After a long, long wait, Oracle finally announced the availability of his new generation database. And looking at the new features, I think it will take several months before I’ll learn them all. The impressive number of changes brings me back to the release 10gR1, and I’m not surprised that Oracle has waited so long, I still bet that we’ll find a huge amount of bugs in the first release. We need for sure to wait a first Patchset, as always, before going production.
Does ‘c’ stand for cloud?
While Oracle has developed this release with the cloud in mind, the first word that comes out of my mind is “consolidation”. The new claimed feature Pluggable Database (aka Oracle Multitenancy) will be the dream of every datacenter manager along with CloneDB (well, it was somehow already available on 11.2.0.2) and ASM Thin_provisioned diskgroups.
But yes, it’s definitely the best for clouds
Other features like Flex ASM, Flex Cluster, several new security features, crossplatform backups… let imagine how deeply we can work to make private, multi-tenant clouds.
First steps, what changes with a typical installation

The process for a traditional standalone DB+ASM installation is the same as the old 11gR2: You’ll need to install the Grid Infrastructure first (and then take advantage of the Oracle Restart feature) and subsequently the Database installation.
The installation documentation is complete as always and is getting quite huge as the Grid Infrastructure capabilities increment.
To meet most installation prerequisites, Oracle has prepared again an RPM that does the dirty work:
oracle-rdbms-server-12cR1-preinstall-1.0-3.el6.x86_64.rpm
Oracle suggests to use Ksplice and also explicitly recommends to use the deadline I/O scheduler (it has been longtime a best practice but I can’t remember it was documented officially).
The splash screen has become more “red” giving a colorful experience on the installation process. 😉
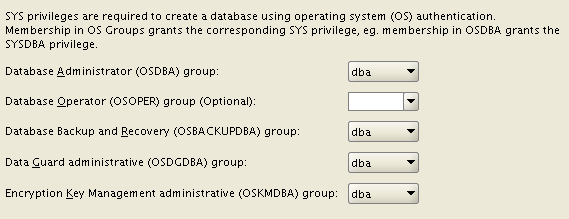
Once the GI is installed, the Database installation asks for many new OS groups: OSBACKUPDBA, OSDGDBA, OSKMDBA. This give you more possibilities to split administration duties, not specifying them will lead to the “old behavior”.
You can decide to use an ACFS filesystem for both the installation AND the database files (with some exceptions, e.g. Windows servers). So, you can take advantage of the snapshot features of ACFS for your data, provided that the performance is acceptable (I’ll try to test and blog more about this). You can use the feature Copy-On-Write to provide writable snapshot copies, directly embedding a special syntax inside the “create pluggable database” command. Unfortunately, Oracle has decided to deliver pluggable databases as an extra-cost option. :-/
The database creation with DBCA is even easier, you have an option for a very default installation, you can guess it uses templates with all options installed by default.
But the Hot topic is that you can create it as a “Container Database”. This is done by appending the keywords “enable pluggable database;” at the end of the create database command. The process will then put all the required bricks (creation of the pdb$seed database and so on), I’ll cover the topic in separate posts cause it’s the really biggest new feature.
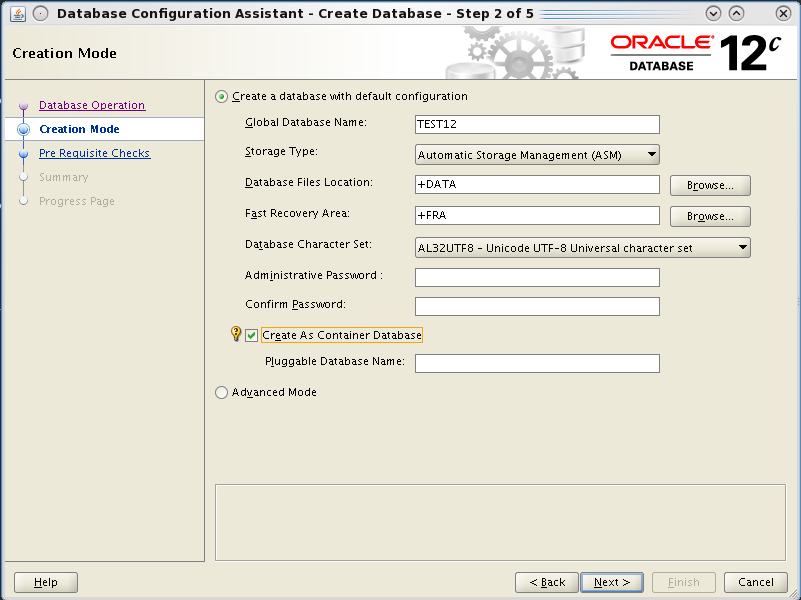
You can still use advanced mode to have the “old style” database creation, where you can customize your database.
If you try to create only the scripts and run them manually (that’s my habit), you’ll notice that SQL scripts are not run directly within the opened SQL*Plus session, but they’re run from a perl script that basically suppresses all the output to terminal, giving the impression of a cleaner installation. IMO it could be better only if everything runs fine.
|
1 |
host perl /u01/app/oracle/product/12.1.0/rdbms/admin/catcon.pl -l /u01/app/oracle/admin/CDBTEST/scripts -b catalog /u01/app/oracle/product/12.1.0/rdbms/admin/catalog.sql; |
Finally, I’ll get something familiar, but with a brand new release number! 🙂
|
1 2 3 4 5 6 7 8 9 10 |
[oracle@luc12c01 ~]$ sqlplus sys/*****@classic as sysdba SQL*Plus: Release 12.1.0.1.0 Production on Thu May 9 22:36:27 2013 Copyright (c) 1982, 2013, Oracle. All rights reserved. Connected to: Oracle Database 12c Enterprise Edition Release 12.1.0.1.0 - 64bit Production With the Partitioning, Automatic Storage Management, OLAP, Advanced Analytics and Real Application Testing options |
Stay tuned, I’ll write soon about some really interesting features of the new Oracle Database 12c!
Cheers
—
Ludo