will clone from /u02/acfs/.ACFS/snaps/stout # to /u02/acfs/.ACFS/snaps/stout_save.Tue (or whatever the day is) # # EXISTING SNAPSHOT WILL BE DROPPED!! # #use strict; use File::Copy; use Net::SMTP; use Sys::Hostname; use Getopt::Std 'getopts'; use File::Basename; use DBI; use DBD::Oracle qw(:ora_session_modes); my $CloneDIR; # predefine rootDir variable BEGIN { use FindBin qw($Bin); # get the current path of script use Cwd 'abs_path'; $CloneDIR = abs_path("$Bin/.."); # get the absolut rood path to clone directory } my $CloneLOGDir = $CloneDIR."/log"; # LOG Directory my $baseACFS = "/u02/acfs"; my $basename = basename($0, ".pl"); my $PrefixName; my $BaseDB; my $SuffixName; my $SnapshotName; my %opts; my $dbh; my $db_create_file_dest; my $db_unique_name; my $cmd; my $syspwd="Vagrant1_"; my $SnapError=0; my $SnapDir; my $ControlfileTrace = "control.trc"; my $ORACLE_HOME = "/u01/app/oracle/product/12.2.0.1/dbhome_1"; my $InitName = "init.ora"; my $warnings = 0; ################################################################################ # Main ################################################################################ my $StartDate = localtime; &DoMsg ("Start of $basename.pl"); unless ( open (MAINLOG, ">>$CloneLOGDir/$basename.log") ) { &DoMsg ("Can't open Main Logfile $CloneLOGDir/$basename.log"); exit 1; } # Process command line arguments if ( ! defined @ARGV ) { &Usage; exit 1; } getopts('b:n:s:', \%opts); if ($opts{"b"}) { $BaseDB = lc($opts{"b"}); } else { &DoMsg ("Base DB not given!"); &Usage; exit 1; } if ($opts{"n"}) { $PrefixName = lc($opts{"n"}); } else { $PrefixName = "${BaseDB}_save"; } if ($opts{"s"}) { $SuffixName = lc($opts{"s"}); if ( $SuffixName eq "weekday" ) { $SuffixName = lc(&getWeekDay); } $SuffixName = "." . $SuffixName; } else { $SuffixName = ""; } $SnapshotName = "${PrefixName}${SuffixName}"; &DoMsg ("Base: $BaseDB"); &DoMsg ("SnapshotName: $SnapshotName"); &ConnectDB ; ### checking that the database is mounted and physical standby my $DBstatus= &QueryOneValue('select status from v$instance'); unless ( $DBstatus eq "MOUNTED" ) { &DoMsg ("Database is not in MOUNTED status, this is unexpected. Exiting."); exit 1 } my $DBrole= &QueryOneValue('SELECT database_role FROM v$database'); unless ( $DBrole eq "PHYSICAL STANDBY" ) { &DoMsg ("Database role is not PHYSICAL STANDBY, this is unexpected. Exiting."); exit 1 } $db_create_file_dest= &QueryOneValue(qq{SELECT value FROM v\$parameter2 WHERE name='db_create_file_dest'}); &DoMsg ("db_create_file_dest: $db_create_file_dest"); $db_unique_name= &QueryOneValue(qq{SELECT value FROM v\$parameter2 WHERE name='db_unique_name'}); &DoMsg ("db_unique_name: $db_unique_name"); #unless ($dbh->do(qq{ALTER SESSION SYNC WITH PRIMARY}) ) { # &DoMsg ("Error in syncing the session with the primary"); # $warnings++; #} $cmd = qq{dgmgrl -echo sys/$syspwd "edit database $db_unique_name set state=\\\"APPLY-OFF\\\";"}; &DoMsg ($cmd); open( CMD, $cmd . " |"); &DoMsg (join("",<CMD>)); close (CMD); my $a=$?; #if ( $? != 0 ) { # &DoMsg ("Error in stopping apply on standby $BaseDB. Exiting."); # exit 1 #} $cmd = $CloneDIR."/bin/snap_acfs.pl -p $BaseDB -n $SnapshotName"; &DoMsg($cmd); open( CMD, $cmd . " |"); print (join("", <CMD>)); ## only print here as it logs and echoes its time as well close CMD; #if ( $? != 0 ) { # # track if error in creating the snapshot: we continue and do the apply-on anyway! # $SnapError=1; #} $SnapDir = $baseACFS . "/.ACFS/snaps/" . $SnapshotName; $ControlfileTrace = $SnapDir . "/" . $ControlfileTrace; $InitName = $SnapDir . "/" . $InitName; unless ($dbh->do(qq{ ALTER DATABASE BACKUP CONTROLFILE TO TRACE AS '$ControlfileTrace' REUSE RESETLOGS}) ) { &DoMsg ("Error in taking the controlfile trace $ControlfileTrace."); $warnings++; } unless ($dbh->do(qq{ CREATE PFILE='$InitName' FROM SPFILE }) ) { &DoMsg ("Error in creating the pfile $InitName."); $warnings++; } $cmd = qq{dgmgrl -echo sys/$syspwd "edit database $db_unique_name set state=\"APPLY-ON\""}; &DoMsg ($cmd); open( CMD, $cmd . " |"); &DoMsg (join("", <CMD>)); close CMD; #if ( $? != 0 ) { # &DoMsg ("Error in starting apply on standby $BaseDB. MANUAL INTERVENTION REQUIRED"); # exit 1 #} if ( $SnapError == 1 ) { &DoMsg ("There was an error in creating the snapshot. Exiting."); exit 1; } if ( $warnings != 0 ) { &DoMsg("There have been some warnings, but the procedure completed."); } else { &DoMsg("The procedure completed successfully."); } &DisconnectDB ; #------------------------------------------------------------------------------- # DoMsg # # PURPOSE : echo with timestamp YYYY-MM-DD_H24:MI:SS # PARAMS : $*: the messages # GLOBAL VARS: none #------------------------------------------------------------------------------- sub DoMsg { my $msg = shift; my $timestamp = &getTimestamp; print ("$timestamp $msg\n"); if (fileno(MAINLOG)) {print MAINLOG "$timestamp $msg\n";} } #------------------------------------------------------------------------------- # getTimestamp # # PURPOSE : returns timestamp in different formats # PARAMS : format_parm # GLOBAL VARS: none #------------------------------------------------------------------------------- sub getTimestamp { # # Format 1: dd-mm-yyyy_hh24:mi:ss # Format 2: dd.mm.yyyy_hh24miss # Format 3: dd.mm.yyyy # Format 4: hh24:mi:ss # Rest: dd.mm.yyyy hh24:mi:ss (default) # my $Parm = shift; my $date; my $date2; my $heure; my $heure2; my ($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst); if ( length($Parm) > 1 ) { ($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime($Parm); } else { ($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime; } $date = (sprintf "%2.0d",($mday)).".".(sprintf "%2.0d",($mon+1)).".".($year+1900); $date =~ s/ /0/g; $date2 = (sprintf "%2.0d",($mday))."-".(sprintf "%2.0d",($mon+1))."-".($year+1900); $date2 =~ s/ /0/g; $heure = (sprintf "%2.0d",($hour)).":".(sprintf "%2.0d",($min)).":".(sprintf "%2.0d",($sec)); $heure =~ s/ /0/g; $heure2 = (sprintf "%2.0d",($hour)).(sprintf "%2.0d",($min)).(sprintf "%2.0d",($sec)); $heure2 =~ s/ /0/g; if ($Parm eq "1") { return ($date2."_".$heure) } elsif ($Parm eq "2") { return ($date."_".$heure2) } elsif ($Parm eq "3") { return ($date) } elsif ($Parm eq "4") { return ($heure) } else { return ($date." ".$heure) }; } #------------------------------------------------------------------------------- # getWeekDay # # PURPOSE : returns weekday (Sun - Sat) # GLOBAL VARS: none #------------------------------------------------------------------------------- sub getWeekDay{ my @date = split(" ", localtime(time)); my $day = $date[0]; return ($day); } #------------------------------------------------------------------------------- # Usage # # PURPOSE : print the Usage # PARAMS : none # GLOBAL VARS: none #------------------------------------------------------------------------------- sub Usage { print <<EOF Usage: $basename -b <base> [Optional Arguments] -b <base> : name of the base database Purpose: Create a new snapshot of a standby database by apply-off, acfs snap, backup controlfile to trace, copy init, apply-on. Optional Arguments: -n <prefix_name> : prefix of the new snapshot name -s <suffix> : use "weekday" to have the day name as suffix (Sun - Sat) examples: snap_database.pl -b stout -n stout.18h -s "weekday" will clone from /u02/acfs/.ACFS/snaps/stout to /u02/acfs/.ACFS/snaps/stout.18h.Tue (or whatever the day is) $basename -b stout -s "weekday" will clone from /u02/acfs/.ACFS/snaps/stout to /u02/acfs/.ACFS/snaps/stout_save.Wed (or whatever the day is) EXISTING SNAPSHOT WILL BE DROPPED!! EOF } sub ConnectDB { # DB connection # $ENV{ORACLE_SID}=$BaseDB; $ENV{ORACLE_HOME}=$ORACLE_HOME; delete $ENV{TWO_TASK}; &DoMsg ("Connecting to DB $BaseDB"); unless ($dbh = DBI->connect('dbi:Oracle:', "sys", $syspwd, {PrintError=>0, AutoCommit => 0, ora_session_mode => ORA_SYSDBA})) { &DoMsg ("Error connecting to DB: ". $DBI::errstr); exit(1); } #&DoMsg ("Connected to DB $BaseDB"); } sub QueryOneValue { my $sth; my $query = shift; unless ($sth = $dbh->prepare ($query)) { &DoMsg ("Error preparing statement $query: ".$dbh->errstr); } $sth->execute; my ($result) = $sth->fetchrow_array; return $result; } sub DisconnectDB { $dbh->disconnect; } |
clone_from_snap.pl
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 |
#!/u01/app/oracle/tvdtoolbox/tvdperl-Linux-x86-64-02.04.00-05.08.04/bin/tvd_perl use File::Copy; use File::Path qw(mkpath rmtree); use Net::SMTP; use Sys::Hostname; use Getopt::Std 'getopts'; use File::Basename; use DBI; use DBD::Oracle qw(:ora_session_modes); my $CloneDIR; # predefine rootDir variable BEGIN { use FindBin qw($Bin); # get the current path of script use Cwd 'abs_path'; $CloneDIR = abs_path("$Bin/.."); # get the absolut rood path to clone directory } my $CloneLOGDir = $CloneDIR."/log"; # LOG Directory my $baseACFS = "/u02/acfs"; my $basename = basename($0, ".pl"); my $BaseDB; my $SnapshotName; my $DestDB; my $DestPath; # contains the final snapshot destination my $oraenv = '/usr/local/bin/oraenv'; my $crsctl = '/u01/app/grid/12.2.0.1/bin/crsctl'; my $ORACLE_HOME = '/u01/app/oracle/product/12.2.0.1/dbhome_1'; my %opts; my $dbh; my $db_create_file_dest; my $db_unique_name; my $cmd; my $SnapError=0; my $SnapDir; my $ControlfileTrace = "control.trc"; my $InitName = "init.ora"; my $warnings = 0; my $foo; my $dbUniqueName; ################################################################################ # Main ################################################################################ my $StartDate = localtime; &DoMsg ("Start of $basename.pl"); unless ( open (MAINLOG, ">>$CloneLOGDir/$basename.log") ) { &DoMsg ("Can't open Main Logfile $CloneLOGDir/$basename.log"); exit 1; } # b: base db # u: source database db_unique_name. if empty, will try to get it dynamically # s: snapshot name # d: destination name # Process command line arguments if ( ! defined @ARGV ) { &Usage; exit 1; } getopts('b:s:d:u:', \%opts); if ($opts{"b"}) { $BaseDB = $opts{"b"}; } else { &DoMsg ("Base DB not given!"); &Usage; exit 1; } if ($opts{"s"}) { $SnapshotName = $opts{"s"}; } else { &DoMsg ("Snapshot Name not given!"); &ListSnapshots; exit 1; } if ($opts{"d"}) { $DestDB = $opts{"d"}; } else { &DoMsg ("Dest DB not given!"); &Usage; exit 1; } if ($opts{"u"}) { $dbUniqueName = $opts{"u"}; } else { &DoMsg ("db_unique_name not given, try to get it dynamically"); &ConnectDB ; $dbUniqueName= &QueryOneValue(qq{SELECT value FROM v\$parameter2 WHERE name='db_unique_name'}); &DisconnectDB ; } # show the parameters &DoMsg ("Base: $BaseDB"); &DoMsg ("SnapshotName: $SnapshotName"); &DoMsg ("Dest: $DestDB"); &DoMsg ("db_unique_name: $dbUniqueName"); # try to get the ORACLE_HOME of the resource my $cmd = "$crsctl status resource ora.".$DestDB.".db -f"; &DoMsg ($cmd); open( CMD, $cmd . " |"); my @output = <CMD>; close CMD; #if ( $? != 0 ) { # &DoMsg ("Destination database does not exist, please configure it with srvctl"); # exit 1; #} foreach (@output) { chomp($_); if ($_ =~ /^ORACLE_HOME=/) { ($foo, $ORACLE_HOME) = split (/=/); $ENV{ORACLE_HOME}=$ORACLE_HOME; &DoMsg ("OH = $ORACLE_HOME"); } } # try to get the status of the resource using srvctl my $cmd = "$ORACLE_HOME/bin/srvctl status database -d $DestDB"; &DoMsg ($cmd); open( CMD, $cmd . " |"); &DoMsg (join("", <CMD>)); close CMD; #if ( $? != 0 ) { # &DoMsg ("Destination database does not exist, please configure it"); # exit 1; #} # try to stop the dest db (will ignore errors) my $cmd = "$ORACLE_HOME/bin/srvctl stop database -d $DestDB -o abort -f"; &DoMsg ($cmd); open( CMD, $cmd . " |"); &DoMsg (join("", <CMD>)); close CMD; # drop/recreate the snapshot using snap_acfs.pl $cmd = "tvd_perl ".$CloneDIR."/bin/snap_acfs.pl -p $SnapshotName -n $DestDB"; &DoMsg($cmd); open( CMD, $cmd . " |"); print (join("", <CMD>)); ## only print here as it logs and echoes its time as well close CMD; #if ( $? != 0 ) { # &DoMsg("Error creating the new snapshot for $DestDB. Exiting."); # exit(1); #} $DestPath = $baseACFS . '/.ACFS/snaps/' . $DestDB; $ControlfileTrace = $DestPath.'/'.$ControlfileTrace; $InitName = $DestPath.'/'.$InitName; &DoMsg("Control file trace: $ControlfileTrace"); &DoMsg("Init file: $InitName"); ### remove old archives, redo_logs and control files! rmtree($baseACFS . '/fra/' . $DestDB , 1, 1 ); mkpath($baseACFS . '/fra/' . $DestDB ); ## HERE WE HAVE THE CONTROL AND INIT READY TO BE MODIFIED open(FILE, "<$ControlfileTrace"); my @ControlLines = <FILE>; close(FILE); # sed controlfile my @NewControlLines; push(@NewControlLines,"SET ECHO ON;\n"); push(@NewControlLines,"WHENEVER SQLERROR EXIT FAILURE;\n"); push(@NewControlLines,"CREATE SPFILE FROM PFILE='$InitName';\n"); foreach(@ControlLines) { # change the snapshot name in the paths $_ =~ s/u02\/$BaseDB/u02\/$DestDB/gi; # change the db_unique_name in the REDO paths $_ =~ s/fra\/$dbUniqueName/fra\/$DestDB/gi; # change the dbname in the create controlfile line $_ =~ s/CREATE CONTROLFILE.*$/CREATE CONTROLFILE REUSE SET DATABASE "$DestDB" RESETLOGS NOARCHIVELOG/; # everything after and including "recover database" can be skipped if ($_ =~ /^RECOVER DATABASE /) { last; } print ($_); push(@NewControlLines, $_); } push(@NewControlLines,"ALTER DATABASE OPEN RESETLOGS;\n"); push(@NewControlLines,"ALTER TABLESPACE TEMP ADD TEMPFILE SIZE 1G;\n"); push(@NewControlLines,"SELECT status FROM v\$instance;\n"); push(@NewControlLines,"QUIT;\n"); # write the new controlfile: open(FILE, ">$ControlfileTrace"); print FILE @NewControlLines; close(FILE); # delete old controlfile # no more necessary, deleted above unlink ($DestPath.'/control01.ctl'); # sed init file open(FILE, "<$InitName"); my @InitLines = <FILE>; close(FILE); @InitLines = grep(!/^$BaseDB/i, @InitLines); @InitLines = grep(!/^\*\.db_name/, @InitLines); @InitLines = grep(!/^\*\.db_unique_name/, @InitLines); @InitLines = grep(!/^\*\.dispatchers/, @InitLines); @InitLines = grep(!/^\*\.audit_file_dest/, @InitLines); @InitLines = grep(!/^\*\.fal_server/, @InitLines); @InitLines = grep(!/^\*\.fal_client/, @InitLines); @InitLines = grep(!/^\*\.log_archive_config/, @InitLines); @InitLines = grep(!/^\*\.log_archive_dest/, @InitLines); @InitLines = grep(!/^\*\.memory_target/, @InitLines); @InitLines = grep(!/^\*\.sga_target/, @InitLines); @InitLines = grep(!/^\*\.pga_aggregate_target/, @InitLines); @InitLines = grep(!/^\*\.service_names/, @InitLines); @InitLines = grep(!/^\*\.dg_broker_start/, @InitLines); my @NewInitLines; foreach(@InitLines ) { # change only the snapshot name in the paths $_ =~ s/u02\/$BaseDB/u02\/$DestDB/gi; $_ =~ s/fra\/$dbUniqueName/fra\/$DestDB/gi; print ($_); push(@NewInitLines, $_); } push(@NewInitLines, "*.db_name='$DestDB'\n"); push(@NewInitLines, "*.db_unique_name='$DestDB'\n"); push(@NewInitLines, "*.dispatchers='(PROTOCOL=TCP)(SERVICE=${DestDB}XDB)'\n"); push(@NewInitLines, "*.log_archive_dest_1='location=USE_DB_RECOVERY_FILE_DEST'\n"); push(@NewInitLines, "*.sga_target=1G\n"); push(@NewInitLines, "*.pga_aggregate_target=100M\n"); push(@NewInitLines, "*.service_names='$DestDB'\n"); #push(@NewInitLines, "*.\n"); # write the new init file open(FILE, ">$InitName"); print FILE @NewInitLines; close(FILE); $ENV{ORACLE_SID}=$DestDB; $cmd = "$ORACLE_HOME/bin/sqlplus / as sysdba \@$ControlfileTrace"; &DoMsg($cmd); open( CMD, $cmd . " |"); print (join("", <CMD>)); ## only print here as it logs and echoes its time as well close CMD; #if ( $? != 0 ) { # &DoMsg("Error creating the new snapshot for $DestDB. Exiting."); # exit(1); #} &DoMsg("New database snapshot $DestDB created successfully!"); &DoMsg("Starting using srvctl:"); my $cmd = "$ORACLE_HOME/bin/srvctl start database -d $DestDB"; &DoMsg ($cmd); open( CMD, $cmd . " |"); &DoMsg (join("", <CMD>)); close CMD; #if ( $? != 0 ) { # &DoMsg ("Destination database cannot be started using srvctl"); # exit 1; #} # #------------------------------------------------------------------------------- # DoMsg # # PURPOSE : echo with timestamp YYYY-MM-DD_H24:MI:SS # PARAMS : $*: the messages # GLOBAL VARS: none #------------------------------------------------------------------------------- sub DoMsg { my $msg = shift; my $timestamp = &getTimestamp; print ("$timestamp $msg\n"); if (fileno(MAINLOG)) {print MAINLOG "$timestamp $msg\n";} } #------------------------------------------------------------------------------- # getTimestamp # # PURPOSE : returns timestamp in different formats # PARAMS : format_parm # GLOBAL VARS: none #------------------------------------------------------------------------------- sub getTimestamp { # # Format 1: dd-mm-yyyy_hh24:mi:ss # Format 2: dd.mm.yyyy_hh24miss # Format 3: dd.mm.yyyy # Format 4: hh24:mi:ss # Rest: dd.mm.yyyy hh24:mi:ss (default) # my $Parm = shift; my $date; my $date2; my $heure; my $heure2; my ($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst); if ( length($Parm) > 1 ) { ($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime($Parm); } else { ($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime; } $date = (sprintf "%2.0d",($mday)).".".(sprintf "%2.0d",($mon+1)).".".($year+1900); $date =~ s/ /0/g; $date2 = (sprintf "%2.0d",($mday))."-".(sprintf "%2.0d",($mon+1))."-".($year+1900); $date2 =~ s/ /0/g; $heure = (sprintf "%2.0d",($hour)).":".(sprintf "%2.0d",($min)).":".(sprintf "%2.0d",($sec)); $heure =~ s/ /0/g; $heure2 = (sprintf "%2.0d",($hour)).(sprintf "%2.0d",($min)).(sprintf "%2.0d",($sec)); $heure2 =~ s/ /0/g; if ($Parm eq "1") { return ($date2."_".$heure) } elsif ($Parm eq "2") { return ($date."_".$heure2) } elsif ($Parm eq "3") { return ($date) } elsif ($Parm eq "4") { return ($heure) } else { return ($date." ".$heure) }; } #------------------------------------------------------------------------------- # getWeekDay # # PURPOSE : returns weekday (Sun - Sat) # GLOBAL VARS: none #------------------------------------------------------------------------------- sub getWeekDay{ my @date = split(" ", localtime(time)); my $day = $date[0]; return ($day); } #------------------------------------------------------------------------------- # callSQLPLUS # # PURPOSE : calls the rman utility # PARAMS : rman script name # GLOBAL VARS: ReturnStatus, LogFile #------------------------------------------------------------------------------- #sub callSQLPLUS { # my $script = shift; # open( SQL, "$ORACLE_HOME/bin/sqlplus /nolog \@$script |"); # &DoMsg (join("", <SQL>)); # if ( $? != 0 ) { $rc = 1; } # RC if last call create an error # close SQL; #} #------------------------------------------------------------------------------- # Usage # # PURPOSE : print the Usage # PARAMS : none # GLOBAL VARS: none #------------------------------------------------------------------------------- sub Usage { print <<EOF Usage: $basename -b <base> [Optional Arguments] -b <base> : db_name of the source database -d <base> : name of the destination database -s <snapshot> : name of the snapshot to be used Purpose: Create a new snapshot of a standby database by apply-off, backup controlfile to trace, copy init, acfs snap, apply-on. Optional Arguments: -u <db_unique_name> : name of the db_unique_name of the source database. if not specified, it will be taked from the source db, but it must be mounted! this parameter is used only for pattern replacement inside control file trace and init file. examples: $basename -b stout -s stout_save.Wed -d poug2648 will clone stout from snapshot $baseACFS/.ACFS/snaps/stout_save.Wed to poug2648 THE EXISTING DESTINATION DATABASE SNAPSHOT WILL BE DROPPED!! EOF } sub ConnectDB { # DB connection # $ENV{ORACLE_HOME}=$ORACLE_HOME; $ENV{ORACLE_SID}=$BaseDB; delete $ENV{TWO_TASK}; &DoMsg ("Connecting to DB $BaseDB"); &DoMsg ("OH: $ORACLE_HOME"); &DoMsg ("SID: $BaseDB"); unless ($dbh = DBI->connect('dbi:Oracle:', "sys", "Vagrant1_", {PrintError=>0, AutoCommit => 0, ora_session_mode => ORA_SYSDBA})) { &DoMsg ("Error connecting to DB: ". $DBI::errstr); exit(1); } #&DoMsg ("Connected to DB $BaseDB"); } sub QueryOneValue { my $sth; my $query = shift; unless ($sth = $dbh->prepare ($query)) { &DoMsg ("Error preparing statement $query: ".$dbh->errstr); } $sth->execute; my ($result) = $sth->fetchrow_array; return $result; } sub DisconnectDB { $dbh->disconnect; } |
Cheers
—
Ludovico