The Oracle New Release Model is very young, and thus suffers of some small inconsistencies in the release naming.
Oracle already announced that 18c was a renaming of what was intended to be 12.2.0.2 in the original roadmap.
I though that 19c would have been 12.2.0.3, but now I have some doubts when looking at the local inventory contents.
I am consistently using my functions lsoh and setoh, as described in my posts:
What I do, basically, is to get the list of attached Oracle Homes from the Central Inventory, and then get some details (like version and edition) from the local inventory of each Oracle Home.
But now that Oracle 18.3 is out, my function shows release 18.0.0.0.0 when I try to get it in the previous way.
You can see that ACT_INST_VER is 12.2.0.4.0! does it indicate that 18.3 was planned to be 12.2.0.4?
like …
12.2.0.2 -> 18.1
12.2.0.3 -> 18.2
12.2.0.4 -> 18.3
?
This is in contrast with MOS Doc ID 230.1 that states that 18c was a “sort of” 12.2.0.2, so probably I get it wrong.
My first reflex has been to search, in the local inventory, where the string 18.3.0 was written down, but with my surprise, it is just a description, not a “real value”:
Last part of the blog series… let’s see how to put everything together and have a single script that creates and provisions Oracle Home golden images:
Review of the points
The scripts will:
let create a golden image based on the current Oracle Home
save the golden image metadata into a repository (an Oracle schema somewhere)
list the avilable golden images and display whether they are already deployed on the current host
let provision an image locally (pull, not push), either with the default name or a new name
Todo:
Run as root in order to run root.sh automatically (or let specify the sudo command or a root password)
Manage Grid Infrastructure homes
Assumptions
There is an available Oracle schema where the golden image metadata will be stored
There is an available NFS share that contains the working copies and golden images
Some variables must be set accordingly to the environment in the script
The function setoh is defined in the environment (it might be copied inside the script)
The Instant Client is installed and “setoh ic” correctly sets its environment. This is required because there might be no sqlplus binaries available at the very first deploy
Oracle Home name and path’s basename are equal for all the Oracle Homes
Repository table
First we need a metadata table. Let’s keep it as simple as possible:
Oracle PL/SQL
1
2
3
4
5
6
CREATETABLE"OH_GOLDEN_IMAGES"(
NAMEVARCHAR2(50BYTE)
,FULLPATHVARCHAR2(200BYTE)
,CREATEDTIMESTAMP(6)
,CONSTRAINTPK_OH_GOLDEN_IMAGESPRIMARYKEY(NAME)
);
Helpers
The script has some functions that check stuff inside the central inventory.
checks if a specific Oracle Home (name) is present in the central inventory. It is helpful to check, for every golden image in the matadata repository, if it is already provisioned or not:
The image creation would be as easy as creating a zip file, but there are some files that we do not want to include in the golden image, therefore we need to create a staging directory (working copy) to clean up everything:
Home provisioning requires, beside some checks, a runInstaller -clone command, eventually a relink, eventually a setasmgid, eventually some other tasks, but definitely run root.sh. This last task is not automated yet in my deployment script.
Shell
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
# ... some checks ...
# if no new OH name specified, get the golden image name
...
# - check if image to install exists
...
# - check if OH name to install is not already installed
Checking swap space: must be greater than 500 MB. Actual 16383 MB Passed
Preparing to launch Oracle Universal Installer from /tmp/OraInstall2018-02-06_06-04-33PM. Please wait ...Oracle Universal Installer, Version 12.1.0.2.0 Production
Copyright (C) 1999, 2014, Oracle. All rights reserved.
Checking swap space: must be greater than 500 MB. Actual 16383 MB Passed
Preparing to launch Oracle Universal Installer from /tmp/OraInstall2018-02-07_12-49-50PM. Please wait ...Oracle Univers al Installer, Version 12.1.0.2.0 Production
Copyright (C) 1999, 2014, Oracle. All rights reserved.
Applying sub-patch '26717470' to OH '/u01/app/oracle/product/12_1_0_2_BP180116'
ApplySession: Optional component(s) [ oracle.oid.client, 12.1.0.2.0 ] , [ oracle.has.crs, 12.1.0.2.0 ] n ot present in the Oracle Home or a higher version is found.
I hope you find it useful! The cool thing is that once you have the golden images ready in the golden image repository, then the provisioning to all the servers is striaghtforward and requires just a couple of minutes, from nothing to a full working and patched Oracle Home.
Why applying the patch manually?
If you read everything carefully, I automated the golden image creation and provisioning, but the patching is still done manually.
The aim of this framework is not to patch all the Oracle Homes with the same patch, but to install the patch ONCE and then deploy the patched home everywhere. Because each patch has different conflicts, bugs, etc, it might be convenient to install it manually the first time and then forget it. At least this is my opinion 🙂
Of course, patch download, conflict detection, etc. can also be automated (and it is a good idea, if you have the time to implement it carefully and bullet-proof).
In the addendum blog post, I will show some scripts made by Hutchison Austria and why I find them really useful in this context.
As I explained in the previous blog posts, from a manageability perspective, you should not change the patch level of a deployed Oracle Home, but rather install and patch a new Oracle Home.
With the same principle, Oracle Homes deployed on different hosts should have an identical patch level for the same name. For example, an Oracle Home /u01/app/oracle/product/EE12_1_0_2_BP171018 should have the same patch level on all the servers.
To guarantee the same binaries and patch levels everywhere, the simple solution that I am shoing in this series is to store copies of the Oracle Homes somewhere and use them as golden images. (Another approach, really different and cool, is used by Ilmar Kerm: he explains it here https://ilmarkerm.eu/blog/2018/05/oracle-home-management-using-ansible/ )
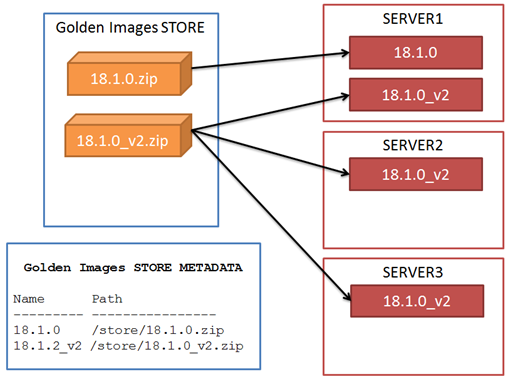
For this, we will use a Golden Image store (that could be a NFS share mounted on the Oracle Database servers, or a remote host accessible with scp, or other) and a metadata store.
When all the software is deployed from golden images, there is the guarantee that all the Homes are equal; therefore the information about patches and bugfixes might be centralized in one place (golden image metadata).
A typical Oracle Home lifecycle:
Install the software manually the first time
Create automatically a golden image from the Oracle Home
Deploy automatically the golden image on the other servers
When a new patch is needed:
Deploy automatically the golden image to a new Oracle Home
Patch manually (or automatically!) the new Oracle Home
Create automatically the new golden image with the new name
Deploy automatically the new golden image to the other servers
The script that automates this lifecycle does just two main actions:
Automates the creation of a new golden image
Deploys an existing image to an Oracle Home (either with a new path or the default one)
(optional: uninstall an existing Home)
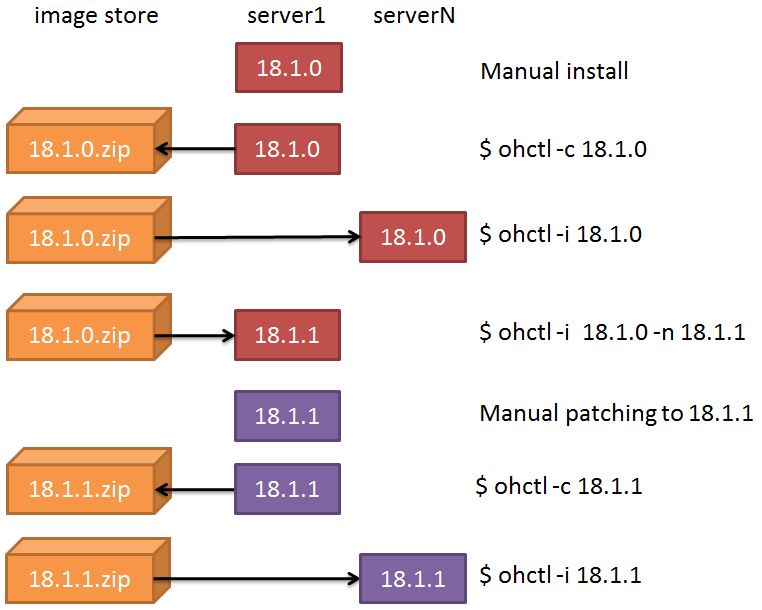
Let’s make a graphical example of the previously described steps:
Here, the script ohctl takes two actions: -c (creates a Golden Image) and -i (installs a Golden Image)).
The create action does the following steps:
Copies the content to a working directory
Cleans up logs, audits, etc.
Creates the zip file
Stores the zip file in a shared NFS repository
Inserts the metadata of the new golden image in a repository
The install action does the following steps:
Checks if the image is already deployed (plus other security checks)
Creates the new path based on the name of the image or the new name passed as argument
Unzips the content in the new Oracle Home
Runs the runInstaller –clone to attach the home in the central inventory and (optionally) set a new Home name
(optionally) Relinks the oracle binary with the RAC option
Run setasmgid if found
Other environment-specific tasks (e.g. dealing with TNS_ADMIN links)
By following this pattern, Oracle Home names and paths are clean and the same everywhere. This facilitates the deployment and the patching.
You can find the Oracle Home cloning steps in the Oracle Database documentation:
In the next blog post I will explain parts of the ohctl source code and give some examples of how I use it (and publish a link to the full source code 🙂 )
Having the capability of managing multiple Oracle Homes is fundamental for the following reasons:
Out-of-place patching: cloning and patching a new Oracle Home usually takes less downtime than stopping the DBs and patching in-place
Better control of downtime windows: if the databases are consolidated on a single server, having multiple Oracle Homes allows moving and patching one database at a time instead of stopping everything and doing a “big bang” patch.
Make sure that you have a good set of scripts that help you to switch correctly from one environment to the other one. Personally, I recommend TVD-BasEnv, as it is very powerful and supports OFA and non-OFA environments, but for this blog series I will show my personal approach.
Get your Home information from the Inventory!
I wrote a blog post sometimes ago that shows how to get the Oracle Homes from the Central Inventory (Using Bash, OK, not the right tool to query XML files, but you get the idea):
It uses a different approach from the oraenv script privided by Oracle, where you set the environment based on the ORACLE_SID variable and getting the information from the oratab. My setoh function gets the Oracle Home name as input. Although you can convert it easily to set the environment for a specific ORACLE_SID, there are some reason why I like it:
You can set the environment for an Oracle Home that it is not associated to any database (yet)
You can set the environment for an upgrade to a new release without changing (yet) the oratab
It works for OMS, Grid and Agent homes as well…
Most important, it will let you specify correctly the environment when you need to use a fresh install (for patching it as well)
In the previous example, there are two Database homes that have been installed without a specific naming convention (OraDb11g_home1, OraDB12Home1) and two that follow a specific one (12_1_0_2_BP170718_RON, 12_1_0_2_BP180116_OCW).
Naming conventions play an important role
If you want to achieve an effective Oracle Home management, it is important that you have everywhere the same ORACLE_HOME paths, names and patch levels.
The Oracle Home path should not include only the release number:
Oracle PL/SQL
1
/u01/app/oracle/product/12.1.0.2
If we have many Oracle Homes with the same release, how shall we call the other ones? There are several variables that might influence the naming convention:
Edition (EE, SE), RAC Option or other options, the patch type (formerly PSU, BP: now RU and RUR), eventual additional one-off patches.
Some ideas might be:
Oracle PL/SQL
1
2
3
/u01/app/oracle/product/EE12.1.0.2
/u01/app/oracle/product/EE12.1.0.2_BP171019
/u01/app/oracle/product/EE12.1.0.2_BP171019_v2
The new release model will facilitate a lot the definition of a naming convention as we will have names like:
Oracle PL/SQL
1
2
3
/u01/app/oracle/product/EE18.1.0
/u01/app/oracle/product/EE18.2.1
/u01/app/oracle/product/EE18.2.1_v2
Of course, the naming convention is not universal and can be adapted depending on the customer (e.g., if you have only Enterprise Editions you might omit this information).
Replacing dots with underscores?
You will see, at the end of the series, that I use Oracle Home paths with underscores instead of dots:
Oracle PL/SQL
1
2
3
/u01/app/oracle/product/EE12_1_0_2
/u01/app/oracle/product/EE12_1_0_2_BP171019
/u01/app/oracle/product/EE12_1_0_2_BP171019_v2
Why?
From a naming perspective, there is no need to have the Home that corresponds to the release number. Release, version and product information can be collected through the inventory.
What is really important is to have good naming conventions and good manageability. In my ideal world, the Oracle Home name inside the central inventory and the basename of the Oracle Home path are the same: this facilitates tremendously the scripting of the Oracle Home provisioning.
Sadly, the Oracle Home name cannot contain dots, it is a limitation of the Oracle Inventory, here’s why I replaced them with underscores.
In the next blog post, I will show how to plan a framework for automated Oracle Home provisioning.
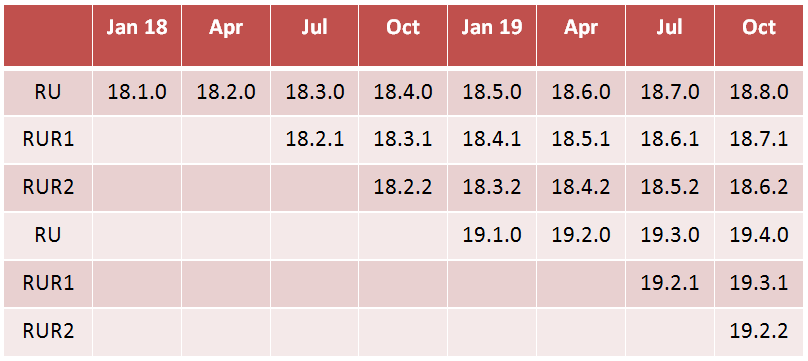
Starting with the upcoming next release (18c), the Oracle Database will be a yearly release. (18c, 19c, etc). New yearly releases will contain only new features ready to go, and eventually some new features for performance improvements (plus bug fixes and security fixes from the previous version.)
Quarterly, instead of Patch Set Updates (PSU) and Bundle Patches (BP), there will be the new Release Updates (RU). They will contain critical fixes, optimizer changes, minor functional enhancements, bug fixes, security fixes. The new Release Updates will be equivalent to what we have now with Bundle Patches.
The Release Updates will be released during the whole lifetime of the feature release, according to the roadmap (2 years or 5 years depending on whether the release is in Long Term Support (LTS) or not). There will be a Long Term Support release every few years. The first two will probably be Oracle 19c and Oracle 23c (I am deliberately supposing that the c will still be relevant 🙂 ).
Beside Release Updates, there will be the new Release Update Revisions (RUR), that according to what I have read until now, will be released “at least” quarterly. Release Update Revisions will contain only regression fixes for bugs introduced by RUs and new security fixes, very close to what we have now with Patch Set Updates.
Release Update Revisions will cover ONLY 6 months, after that it will be necessary to upgrade to a newer Release Update or to a newer major release. Oracle introduced this change to reduce the complexity of their release management.
This leads to a few important things:
There will be no more than two RURs for each RU (e.g. 18.2 will have only 18.2.1 and 18.2.2)
If applying a RUR, after 6 months at latest, the DBs must be patched to a greater level of RU.
Applying the second RUR of each RU (e.g. 18.2.2 -> 18.3.2 -> 18.4.2) is the most conservative approach whilst keeping up to date with the latest critical fixes.
How will the new release model impact the patching strategy?
It is clear that it will be complex to keep the same major upgrade frequency as today (I expect it to increase). There have been from 3 to 5 years between each major release so far, and switching to a yearly release is a big change.
But the numbering will be easier: 18.3.2 is much more readable/maintainable than 12.2.0.3.BP180719 and, despite it does not contain an explicit date, it keeps it easy to understand the “distance” with the latest release.
So we will have, on one side, the need to upgrade more frequently. But on the other side, the upgrades might be easier than how they are now. One thing is sure, however: we will deal with many more Oracle Homes with different patch levels.
The new release model will bring us a unique opportunity to reinvent our procedures and scripts for Oracle Home management, to achieve a standardized and automated way to solve common problems like:
Multiple Oracle Homes coexistence (environment, naming conventions)
Automated binaries setup (via golden images or other automatic provisioning)
Database patches
Database upgrades
In the next post, I will show my idea of how Oracle Homes could be managed (with either the current or the new release model), making their coexistence easier for the DBAs.
Bonus: calculating the distance between releases
For a given release YY.x.z, the distance from its first release is ( x + z -1 ) quarters.
E.g.18.3.2 will be ( 3 + 2 – 1 ) = 4 quarters after the initial release date.
Across versions, assuming that each yearly release will be released in the same quarter, the distance between versions YY1.x1.z1 and YY2.x2.z2 is:
In the previous post I mentioned that having a central repository storing the Golden Images would be the best solution for the Oracle Home provisioning.
In this context, Oracle provides Rapid Home Provisioning: a product included in Oracle Grid Infrastructure that automates home provisioning and patching of Oracle Database and Grid Infrastructure Homes, databases and also generic software.
Oracle Rapid Home Provisioning simplifies tremendously the software provisioning: you can use it to create golden images starting from existing installations and then deploy them locally, across different nodes, on local or remote clusters, standalone servers, etc.
Having a central store with enforced naming conventions ensures software standardization across the whole Oracle farm, and makes patching easier with less risks. Also, it allows to patch existing databases, moving them to Oracle Homes with a higher patch level, and taking care of service draining and rolling upgrades when RAC or RAC One Node deployments exist. Multiple databases can be patched in a single batch using one single rhpctl command.
I will not explain the technical details of Rapid Home Provisioning implementation operation. I already did a webinar a couple of years ago for the RAC SIG:
Burt Clouse, the RHP product manager, did a presentation as well about Rapid Home Provisioning 12c Release 2, that highlights some new features that the product was missing in the first release:
More details about the new features can be found here:
If rapid home provisioning is so powerful, what makes it less appealing for most users?
In my opinion (read: very own personal opinion 🙂 ), there are two main factors:
First: The technology stack RHP is relying on is quite complex
Although Rapid Home Provisioning 12c Release 2 allows Oracle Home deployments on standalone servers (it was not the case with 12c Release 1), the Rapid Home Provisioning sever itself relies on Oracle Grid Infrastructure 12cR2. That means that there must be skills in the company to manage the full stack: Clusterware, ASM, ACFS, NFS, GNS, SCAN, etc. as well as the RHP Server itself.
Second: remote provisioning requires Lifecycle Management Pack (extra-cost) option licensed on all the RHP targets
If Oracle Homes are deployed on the same cluster that hosts the RHP Server, the product can be used at no extra cost. But if you have many clusters, or using standalone servers for your Oracle databases, then RHP can become pricey very quickly: the price per processor for Lifecycle Management Pack is 12’000$, plus support (pricelist April 2018). So, buying this management pack just to introduce Rapid Home Provisioning in your company might be an excessive investment.
Of course, depending on your needs, you can evaluate it and leverage its full potential and make a bigger return of investment.
Or, you might explore if it is viable to configure each cluster as Rapid Home Provisioning Server: in this case it would be free, but it will have the additional complexity layer on all your clusters.
For small companies, simple architectures and especially where Standard Edition is deployed (no Management Pack for Standard Edition!), a self-made, simpler solution might be a better choice.
In the next post, before going into the details of a hypothetical self-made implementation, I will introduce my thoughts about the New Oracle Database Release Model.
(*) Multiple times in this blog post I refer to a problem with new Oracle Home installs and rollback scripts.The problem has been fixed with PSU Jan 2017, I did not notice it before, sorry. Thanks to Martin Berger for the information
Let’s see some common approaches to Oracle Home patching.
First, how patches are applied
No, I will not talk about how to use opatch 🙂 It is an overview of the “high-level” methods… when you have multiple servers and (eventually) multiple databases per server.
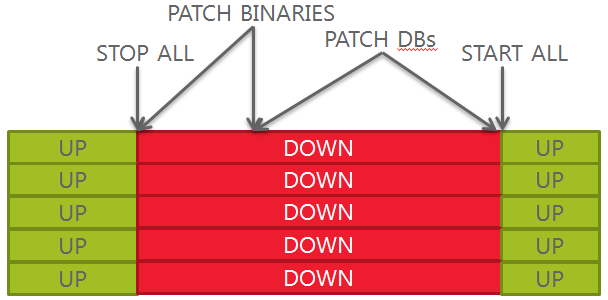
Worst approach (big bang)
1.Stop everything
2.In-place binaries patching
3.Database patching, “big bang” mode
4.Start everything
With this approach, you have a big downtime, a maintenance window hard to get (all applications are down at the same time), no control over a single database and no easy rollback in case your binaries get compromised/corrupted by the patch apply.
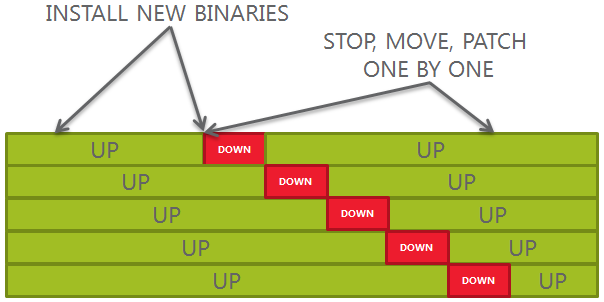
Another bad approach (new install and out-of-place patching)
1.Re-install binaries manually in a new path
2.Patch the new binaries
3.Stop, change OH, patch databases one by one
4.Decommission old binaries
This approach is much better than the previous one, but still has some pitfalls:
If you have many servers and environments: doing it frequently might be a challenge
Rollback scripts are not copied automatically: the datapatch will fail unless you copy them by hand (*)
New installs introduce potential human error, unless you use unattended install with your own scripts
Do you like to run opatch apply all the time, after all?
Better approach (software cloning)
This approach is very close to the previous one, with the exception that the new Oracle Home is not installed from scratch, but rather cloned from an existing one. This way, the rollback scripts used by the datapatch binary will be there and there will be no errors when patching the databases. (*)
Another cool thing is that you can clone Oracle Homes across different nodes, so that you might have the same patch level everywhere without repeating the tedious tasks of upgrading the opatch, patching the binaries, etc. etc.
But still, you have to identify which Oracle Home you have to clone and keep track of the latest version.
Best approach (Golden Images)
The best approach would consist in having a central repository for your software, where you store every version of your Oracle Homes, one for each patch level.
Having a central repository allows to install the software ONCE and use a “clone, patch and store it” strategy. You can, for example, use only one server to do all the patching and then distribute your software images to the different database servers.
This is the concept of Golden Images used by Rapid Home Provisioning that will be in the scope of my next blog post.
Second, which patches are applied
Now that we have seen some Oracle Home patching approaches, is it worth to know which patches are important in a patching strategy.
It is better that you get used to the differences between PSU/BP and RU/RUR, by reading this valuable post from Mike Dietrich:
I will make the assumption that in every case, the critical patches should be applied quarterly, or at least once per year, in order to fix security bugs.
The conservative approach (stability and performance over improvements)
Prior to 12.2, in order to guarantee security and stability, the best approach was to apply only PSUs each quarter.
From 12.2, the most conservative approach is to apply the latest Release Update Review on top of the oldest as possible Release Update. Confusing? Things will be clearer when I’ll write about the 18c New Release Model in a few days…
The cowboy approach (improvements over stability and performance)
Sometimes Bundle Patches and Release Updates contain cool backports from the new releases; sometimes they contain just more bug fixes than the PSUs and RURs; sometimes they fix important stuff like disabling bad transformations that lead to wrong result bugs or other annoying bugs.
Personally, I prefer to include such improvements in my patching strategy: I regularly apply RU for releases >=12.2 and BP for releases <=12.1. Don’t call me cowboy, however 🙂
The incumbent approach (or why you cannot avoid one-offs)
It does not matter your patch frequency: sometimes you hit a bug, and the only solution is either to apply the one-off patch or the workaround, if available.
If you apply the one-off patch for a specific bug, from an Oracle Home maintenance point of view, it would be better to
apply the same one-off everywhere (read, all your Oracle Homes with the very same release), this makes your environment homogeneous.
or
use a clone of the Oracle Home with the one-off as basis to apply the release update and distribute it to the other servers.
Why?
Again, it is a problem with rollback scripts (*), with patch conflicts and also, of number of versions to maintain:Less paths, less error-prone!
There is, however, the alternative to one-offs: implementing the workaround instead of applying the patch. Most of the time the workaround consist in disabling “something” through parameters, or worse, hidden parameters (the underscore parameters that the support says you should not set, but advise to do all the time as workaround :-))
It might be a good idea to use the workaround instead of apply tha patch if you already know that the bug will be fixed in the next Release Update (for example), or that the workaround is so easy to implement that it is not worth to create another version of Oracle Home that will require special attention at the next quarter.
If you apply workarounds, anyway, be sure that you comment EXACTLY why, when and who, so you can decide to unset it at the next parameter review or maintenance… e.g.
Oracle PL/SQL
1
2
3
4
5
altersystemset"_px_groupby_pushdown"=off
comment='Ludo, 03.05.16: W/A for bug 18499088'scope=bothsid='*';
With this post, I am starting a new blog series about Oracle Database home management, provisioning, patching… Best (and worst) practices, common practices and blueprints from my point of view as consultant and, sometimes, as operational DBA.
I hope to find the time to continue (and finish) it 🙂
How often should you upgrade/patch?
Database patching and upgrading is not an easy task, but it is really important.
Many companies do not have a clear patching strategy, for several reasons.
Patching is time consuming
It is complex
It introduces some risks
It is not always really necesary
It leads to human errors
Oracle, of course, recommends to apply the patches quarterly, as soon as they are released. But the reality is that it is (still) very common to find customers that do not apply patches regularly.
With January 2018 Bundle Patch, you can fix 1883 bugs, including 56 “wrong results”bugs! I hope I will talk more about this kind of bugs, but for now consider that if you are not patching often, you are taking serious risks, including putting at risk your data consistency.
I will not talk about bugs, upgrade procedures, new releases here… For this, I recommend to follow Mike Dietrich’s blog: Upgrade your Database – NOW!
I would like rather to talk, as the title of this blog series states, about the approaches of maintaining the Oracle Homes across your Oracle server farm.
Common worst practices in maintaining homes
Maintaining a plethora of Oracle Homes across different servers requires thoughtful planning. This is a non-exhaustive list of bad practices that I see from time to time.
Installing by hand every new Oracle Home
Applying different patch levels on Oracle Homes with the same path
Not tracking the installed patches
Having Oracle Home paths hard-coded in the operational scripts
Not minding about Oracle Home path naming convention
Not minding about Oracle Home internal names
Copying Oracle Homes without minding about the Central Inventory
All these worst practices lead to what I like to call “patching madness”… that monster that makes regular patching very difficult / impossible.
THIS IS A SITUATION THAT YOU NEED TO AVOID:
Oracle PL/SQL
1
2
3
4
5
6
7
8
9
10
Server A
/u01/app/oracle/product/12.1.0 -> Home "OraHOme12C", contains clean 12.1.0.2
Server B
/u01/app/oracle/product/12.1.0.2 -> Home "OraHome1", contains 12.1.0.2.PSU161018
/u01/app/oracle/product/12.1.0.2.BP170117 -> Home "OraHome2", contains 12.1.0.2.BP170117
Server C
/u01/app/oracle/product/12.1.0 -> Home "OraHome1", contains clean 12.1.0.1
/u01/app/oracle/product/12.1.0.2 -> Home "DBHome_1", contains 12.1.0.2.BP170117
A better approach, would be starting having some naming conventions, e.g.:
Oracle PL/SQL
1
2
3
4
5
6
7
8
9
10
Server A
/u01/app/oracle/product/12.1.0.2 -> Home "Ora12cR2", contains clean 12.1.0.2
Server B
/u01/app/oracle/product/12.1.0.2.PSU161018 -> Home "Ora12cR2_PSU161018", contains 12.1.0.2.PSU161018
/u01/app/oracle/product/12.1.0.2.BP170117 -> Home "Ora12cR2_BP170117", contains 12.1.0.2.BP170117
Server C
/u01/app/oracle/product/12.1.0.1 -> Home "Ora12cR1", contains clean 12.1.0.1
/u01/app/oracle/product/12.1.0.2.BP170117 -> Home "Ora12cR2_BP170117", contains 12.1.0.2.BP170117
In the next blog post, I will talk about common patching patterns and their pitfalls.
It is clear now that the DELETE statement is not constructed properly. It should get the LAST_ARCHIVE_TS of the actual DBID being purged… but it takes the other one.
According to my tests, it does not use neither the correct timestamp for the dbid, nor get the oldest timestamp: it uses instead the timestamp of the first record found by the clause “WHERE AUDIT_TRAIL=’STANDARD AUDIT TRAIL'”. It depends on the physical location of the row in the table! Clearly a big mess… (PS, not sure 100%, but this is what I suppose)
So, I have tried to modify the archive time for DBID 0:
Afterwards, the timestamp in the where condition is correct and remains correct after subsequent executions of DBMS_AUDIT_MGMT.SET_LAST_ARCHIVE_TIMESTAMP.
Conclusions, IMPORTANT FOR THE DATABASE OPERATIONS:
The upgrade causes the unwanted lines with DBID=0 in the DBA_AUDIT_MGMT_LAST_ARCH_TS view.
Moreover, any duplicate changes the DBID: any subsequent execution of DBMS_AUDIT_MGMT.SET_LAST_ARCHIVE_TIMESTAMP in the duplicated database will lead to additional lines in the view.
This is what I plan to do now:
Whenever I upgrade from 11g to 12c, cleanup the data from DBA_AUDIT_MGMT_LAST_ARCH_TS and schedule the cleanup for DBID 0 as well
Whenever I duplicate a database, I execute a DELETE (without clauses) from DBA_AUDIT_MGMT_LAST_ARCH_T and a truncate of the table SYS.AUD$ (it is a duplicate, after all!)
Update 14.03.2018: After some exchanges with Nigel Bayliss, the behaviour described here has been filed as unpublished bug 27626925: OPTIMIZER ADAPTIVE STATS DEFAULT FALSE NOT HONORED WHEN ENABLED IN OCT OR JAN BP. It will be fixed starting with April’s bundle patch.
if you installled the patch 22652097 prior to apply the Bundle Patch 171018, the BP apply in the database should recognize that the patch was already in place and keep it activated. This is done through the fix control 26664361.
When fix_control 26664361:0 -> Patch 22652097 is not enabled: the parameter optimizer_adaptive_features (OAF) works
When fix_control 26664361:1 -> Patch 22652097 is enabled; optimizer_adaptive_features is discarded and the two new parameters have the priority: optimizer_adaptive_plans (OAP) and optimizer_adaptive_statistics (OAS).
In order to apply that patch on the remaining databases, we did:
alter system reset optimizer_adaptive_features;
alter system reset “_optimizer_dsdir_usage_control”;
Applied the patch on binaries and datapatch on the databases.
The result at this point was that:
optimizer_adaptive_features was not set
optimizer_adaptive_plans was set to true
optimizer_adaptive_statistics was set to false.
It might seems superflous to say, but it’s not, the SQL Plan Directives were not used anymore: no Adaptice Dynamic Sampling and no performance problems.
Bundle Patch 180116
Three weeks ago, we installled the last Bundle Patch in order to fix some Grid Infrastructure problems, and the BP, as described in Nigel’s note (and Mike Dietrich and many other bloggers :-)) contains the patch 22652097.
According to Nigel’s post, the patch installation should have detected that the patch 22652097 was already there and activate it.
And indeed, after we applied the BP, the fix_control 26664361 was set to 1 (that means that the patch 22652097 is enabled). So we went live with this setup without additional checks.
One week later, we started experiencing performance problems again. I noticed immediately that the Adaptive Dynamic Sampling was very aggressive again, and the SQL Plan Directives used again.
But the fix was there AND ENABLED!
After a few tests, I realized that the SPD is not used anymore if I set optimizer_adaptive_statistics EXPLICITLY to false.
optimizer_adaptive_statistics must be set explicitly, the default does not work
And here’s the proof:
I use once again the great SPD example by Tim Hall (sorry Tim, it’s not the first time that I steal your work 🙂 ) . You can find here:
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.Accept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.


![2018-05-03 16_26_38-Diaporama PowerPoint - [Présentation1]](https://www.ludovicocaldara.net/dba/wp-content/uploads/2018/05/2018-05-03-16_26_38-Diaporama-PowerPoint-Présentation1.png)