2014 has been a great year, and it’s time to summarize it quickly.
A few numbers
24 blog posts
~37000 page views, >29000 visits
Speaker at 3 major conferences (#C14LV, #OOW14, #UKOUG_TECH14)
Speaker at 2 Trivadis internal conferences
Speaker at 2 local user group events
Speaker at an Oracle Business Breakfast
A total of 14 public speeches
I’ve been included in the ACE Program
3 RAC Attack workshops (one co-organized and another self-organized)
1 roundtable as co-organizer
2 T-shirt designed as gifts for 2 RAC Attack workshops
3 articles published
3 new websites for the community (The new @IT_OUG website and two still in progress)
Joined 3 user group boards (SOUG-R, ITOUG and RAC SIG (well, RAC SIG and ITOUG were actually in 2013…))
Countless new friends and/or contacts
UKOUG Tech 14 wrap-up
I’ve attended UKOUG Tech for the first time this year and have not found the time to blog about it. The conference is very good. There is a lot of good content, the agenda is great. But I’ve heard that the conference was better and bigger in the past, that’s why the UKOUG is going to move it back to Birmingham in 2015. I sincerely hope that they will get back the attendance this conference deserves.
Sadly, the RAC Attack has not been organized and advertised properly, so it has been a failure comparing to te previous ones I’ve attended/organized.
I have learnt many new technical things and I also have learned some lessons:
Never under-estimate the time it takes to say goodbye to everyone before running to the train station if you’re in a rush for the train to the airport
Even if the temperature is higher than in Switzerland, the wind-chill in Liverpool may get it seems much colder
Be careful when English people invite you for a quick beer, it’s not one beer and it’s not quick 🙂 (especially when you go back home at 2AM and pretend to be awake at 6AM, check-out at the hotel and prepare the demo for the first presentation in the morning)
Once again, I’ve met many new friends 🙂
6 months in the ACE program
I’ve spent my first 6 months in the ACE Program, it would take too much to talk about it. The best I’ve taken is not being in the program by itself. The best is the effort, the feedback and the new connections I’ve got as an active member of the community. Is a path that I recommend to all my Oracle-involved friends and colleagues because it’s very rewarding. I hope to be able to blog more about it in 2015 😉
A couple of pictures from 2014…
Projects for 2015
My fligths are already booked for the next Collaborate 15 #C15LV. See you in Vegas 🙂
About the ITOUG, the die is cast, I’ll certainly contribute more in Italian with articles, webcasts and general duties related to the OUG administration. Keep an eye on www.itoug.it
Ok, if you’re reading this post, you may want to read also the previous one that explains something more about the problem.
Briefly said, if you have a CDB running on ASM in a MAA architecture and you do not have Active Data Guard, when you clone a PDB you have to “copy” the datafiles somehow on the standby. The only solution offered by Oracle (in a MOS Note, not in the documentation) is to restore the PDB from the primary to the standby site, thus transferring it over the network. But if you have a huge PDB this is a bad solution because it impacts your network connectivity. (Note: ending up with a huge PDB IMHO can only be caused by bad consolidation. I do not recommend to consolidate huge databases on Multitenant).
So I’ve worked out another solution, that still has many defects and is almost not viable, but it’s technically interesting because it permits to discover a little more about Multitenant and Data Guard.
The three options
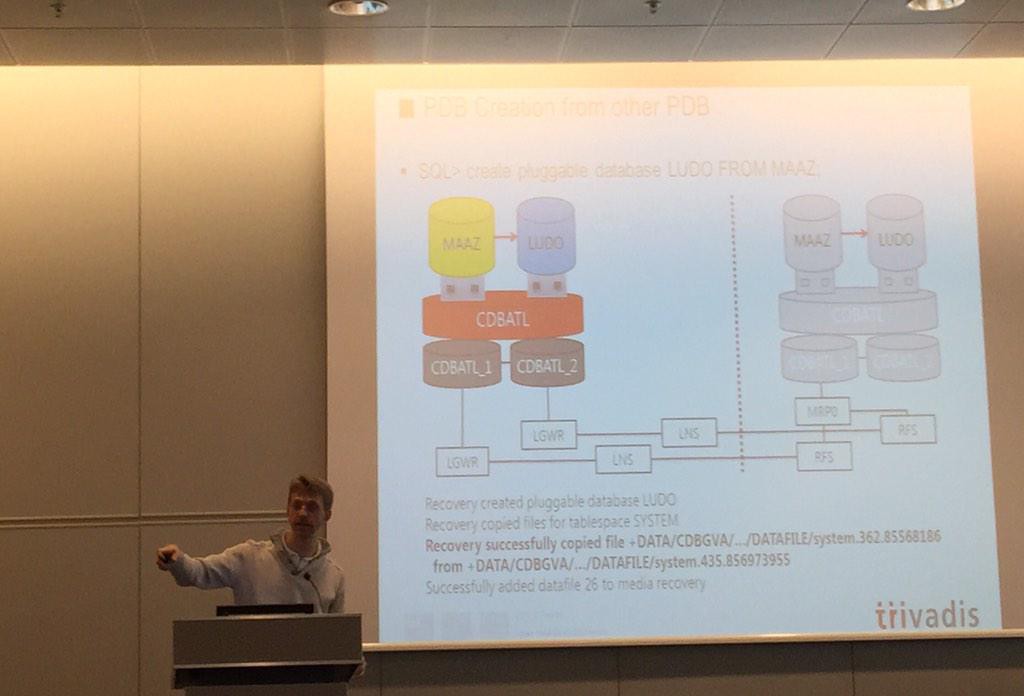
At the primary site, the process is always the same: Oracle copies the datafiles of the source, and it modifies the headers so that they can be used by the new PDB (so it changes CON_ID, DBID, FILE#, and so on).
On the standby site, by opposite, it changes depending on the option you choose:
Option 1: Active Data Guard
If you have ADG, the ADG itself will take care of copying the datafile on the standby site, from the source standby pdb to the destination standby pdb. Once the copy is done, the MRP0 will continue the recovery. The modification of the header block of the destination PDB is done by the MRP0 immediately after the copy (at least this is what I understand).
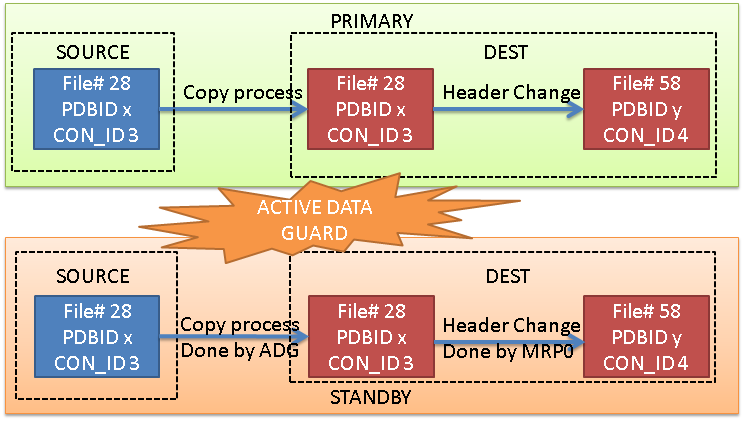
Option 2: No Active Data Guard, but STANDBYS=none
In this case, the copy on the standby site doesn’t happen, and the recovery process just add the entry of the new datafiles in the controlfile, with status OFFLINE and name UNKNOWNxxx. However, the source file cannot be copied anymore, because the MRP0 process will expect to have a copy of the destination datafile, not the source datafile. Also, any tentative of restore of the datafile 28 (in this example) will give an error because it does not belong to the destination PDB. So the only chance is to restore the destination PDB from the primary.
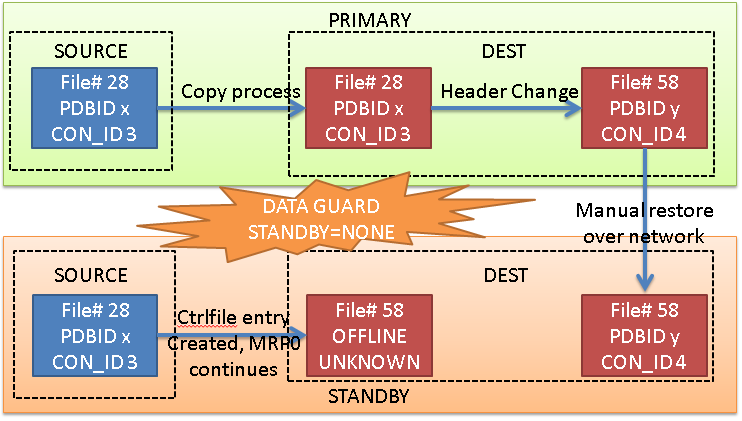
Option 3: No Active Data Guard, no STANDBYS=none
This is the case that I want to explain actually. Without the flag STANDBYS=none, the MRP0 process will expect to change the header of the new datafile, but because the file does not exist yet, the recovery process dies.
We can then copy it manually from the source standby pdb, and restart the recovery process, that will change the header. This process needs to be repeated for each datafile. (that’s why it’s not a viable solution, right now).
We need to fix the datafiles one by one, but most of the steps can be done once for all the datafiles.
Copy the source PDB from the standby
What do we need to do? Well, the recovery process is stopped, so we can safely copy the datafiles of the source PDB from the standby site because they have not moved yet. (meanwhile, we can put the primary source PDB back in read-write mode).
Now there’s the interesting part: we need to assign the datafile copies of the maaz PDB to LUDO.
Sadly, the OMF will create the copies on the bad location (it’s a copy, to they are created on the same location as the source PDB).
We cannot try to uncatalog and recatalog the copies, because they will ALWAYS be affected to the source PDB. Neither we can use RMAN because it will never associate the datafile copies to the new PDB. We need to rename the files manually.
The recovery process will:
– change the new datafile by modifying the header for the new PDB
– create the entry for the second datafile in the controlfile
– crash again because the datafile is missing
This time all the datafiles have been copied (no user datafile for this example) and the recovery process will continue!! 🙂 so we can hit ^C and start it in background.
I know there’s no practical use of this procedure, but it helps a lot in understanding how Multitenant has been implemented.
I expect some improvements in 12.2!!
Cheers
—
Ludo
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.Accept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.








![DSC_0363[1]](https://www.ludovicocaldara.net/dba/wp-content/uploads/2014/12/DSC_03631.jpg)