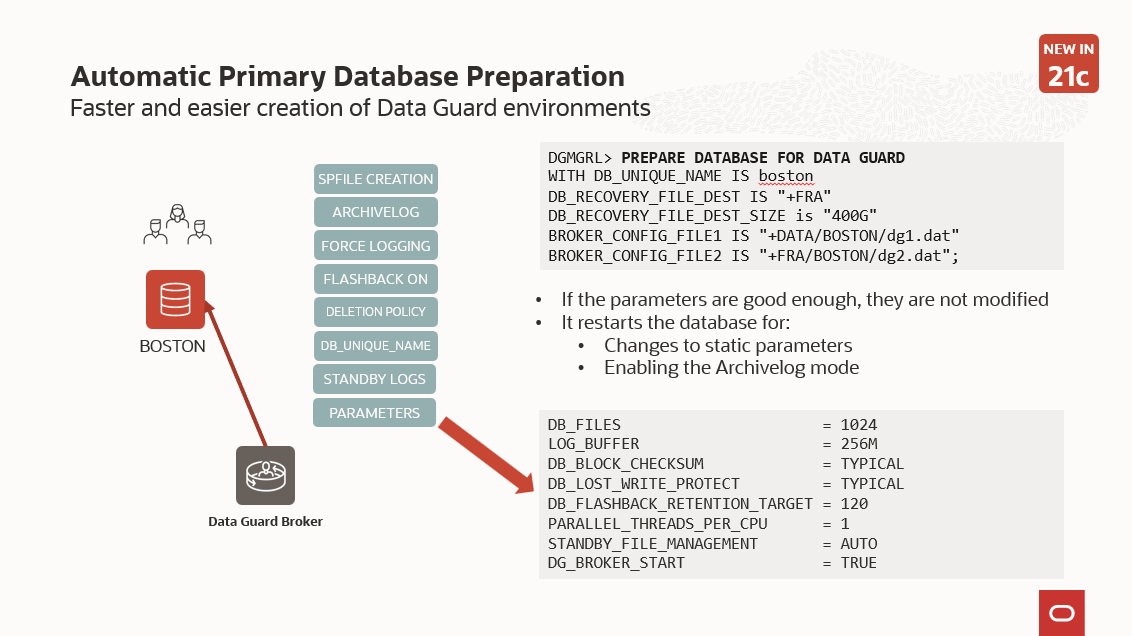
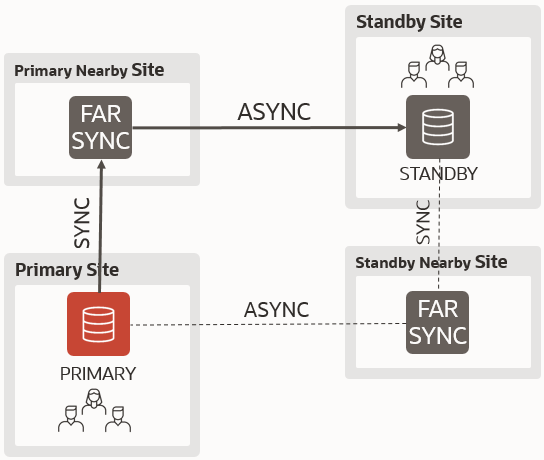
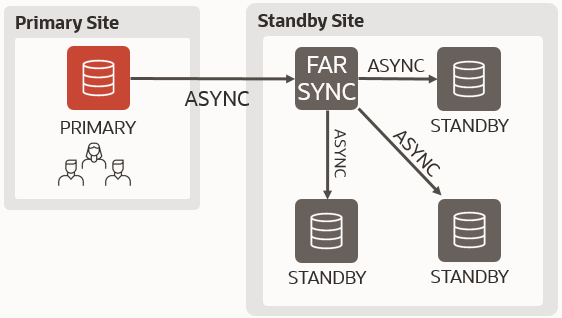
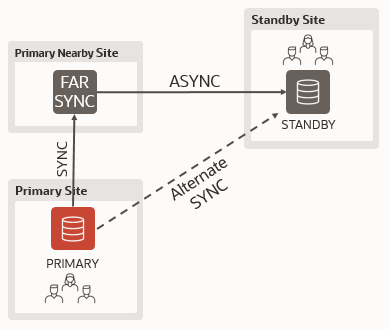
The key difference between a switchover and a failover in Data Guard is the synchronization between primary and standby to avoid data loss.
Switchover
A switchover is a planned event. The primary and standby databases synchronize to allow a smooth, lossless role reversal:
- The primary database stops the activity.
- It writes a “redo marker” to the redo stream.
- It flushes all the remaining redo to the standby.
- The standby applies all the redo and, upon reaching the marker, knows it’s up to date and can open as the new primary.
- Finally, the old primary becomes a standby and starts recovering changes from the new primary.
Failover
A failover usually happens after the primary becomes unavailable. Unlike a switchover, the new primary may not have all the latest redo from the old primary, even in synchronous mode because in-progress changes can exist past the last transmitted redo. As a result, their timelines diverge. The former primary (and possibly other standbys) must be reinstated to rejoin the configuration.
Flashback and Reinstate
Oracle’s Flashback Database feature allows you to rewind a database to a specific point in time. This makes recovering a failed primary much faster and easier because it does not require a full restore.
With Flashback enabled, the Data Guard Broker can quickly reinstate the former primary after a failover with a single command:
|
1 |
REINSTATE DATABASE {db_unique_name}; |
A customer recently asked how to reinstate a former primary when Flashback Logging is disabled.
Although we strongly recommend enabling Flashback Logging, some environments cannot support it due to storage constraints.
In such cases, you can still reinstate the database manually. Here’s how.
Step-by-step: reinstate a database from a backup and re-enable it in the broker
We are in a Maximum Performance configuration:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
DGMGRL> show config Configuration - adgvec_site0_adgvec_d7q_lhr Protection Mode: MaxPerformance Members: adgvec_site0 - Primary database adgvec_d7q_lhr - Physical standby database Fast-Start Failover: Disabled Configuration Status: SUCCESS (status updated 43 seconds ago) |
Let’s fail over:
|
1 2 3 4 5 6 7 8 9 10 |
DGMGRL> failover to adgvec_d7q_lhr immediate; 2025-12-16T09:58:55.928+00:00 Performing failover NOW, please wait... 2025-12-16T09:59:08.548+00:00 Failover succeeded, new primary is "adgvec_d7q_lhr". 2025-12-16T09:59:08.548+00:00 Failover processing complete, broker ready. DGMGRL> exit |
Then restart the former primary in MOUNT mode:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SQL> shutdown immediate; Database closed. Database dismounted. ORACLE instance shut down. SQL> startup mount; ORACLE instance started. Total System Global Area 15544938664 bytes Fixed Size 4939944 bytes Variable Size 2650800128 bytes Database Buffers 12750684160 bytes Redo Buffers 138514432 bytes Database mounted. |
The broker now says the former primary requires a reinstate:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
DGMGRL> show config Configuration - adgvec_site0_adgvec_d7q_lhr Protection Mode: MaxPerformance Members: adgvec_d7q_lhr - Primary database adgvec_site0 - Physical standby database (disabled) ORA-16661: The standby database must be reinstated. Fast-Start Failover: Disabled Configuration Status: SUCCESS (status updated 15 seconds ago) |
As I said, we can’t proceed with a normal reinstate if there’s no flashback:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DGMGRL> reinstate database adgvec_site0; 2025-12-16T10:07:22.733+00:00 Reinstating database "adgvec_site0", please wait... Error: ORA-16827: Flashback Database is disabled. Failed. 2025-12-16T10:07:22.942+00:00 Reinstatement of database "adgvec_site0" failed 2025-12-16T10:07:22.942+00:00 Reinstate processing complete, broker ready. |
Let’s restore! This is the only way to bring a database to a past point in time if there is no flashback logging.
First, we put the DB in nomount mode to restore the standby controlfile:
|
1 2 3 4 5 6 7 8 |
SQL> startup force nomount; ORACLE instance started. Total System Global Area 1.5545E+10 bytes Fixed Size 4939944 bytes Variable Size 2650800128 bytes Database Buffers 1.2751E+10 bytes Redo Buffers 138514432 bytes |
Then we wipe out the directory that contains the DB (careful with this command!)
|
1 |
$ rm -rf * /u02/app/oracle/oradata/adgvec_site0/ADGVEC_SITE0 |
We restore the standby controlfile and the database:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 |
RMAN> restore standby controlfile from service adgvec_d7q_lhr; restore standby controlfile from service adgvec_d7q_lhr; Starting restore at 16-DEC-25 using target database control file instead of recovery catalog allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=331 device type=DISK channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr channel ORA_DISK_1: restoring control file channel ORA_DISK_1: restore complete, elapsed time: 00:00:01 output file name=/u02/app/oracle/oradata/adgvec_site0/control01.ctl output file name=/u03/app/oracle/fast_recovery_area/ADGVEC_SITE0/control02.ctl Finished restore at 16-DEC-25 RMAN> alter database mount; released channel: ORA_DISK_1 Statement processed RMAN> restore database from service adgvec_d7q_lhr; restore database from service adgvec_d7q_lhr; Starting restore at 16-DEC-25 Starting implicit crosscheck backup at 16-DEC-25 allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=486 device type=DISK Crosschecked 6 objects Finished implicit crosscheck backup at 16-DEC-25 Starting implicit crosscheck copy at 16-DEC-25 using channel ORA_DISK_1 Finished implicit crosscheck copy at 16-DEC-25 searching for all files in the recovery area cataloging files... cataloging done List of Cataloged Files ======================= File Name: /u03/app/oracle/fast_recovery_area/ADGVEC_SITE0/autobackup/2025_07_25/o1_mf_s_1207415482_n87gotv5_.bkp File Name: /u03/app/oracle/fast_recovery_area/ADGVEC_SITE0/archivelog/2025_10_31/o1_mf_1_172_njbddl2f_.arc ... using channel ORA_DISK_1 channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr channel ORA_DISK_1: specifying datafile(s) to restore from backup set channel ORA_DISK_1: restoring datafile 00001 to /u02/app/oracle/oradata/adgvec_d7q_lhr/ADGVEC_D7Q_LHR/datafile/o1_mf_system_n87ggxdv_.dbf channel ORA_DISK_1: restore complete, elapsed time: 00:00:07 channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr channel ORA_DISK_1: specifying datafile(s) to restore from backup set channel ORA_DISK_1: restoring datafile 00002 to /u02/app/oracle/oradata/adgvec_d7q_lhr/ADGVEC_D7Q_LHR/32F00060B1F21FF6E0633A875E64E7C7/datafile/o1_mf_system_n87ggxhw_.dbf channel ORA_DISK_1: restore complete, elapsed time: 00:00:03 channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr channel ORA_DISK_1: specifying datafile(s) to restore from backup set channel ORA_DISK_1: restoring datafile 00003 to /u02/app/oracle/oradata/adgvec_d7q_lhr/ADGVEC_D7Q_LHR/datafile/o1_mf_sysaux_n87ggxn0_.dbf channel ORA_DISK_1: restore complete, elapsed time: 00:00:55 channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr channel ORA_DISK_1: specifying datafile(s) to restore from backup set channel ORA_DISK_1: restoring datafile 00004 to /u02/app/oracle/oradata/adgvec_d7q_lhr/ADGVEC_D7Q_LHR/32F00060B1F21FF6E0633A875E64E7C7/datafile/o1_mf_sysaux_n87ggxqm_.dbf channel ORA_DISK_1: restore complete, elapsed time: 00:00:03 channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr channel ORA_DISK_1: specifying datafile(s) to restore from backup set channel ORA_DISK_1: restoring datafile 00007 to /u02/app/oracle/oradata/adgvec_d7q_lhr/ADGVEC_D7Q_LHR/datafile/o1_mf_users_n87gh76c_.dbf channel ORA_DISK_1: restore complete, elapsed time: 00:00:01 channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr channel ORA_DISK_1: specifying datafile(s) to restore from backup set channel ORA_DISK_1: restoring datafile 00009 to /u02/app/oracle/oradata/adgvec_d7q_lhr/ADGVEC_D7Q_LHR/32F00060B1F21FF6E0633A875E64E7C7/datafile/o1_mf_undotbs1_n87gh97l_.dbf channel ORA_DISK_1: restore complete, elapsed time: 00:00:01 channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr channel ORA_DISK_1: specifying datafile(s) to restore from backup set channel ORA_DISK_1: restoring datafile 00011 to /u02/app/oracle/oradata/adgvec_d7q_lhr/ADGVEC_D7Q_LHR/datafile/o1_mf_undotbs1_n87ghb6x_.dbf channel ORA_DISK_1: restore complete, elapsed time: 00:00:01 channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr channel ORA_DISK_1: specifying datafile(s) to restore from backup set channel ORA_DISK_1: restoring datafile 00012 to /u02/app/oracle/oradata/adgvec_d7q_lhr/ADGVEC_D7Q_LHR/330D3A56F99F26B6E0635C08F40AF437/datafile/o1_mf_system_n87ghdl5_.dbf channel ORA_DISK_1: restore complete, elapsed time: 00:00:03 channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr channel ORA_DISK_1: specifying datafile(s) to restore from backup set channel ORA_DISK_1: restoring datafile 00013 to /u02/app/oracle/oradata/adgvec_d7q_lhr/ADGVEC_D7Q_LHR/330D3A56F99F26B6E0635C08F40AF437/datafile/o1_mf_sysaux_n87ghdny_.dbf channel ORA_DISK_1: restore complete, elapsed time: 00:00:45 channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr channel ORA_DISK_1: specifying datafile(s) to restore from backup set channel ORA_DISK_1: restoring datafile 00014 to /u02/app/oracle/oradata/adgvec_d7q_lhr/ADGVEC_D7Q_LHR/330D3A56F99F26B6E0635C08F40AF437/datafile/o1_mf_undotbs1_n87ghdrp_.dbf channel ORA_DISK_1: restore complete, elapsed time: 00:00:01 channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr channel ORA_DISK_1: specifying datafile(s) to restore from backup set channel ORA_DISK_1: restoring datafile 00015 to /u02/app/oracle/oradata/adgvec_d7q_lhr/ADGVEC_D7Q_LHR/330D3A56F99F26B6E0635C08F40AF437/datafile/o1_mf_users_n87ghhw8_.dbf channel ORA_DISK_1: restore complete, elapsed time: 00:00:15 Finished restore at 16-DEC-25 RMAN> |
Now let’s enable the freshly reinstated standby database:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
DGMGRL> enable database adgvec_site0; Enabled. DGMGRL> show configuration Configuration - adgvec_site0_adgvec_d7q_lhr Protection Mode: MaxPerformance Members: adgvec_d7q_lhr - Primary database adgvec_site0 - Physical standby database Warning: ORA-16809: Multiple warnings detected for the member. Fast-Start Failover: Disabled Configuration Status: WARNING (status updated 8 seconds ago) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
DGMGRL> show database verbose adgvec_site0 Database - adgvec_site0 Role: PHYSICAL STANDBY Intended State: APPLY-ON Transport Lag: (unknown) Apply Lag: 6 minutes 41 seconds (computed 18 seconds ago) Average Apply Rate: (unknown) Active Apply Rate: (unknown) Maximum Apply Rate: (unknown) Real Time Query: OFF Instance(s): adgvec Database Warning(s): ORA-16853: apply lag has exceeded specified threshold ORA-16856: transport lag could not be determined ORA-16826: apply service state is inconsistent with the DelayMins property ... Database Status: WARNING |
Oups, I made a mistake. The Real-Time Apply isn’t working. Of course! I also deleted the standby logs, so I need to clear them.
|
1 2 |
DGMGRL> edit database adgvec_site0 set state='APPLY-OFF'; Succeeded. |
|
1 2 3 |
SQL> alter database clear logfile group 4, group 5, group 6, group 7; Database altered. |
|
1 2 |
DGMGRL> edit database adgvec_site0 set state='APPLY-ON'; Succeeded. |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
DGMGRL> sql 'alter system switch logfile'; Succeeded. DGMGRL> show configuration verbose; Configuration - adgvec_site0_adgvec_d7q_lhr Protection Mode: MaxPerformance Members: adgvec_d7q_lhr - Primary database adgvec_site0 - Physical standby database Properties: BystandersFollowRoleChange = 'ALL' CommunicationTimeout = '180' ConfigurationSimpleName = 'adgvec_site0_adgvec_d7q_lhr' ConfigurationWideServiceName = 'adgvec_CFG' DrainTimeout = '0' ExternalDestination1 = '' ExternalDestination2 = '' FastStartFailoverAutoReinstate = 'TRUE' FastStartFailoverLagGraceTime = '0' FastStartFailoverLagLimit = '30' FastStartFailoverLagType = 'APPLY' FastStartFailoverPmyShutdown = 'TRUE' FastStartFailoverThreshold = '30' ObserverOverride = 'FALSE' ObserverPingInterval = '0' ObserverPingRetry = '0' ObserverReconnect = '0' OperationTimeout = '30' PrimaryDatabaseCandidates = '' PrimaryLostWriteAction = 'CONTINUE' TraceLevel = 'USER' Fast-Start Failover: Disabled Configuration Status: SUCCESS |
Everything looks good now.
HTH
Ludovico