Using the RMAN catalog is an option. There is a long discussion between DBAs on whether should you use the catalog or not.
But because I like (a lot) the RMAN catalog and I generally use it, I assume that most of you do it 😉
When you want to restore from the RMAN catalog, you need to get the DBID of the database you want to restore and, sometimes, also the incarnation key.
The DBID is used to identify the database you want to restore. The DBID is different for every newly created / duplicated database, but beware that if you duplicate your database manually (using restore/recover), you actually need to change your DBID using the nid tool, otherwise you will end up by having more than one database registered in the catalog with the very same DBID. This is evil! The DB_NAME is also something that you may want to make sure is unique within your database farm.
The Incarnation Key changes whenever you do an “open resetlogs”, following for example a flashback database, an incomplete recovery, or just a “open resetlogs” without any specific need.
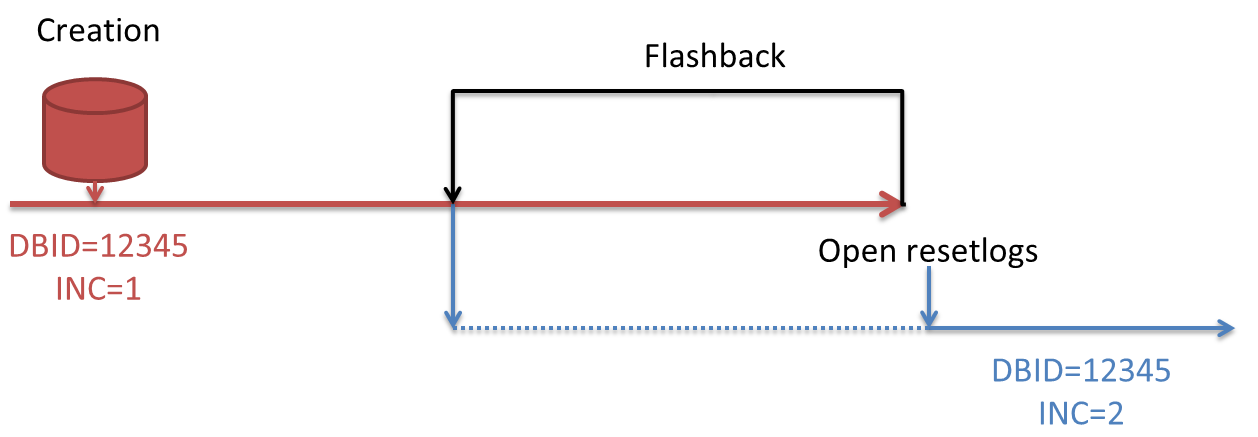
In the image, you can see that you may want to restore to a point in time after the open resetlogs (blue incarnation) or before it (red incarnation). Depending on which one you need to restore, you may need to use the command RESET DATABASE TO INCARNATION.
https://docs.oracle.com/database/121/RCMRF/rcmsynta2007.htm#RCMRF148
If you have a dynamic and big environment, you probably script your restores procedures, that’s why getting the DBID and incarnation key using the RMAN commands may be more complex than just querying the catalog using sqlplus.
How do I get the history of my database incarnations?
You can get it easily for all your databases using the handy hierarchical queries on the RMAN catalog (db names and ids are obfuscated for obvious reasons):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
SQL> SELECT lpad(' ',2*(level-1)) || TO_CHAR(DBINC_KEY) AS DBINC_KEY, db_key, db_name, TO_CHAR(reset_time,'YYYY-MM-DD HH24:MI:SS'), dbinc_status FROM rman.dbinc START WITH PARENT_DBINC_KEY IS NULL CONNECT BY prior DBINC_KEY = PARENT_DBINC_KEY ; DBINC_KEY DB_KEY DB_NAME TO_CHAR(RESET_TIME, DBINC_ST ------------------------- ---------- ---------- ------------------- -------- 356247416 356247380 A9EE272A 2011-09-24 18:22:58 PARENT 356247387 356247380 A9EE272A 2012-10-24 08:41:41 PARENT 1149458631 356247380 A9EE272A 2014-10-10 08:30:57 CURRENT 360319357 360319322 F5FD787F 2011-10-14 15:39:19 PARENT 360319323 360319322 F5FD787F 2012-11-08 18:57:26 PARENT 547928008 360319322 F5FD787F 2013-09-10 10:57:44 PARENT 576592237 360319322 F5FD787F 2013-11-20 14:54:05 ORPHAN 576613820 360319322 F5FD787F 2013-11-20 15:57:03 ORPHAN 584503796 360319322 F5FD787F 2013-11-27 13:57:53 CURRENT 364099232 364099231 25E64A7F 2012-11-20 08:01:49 PARENT 415031968 364099231 25E64A7F 2013-02-15 12:16:15 PARENT 456099512 364099231 25E64A7F 2013-05-03 12:19:52 CURRENT 366065362 366065336 3AE45141 2011-09-24 18:22:58 PARENT 366065337 366065336 3AE45141 2012-11-26 17:14:14 CURRENT 394067322 394067321 C34FFA7E 2013-01-10 17:18:11 CURRENT 402469086 402469073 D164DDB8 2011-09-24 18:22:58 PARENT 402469074 402469073 D164DDB8 2013-01-29 11:20:19 CURRENT 410147332 410147283 27984513 2011-09-24 18:22:58 PARENT 410147284 410147283 27984513 2013-02-08 11:12:38 CURRENT ... ... |
What about getting the correct DBID/DBINC_KEY pair for a specific database/time?
You can get the time windows for each incarnation using the lead() analytical function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
SQL> WITH dbids AS (SELECT TO_CHAR(dbinc.DBINC_KEY) AS DBINC_KEY, dbinc.db_key, dbinc.db_name, dbinc.reset_time, dbinc.dbinc_status, db.db_id FROM rman.dbinc dbinc JOIN rman.db db ON ( dbinc.db_key =db.db_key) ) select * from ( SELECT DBINC_KEY, db_name, db_id, reset_time, nvl(lead (reset_time) over (partition BY db_name order by reset_time),sysdate) AS next_reset FROM dbids ) ORDER BY db_name , reset_time ; DBINC_KEY DBNAME DB_ID RESET_TIME NEXTRESET ------------------------- ---------- ---------- ------------------- ------------------- 1173852671 1DF63C30 2507085371 2014-07-07 05:38:47 2015-01-16 07:29:01 1173852635 1DF63C30 2507085371 2015-01-16 07:29:01 2015-02-27 16:25:13 1244346785 1DF63C30 2531796824 2015-02-27 16:25:13 2015-02-27 16:25:13 1281775847 1DF63C30 2541221473 2015-02-27 16:25:13 2015-02-27 16:25:13 1233975755 1DF63C30 2528008262 2015-02-27 16:25:13 2015-02-27 16:25:13 1220896058 1DF63C30 2523244390 2015-02-27 16:25:13 2015-03-16 16:06:00 1188550385 1DF63C30 2507085371 2015-03-16 16:06:00 2015-07-17 08:06:00 1220896028 1DF63C30 2523244390 2015-07-17 08:06:00 2015-09-10 11:23:53 1233975725 1DF63C30 2528008262 2015-09-10 11:23:53 2015-10-23 07:46:34 1244346755 1DF63C30 2531796824 2015-10-23 07:46:34 2016-02-08 09:44:03 1281775817 1DF63C30 2541221473 2016-02-08 09:44:03 2016-02-15 10:13:49 1201139592 1D0776F6 2025503263 2014-07-07 05:38:47 2015-05-04 17:08:50 1201139578 1D0776F6 2025503263 2015-05-04 17:08:50 2015-06-02 08:48:07 1213295265 1D0776F6 2029287211 2015-06-02 08:48:07 2015-06-02 08:48:07 1256000477 1D0776F6 2044568865 2015-06-02 08:48:07 2015-06-02 08:48:07 1235940868 1D0776F6 2037421528 2015-06-02 08:48:07 2015-06-17 12:14:38 1213295230 1D0776F6 2029287211 2015-06-17 12:14:38 2015-09-18 15:46:34 1235940852 1D0776F6 2037421528 2015-09-18 15:46:34 2015-12-08 09:08:52 1256000461 1D0776F6 2044568865 2015-12-08 09:08:52 2016-02-15 10:13:49 1173653066 2D828C2C 1656607497 2014-07-07 05:38:47 2015-01-15 14:06:04 1173653052 2D828C2C 1656607497 2015-01-15 14:06:04 2015-06-02 08:48:07 1247872446 2D828C2C 1682603029 2015-06-02 08:48:07 2015-06-02 08:48:07 1218354231 2D828C2C 1671898993 2015-06-02 08:48:07 2015-06-02 08:48:07 1278227063 2D828C2C 1690479985 2015-06-02 08:48:07 2015-06-02 08:48:07 1219084145 2D828C2C 1672155073 2015-06-02 08:48:07 2015-06-02 08:48:07 1228714578 2D828C2C 1675699280 2015-06-02 08:48:07 2015-06-02 08:48:07 1211451469 2D828C2C 1669565762 2015-06-02 08:48:07 2015-06-02 08:48:07 1235422982 2D828C2C 1678113471 2015-06-02 08:48:07 2015-06-02 08:48:07 1228713810 2D828C2C 1675697673 2015-06-02 08:48:07 2015-06-02 08:48:07 1240749487 2D828C2C 1680107003 2015-06-02 08:48:07 2015-06-02 08:48:07 1255743496 2D828C2C 1685361979 2015-06-02 08:48:07 2015-06-10 13:37:08 1211451453 2D828C2C 1669565762 2015-06-10 13:37:08 2015-07-06 13:44:20 1218354215 2D828C2C 1671898993 2015-07-06 13:44:20 2015-07-09 12:52:19 1219084129 2D828C2C 1672155073 2015-07-09 12:52:19 2015-08-19 12:55:40 1228713794 2D828C2C 1675697673 2015-08-19 12:55:40 2015-08-19 13:22:27 1228714562 2D828C2C 1675699280 2015-08-19 13:22:27 2015-09-16 11:58:58 1235422966 2D828C2C 1678113471 2015-09-16 11:58:58 2015-10-08 13:44:29 1240749471 2D828C2C 1680107003 2015-10-08 13:44:29 2015-11-06 11:04:55 1247872430 2D828C2C 1682603029 2015-11-06 11:04:55 2015-12-07 09:27:27 1255743480 2D828C2C 1685361979 2015-12-07 09:27:27 2016-02-04 15:07:29 1278227047 2D828C2C 1690479985 2016-02-04 15:07:29 2016-02-15 10:13:49 |
With this query, you can see that every incarnation has a reset time and a “next reset time”.
It’s easy then to get exactly what you need by adding a couple of where clauses:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
SQL> WITH dbids AS (SELECT TO_CHAR(dbinc.DBINC_KEY) AS DBINC_KEY, dbinc.db_key, dbinc.db_name, dbinc.reset_time, dbinc.dbinc_status, db.db_id FROM rman.dbinc dbinc JOIN rman.db db ON ( --dbinc.dbinc_key=db.CURR_DBINC_KEY --AND dbinc.db_key =db.db_key) ) SELECT * FROM (SELECT DBINC_KEY, db_name, db_id, reset_time, NVL(lead (reset_time) over (partition BY db_name order by reset_time),sysdate) AS next_reset FROM dbids ) WHERE TO_DATE ('2016-01-20 00:00:00','YYYY-MM-DD HH24:MI;SS') BETWEEN reset_time AND next_reset AND db_name='1465419F' ORDER BY db_name , reset_time ; DBINC_KEY DB_NAME DB_ID RESET_TIME NEXT_RESET ------------------------- ---------- ---------- ------------------- ------------------- 1256014297 1465419F 1048383773 2015-12-08 11:03:55 2016-02-08 07:55:05 |
So, if I need to restore the database 1465419F until time 2016-01-20 00:00:00, i need to set DBID=1048383773 and reset the database to incarnation 1256014297.
Cheers
—
Ludo