I don’t like to publish small code snippets, but I’ve just rewritten one of my most used SQL scripts for SQL Server that gets the details about the last backup for every database (for both backup database and backup log).
It now makes use of with () and rank() over() to make it much easier to read and modify.
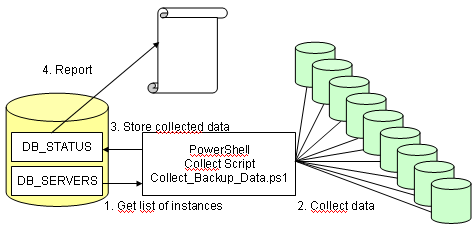
In my previous post I’ve shown how to collect data and insert it into a database table using PowerShell. Now it’s time to get some information from that data, and I’ve used TSQL for this purpose.
The backup exceptions
Every environment has some backup rules and backup exceptions. For example, you don’t want to check for failures on the model, northwind, adventureworks or distribution databases.
I’ve got the rid of this problem by using the “exception table” created in the previous post. The rules are defined by pattern matching. First we need to define a generic rule for our default backup schedules:
PgSQL
1
2
3
4
5
6
INSERTINTO[Tools].[dbo].[DB_Backup_Exceptions]
([InstanceName],[DatabaseName],[LastFullHours]
,[LastLogHours],[Description],[BestBefore])
VALUES
('%','%',36,12,'Default delays for all databases',NULL)
GO
In the previous example, we’ll check that all databases (‘%’) on all instances (again ‘%’) have been backed up at least every 36 hours, and a backup log have occurred in the last 12 hours. The description is useful to remember why such rule exists.
The “BestBefore” column allows to define the time limit of the rule. For example, if you do some maintenance and you are skipping some schedules, you can safely insert a rule that expires after X days, so you can avoid some alerts while avoiding also to forget to delete the rule.
PgSQL
1
2
3
4
5
6
INSERTINTO[Tools].[dbo].[DB_Backup_Exceptions]
([InstanceName],[DatabaseName],[LastFullHours]
,[LastLogHours],[Description],[BestBefore])
VALUES
('SERVER1','%',1000000,1000000,'Maintenance until 012.05.2013','2013-05-12 00:00:00')
GO
The previous rule will skip backup reports on SERVER1 until May 12th.
Oracle PL/SQL
1
2
3
4
5
6
INSERTINTO[Tools].[dbo].[DB_Backup_Exceptions]
([InstanceName],[DatabaseName],[LastFullHours]
,[LastLogHours],[Description],[BestBefore])
VALUES
('%','Northwind',1000000,1000000,'Don''t care about northwind',NULL)
GO
The previous rule will skip all reports on all Northwind databases.
Important: If multiple rules apply to the same database, the rule with a higher time threshold wins.
The queries
The following query lists the databases with the last backup full older than the defined threshold:
Checking database backups has always been one of the main concerns of DBAs. With Oracle is quite easy with a central RMAN catalog, but with other databases doing it with few effort can be a great challenge.
Some years ago I developed a little framework to control all SQLServer databases. This framework was based on Linux (strange but true!), bash, freetds, sqsh and flat configuration files. It’s still doing well its work, but not all SQLServer DBAs can deal with complex bash scripting, so a customer of mines asked me if I was able to rewrite it with a language Microsoft-like.
So I decided to go for a PowerShell script in conjunction with a couple of tables for the configuration and the data, and a simple TSQL script to provide HTML reporting. I have to say, I’m not an expert on PowerShell, but it’s far from being as flexible as other programming languages (damn, comparing to perl, python or php they have in common only the initial ‘P’). However I managed to do something usable.
The principle
This is quite simple: the PowerShell script looks up for the list of instance in a reference table, then it sequentially connect to and retrieves the data:
recovery mode
status
creation time
last full backup
last log backup
This data is merged into a table on the central repository. Finally, a TSQL script do some reporting.
Custom classes in powershell
One of the big messes with PowerShell is the lack of the definition for custom classes, this is a special mess if we consider that PowerShell is higly object-oriented. To define your own classes to work with, you have to define them in another language (C# in this example):
PowerShell
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
Add-Type@'
using System;
public class DatabaseBackup
{
public string instanceName;
public string databaseName;
public string recoveryMode;
public string status;
public DateTime creationTime;
public DateTime lastFull;
public DateTime lastLog;
private TimeSpan diff;
public double lastFullTotalHours () {
diff = DateTime.Now - lastFull;
return Math.Round(diff.TotalHours,2);
}
public double lastLogTotalHours () {
diff = DateTime.Now - lastLog;
return Math.Round(diff.TotalHours,2);
}
}
'@
For better code reading, I’ve put this definition in a separate file (DatabaseBackup.ps1).
where type ='L' and backup_finish_date <= getdate()
group by database_name
) c
on d.name = c.database_name
where d.name <> 'Tempdb'
order by [LastFull]";
I’ve also put this snippet in a separate file queries.ps1 to improve readability.
The tables
The first table (DB_Servers) can be as simple as a single column containing the instances to check. This can be any other kind of source like a corporate CMDB or similar.
The second table will contain the data collected. Off course it can be expanded!
The third table will contain some rules for managing exceptions. Such exceptions can be useful if you have situations like “all databases named northwind should not be checked”. I’ll show some examples in the next post.
$instances=invoke-sqlcmd-Query"select [name]=db_instance from db_servers"-ServerInstance$serverName-Database$databasename
Finally, for each instance we have to check, we trigger the function that collects the data and we insert the results in the central repository (I’m using a merge to update the existent records).
You can’t use the internal powershell of SQLServer because it’s not full compatible with powershell 2.0.
Check that the table db_status is getting populated
Limitations
The script use Windows authentication, assuming you are working with a centralized domain user. If you want to use the SQL authentication (example if you are a multi-tenant managed services provider) you need to store your passwords somewhere…
This script is intended to be used with single instances. It should works on clusters but I haven’t tested it.
Check the backup chain up to the tape library. Relying on the information contained in the msdb is not a reliable monitoring solution!!
In my next post we’ll see how to generate HTML reports via email and manage exceptions.
Hope you’ll find it useful.
Again PLEASE, if you improve it, kindly send me back a copy or blog it and post the link in the comments!
Windows Performance Monitor is an invaluable tool when you don’t have external enterprise monitoring tools and you need to face performance problems, whether you have a web/application server, a mail server or a database server.
But what I don’t personally like of it is what you get in terms of graphing. If you schedule and collect a big amount of performance metrics you will likely get lost in adding/removing such metrics from the graphical interface.
What I’ve done long time ago (and I’ve done again recently after my old laptop has been stolen 🙁 ) is to prepare a PHP script that parse the resulting CSV file and generate automatically one graph for each metric that could be found.
Unfortunately, most of Windows Sysadmin between you will disagree that I’ve done this using a Linux Box. But I guess you can use my script if you install php inside cygwin. The other tool you need, is rrdtool, again I use it massively to resolve my graphing needs.
How to collect your data
Basically you need to create any Data Collector within the Performance Monitor that generates a log file. You can specify directly a CSV file (Log format: Comma separated) or generate a BLG file and convert it later (Log format: Binary). System dumps are not used, so if you use the standard Performace template, you can delete it from your collection.
Remember that the more counters you take, the more the graph generation will take. The script does not run in parallel, so it will use only one core. Generally:
Where (Speed factor) is depending on both the CPU speed and the disk speed because of the huge number of syncs required to update several thousands of files. I’ve tried to reduce the number of rrdupdates by queuing several update values in a single command line and I’ve noticed an important increase of performances, but I know it’s not enough.
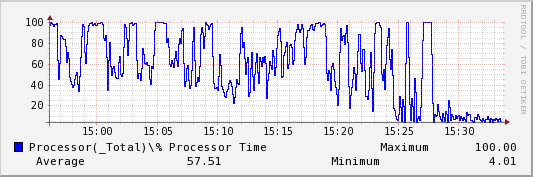
rrdtool graph/root/temp/LUDO/IPv4/Datagrams_Received_Unknown_Protocol.png--start"1366721762"--end"1366724017"--width453DEF:ds0=/root/temp/LUDO/IPv4/Datagrams_Received_Unknown_Protocol.rrd:value:LAST:step=5LINE1:ds0#0000FF:"IPv4\Datagrams Received Unknown Protocol" VDEF:ds0max=ds0,MAXIMUM VDEF:ds0avg=ds0,AVERAGE VDEF:ds0min=ds0,MINIMUM COMMENT:" " COMMENT:" Maximum " GPRINT:ds0max:"%6.2lf" COMMENT:" Average " GPRINT:ds0avg:"%6.2lf" COMMENT:" Minimum " GPRINT:ds0min:"%6.2lf"
534x177
...
Now it’s done!
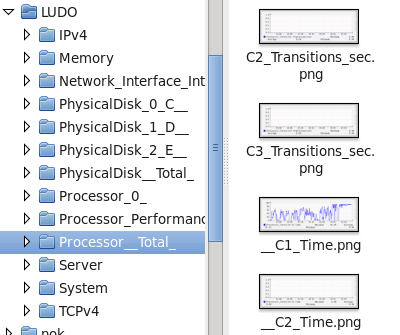
The script generate a folder with the name of the server (LUDO in my example) and a subfolder for each class of counters (as you see in Performance Monitor).
Inside each folder you will have a PNG (and an rrd) for each metric.
Important: The RRD are generated with a single round-robin archive with a size equal to the number of samples. If you want to have the rrd to store your historical data you’ll need to modify the script. Also, the size of the graph will be the same as the number of samples (for best reading), but limited to 1000 to avoid huge images.
Future Improvements
Would be nice to have a prepared set of graphs for standard graphs with multiple metrics (e.g. CPU user, system and idle together) and additional lines like regressions…
Download the script: process_l_php.txtand rename it with a .php extension.
Ok, Ok, as an “Oracle on Linux Certified Expert”, I’ve never been a great fan of SQLServer (I shouldn’t say this, I’m working on SQLServer since release 6.5…) and I’ve always hated the DOS command prompt.
However, things are changing fast after Microsoft released the Powershell some years ago. It’s surprising, now Windows powershell support new best of breed features like aliases and pipelines. 😀
Today Microsoft itself recommends Windows Core installations instead of the full ones, and also SQLServer 2012 comes with a lot of new Commandlets to manage your server.
So I’ve decided to move my first steps in the Powershell world and I’ve created a script for a customer that installs and configure a SQL2008 with a single Powershell script.
The very first line accepts named parameters. I’ve tried to reduce the number but I’ve preferred to take, as an example, different disks for different tasks.
Then I’ve put a little of interaction if some parameters are missing. In facts, I can launch my scripts without inline parameters and specify everything when prompted by the script.
The commented command is to get the installed features after the installation. No really need to display it, it works really well.
Dynamically prepare a configuration file
The unattended installation needs some parameters prepared in a configuration file.
This is likely where you will change most of your stuff depending on your standards:
Components, paths, service accounts, you can change everything or modify the script to accept also this variables as parameters.
The full documentation about filling the configuration file is on the MSDN:
Off course you’ll need an installation media downloaded from the Microsoft customers site with the correct License Keys and mounted somewhere. (remember the $sourceDir parameter?) I’ve decided to change the path in the directory containing the media and then change it back.
The Service Pack installation has been a little more painful, normally would be simple but actually the powershell prompt is returned immediately after firing the command. So, to wait it, I’ve had to figure out the name of the process (is the executable name without the file extension .exe), get its process id and wait for that process:
By default SQLServer starts listening on a dynamic port. If you have a default and you want to configure it without opening the configuration manager, you can do it with this snipplet that I’ve copied from sirSql (thank you for sharing this).
PowerShell
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
###############################
# change the TCP port at the end of the installation
"Success: SQL set to listen on TCP/IP port $port. Please restart the SQL service for changes to take effect."
}
Catch{Write-Warning"Unable to enable TCP/IP & set SQL to listen on port $port"}
}
####################
# Changing TCPport #
####################
"Changing TCP port to $port..."
changePort$hostName$instance$port
Adding your stuff at the end
Having the installation completed is in midstream. After the installation you may want to add tempfiles to your installation, modify your model database, add default accounts.
That’s up to you. If your scripts are identical you can execute them with sqlcmd.If you want to take benefit of the variables already set in the script you can execute them directly:
Well, I’ll never paste again all the content here, you can download the script HERE. Just change the file extension from .txt to .ps1.
I know it’s not a rock-solid procedure but it works well for my purposes, feel free to comment or review my script. Just, if you do some improvement on it, please share it and back-link this post!
Sometimes it’s hard to find enough time to write something or even to only THINK about writing something…
The following are the projects I have to complete before the deadline of December 17th (at least if I still want to go on vacation…)
A totally new Oracle 10gR2 RAC SE on Linux (OCFS2, ASM) including jboss frontends, backups, monitoring, documentation. (Servers are ready today).
A Disaster recovery architecture based on Dataguard with scripts based on rsync to do filesystem replication, with failover and failback, including backups, monitoring, documentation. (The server in DR site is reachable via network today).
A 17 server infrastructure (among others a RAC 10gR2 on linux) transfer from Milan datacenter to here. It’s planned for december 11th but I have to crosscheck backup and contingency requirements.
A 14 server infrastructure (based on Windows and SqlServer) transfer from Milan datacenter to here. To be planned in december.
A totally new cold failover cluster based on linux with Oracle DBMS and E-business suite (Servers will be provided soon, I hope!).
A new standalone Windows Server 64bit to outstand the 32bit allocation bottleneck for a 500Gb oracle database (Server will be provided not before december 10th).
Normally manage the day-by-day work, including replying to e-mails and answering the phone.
AARGH!!
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.Accept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.