
Having the capability of managing multiple Oracle Homes is fundamental for the following reasons:
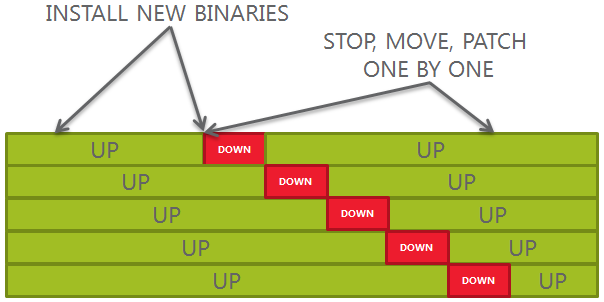
- Out-of-place patching: cloning and patching a new Oracle Home usually takes less downtime than stopping the DBs and patching in-place
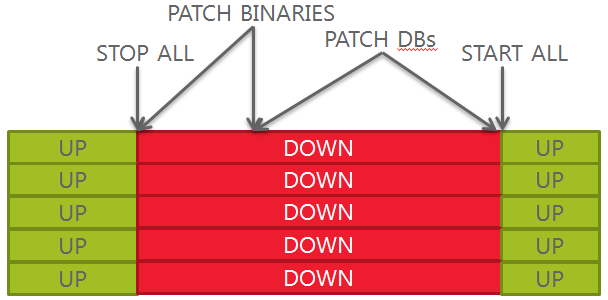
- Better control of downtime windows: if the databases are consolidated on a single server, having multiple Oracle Homes allows moving and patching one database at a time instead of stopping everything and doing a “big bang” patch.
Make sure that you have a good set of scripts that help you to switch correctly from one environment to the other one. Personally, I recommend TVD-BasEnv, as it is very powerful and supports OFA and non-OFA environments, but for this blog series I will show my personal approach.
Get your Home information from the Inventory!
I wrote a blog post sometimes ago that shows how to get the Oracle Homes from the Central Inventory (Using Bash, OK, not the right tool to query XML files, but you get the idea):
With the same approach, you can have a script to SET your environment:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
setoh () { SEARCH=${1:-"_foo_"}; if [ $SEARCH == "ic" ]; then # ic is a shortcut for the Instant Client... OH=/u01/app/oracle/sbin/instantclient_12_2 export VERSION=12.2.0.1 export ORACLE_HOME=$OH export LD_LIBRARY_PATH=$ORACLE_HOME export OH_NAME=instantclient_12_2 export ORACLE_VERSION=$VERSION export PATH=$ORACLE_HOME:$DEFAULT_PATH echo ORACLE_SID = $ORACLE_SID echo ORACLE_VERSION = $ORACLE_VERSION echo ORACLE_HOME = $ORACLE_HOME else CENTRAL_ORAINV=`grep ^inventory_loc /etc/oraInst.loc | awk -F= '{print $2}'`; IFS=' '; found=0; for line in `grep "<HOME NAME=" ${CENTRAL_ORAINV}/ContentsXML/inventory.xml 2>/dev/null`; do if [ $found -eq 1 ]; then continue; fi; unset ORACLE_VERSION; unset ORAEDITION; OH=`echo $line | tr ' ' '\n' | grep ^LOC= | awk -F\" '{print $2}'`; OH_NAME=`echo $line | tr ' ' '\n' | grep ^NAME= | awk -F\" '{print $2}'`; if [ "$SEARCH" == "$OH_NAME" ]; then found=1; comp_file=$OH/inventory/ContentsXML/comps.xml; comp_xml=`grep "COMP NAME" $comp_file | head -1`; comp_name=`echo $comp_xml | tr ' ' '\n' | grep ^NAME= | awk -F\" '{print $2}'`; comp_vers=`echo $comp_xml | tr ' ' '\n' | grep ^VER= | awk -F\" '{print $2}'`; case $comp_name in "oracle.crs") ORACLE_VERSION=$comp_vers; ORAEDITION=GRID ;; "oracle.sysman.top.agent") ORACLE_VERSION=$comp_vers; ORAEDITION=AGT ;; "oracle.server") ORACLE_VERSION=`grep "PATCH NAME=\"oracle.server\"" $comp_file 2>/dev/null | tr ' ' '\n' | grep ^VER= | awk -F\" '{print $2}'`; ORAEDITION="DBMS"; if [ -z "$ORACLE_VERSION" ]; then ORACLE_VERSION=$comp_vers; fi; ORAMAJOR=`echo $ORACLE_VERSION | cut -d . -f 1`; case $ORAMAJOR in 11 | 12) ORAEDITION="DBMS "`grep "oracle_install_db_InstallType" $OH/inventory/globalvariables/oracle.server/globalvariables.xml 2>/dev/null | tr ' ' '\n' | grep VALUE | awk -F\" '{print $2}'` ;; 10) ORAEDITION="DBMS "`grep "s_serverInstallType" $OH/inventory/Components21/oracle.server/*/context.xml 2>/dev/null | tr ' ' '\n' | grep VALUE | awk -F\" '{print $2}'` ;; esac ;; esac; export VERSION=$ORACLE_VERSION; export ORACLE_HOME=$OH; export LD_LIBRARY_PATH=$ORACLE_HOME/lib; export OH_NAME; export ORACLE_VERSION; export PATH=$ORACLE_HOME/bin:$ORACLE_HOME/OPatch:$DEFAULT_PATH; echo ORACLE_SID = $ORACLE_SID; echo ORACLE_VERSION = $ORACLE_VERSION; echo ORACLE_HOME = $ORACLE_HOME; continue; fi; done; if [ $found -eq 0 ]; then echo "cannot find Oracle Home $1"; false; else true; fi; fi } |
It uses a different approach from the oraenv script privided by Oracle, where you set the environment based on the ORACLE_SID variable and getting the information from the oratab. My setoh function gets the Oracle Home name as input. Although you can convert it easily to set the environment for a specific ORACLE_SID, there are some reason why I like it:
- You can set the environment for an Oracle Home that it is not associated to any database (yet)
- You can set the environment for an upgrade to a new release without changing (yet) the oratab
- It works for OMS, Grid and Agent homes as well…
- Most important, it will let you specify correctly the environment when you need to use a fresh install (for patching it as well)
So, this is how it works:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# [ oracle@myserver:/u01/app/oracle [11:23:18] [12.1.0.2.0 SID="not set"] 0 ] # # lsoh HOME LOCATION VERSION EDITION --------------------------- ------------------------------------------------------- ------------ --------- OraGI12Home1 /u01/app/grid/product/grid 12.1.0.2.0 GRID agent12c1 /u01/app/oracle/product/agent12c/core/12.1.0.5.0 12.1.0.5.0 AGT OraDb11g_home1 /u01/app/oracle/product/11.2.0.4 11.2.0.4.0 DBMS EE OraDB12Home1 /u01/app/oracle/product/12.1.0.2 12.1.0.2.0 DBMS EE 12_1_0_2_BP170718_RON /u01/app/oracle/product/12_1_0_2_BP170718_RON 12.1.0.2.0 DBMS EE 12_1_0_2_BP180116_OCW /u01/app/oracle/product/12_1_0_2_BP180116_OCW 12.1.0.2.0 DBMS EE # [ oracle@myserver:/u01/app/oracle [11:23:22] [12.1.0.2.0 SID="not set"] 0 ] # # setoh 12_1_0_2_BP180116_OCW ORACLE_SID = ORACLE_VERSION = 12.1.0.2.0 ORACLE_HOME = /u01/app/oracle/product/12_1_0_2_BP180116_OCW # [ oracle@myserver:/u01/app/oracle [11:23:25] [12.1.0.2.0 SID="not set"] 0 ] # # opatch lspatches 26925218;OCW Patch Set Update : 12.1.0.2.180116 (26925218) 26925263;Database Bundle Patch : 12.1.0.2.180116 (26925263) 22243983; OPatch succeeded. |
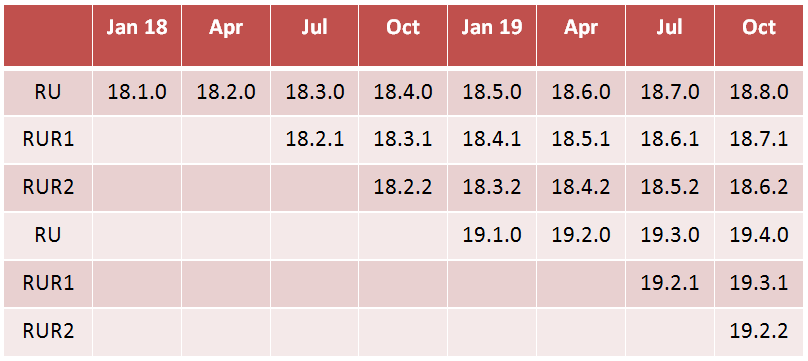
In the previous example, there are two Database homes that have been installed without a specific naming convention (OraDb11g_home1, OraDB12Home1) and two that follow a specific one (12_1_0_2_BP170718_RON, 12_1_0_2_BP180116_OCW).
Naming conventions play an important role
If you want to achieve an effective Oracle Home management, it is important that you have everywhere the same ORACLE_HOME paths, names and patch levels.
The Oracle Home path should not include only the release number:
|
1 |
/u01/app/oracle/product/12.1.0.2 |
If we have many Oracle Homes with the same release, how shall we call the other ones? There are several variables that might influence the naming convention:
Edition (EE, SE), RAC Option or other options, the patch type (formerly PSU, BP: now RU and RUR), eventual additional one-off patches.
Some ideas might be:
|
1 2 3 |
/u01/app/oracle/product/EE12.1.0.2 /u01/app/oracle/product/EE12.1.0.2_BP171019 /u01/app/oracle/product/EE12.1.0.2_BP171019_v2 |
The new release model will facilitate a lot the definition of a naming convention as we will have names like:
|
1 2 3 |
/u01/app/oracle/product/EE18.1.0 /u01/app/oracle/product/EE18.2.1 /u01/app/oracle/product/EE18.2.1_v2 |
Of course, the naming convention is not universal and can be adapted depending on the customer (e.g., if you have only Enterprise Editions you might omit this information).
Replacing dots with underscores?
You will see, at the end of the series, that I use Oracle Home paths with underscores instead of dots:
|
1 2 3 |
/u01/app/oracle/product/EE12_1_0_2 /u01/app/oracle/product/EE12_1_0_2_BP171019 /u01/app/oracle/product/EE12_1_0_2_BP171019_v2 |
Why?
From a naming perspective, there is no need to have the Home that corresponds to the release number. Release, version and product information can be collected through the inventory.
What is really important is to have good naming conventions and good manageability. In my ideal world, the Oracle Home name inside the central inventory and the basename of the Oracle Home path are the same: this facilitates tremendously the scripting of the Oracle Home provisioning.
Sadly, the Oracle Home name cannot contain dots, it is a limitation of the Oracle Inventory, here’s why I replaced them with underscores.
In the next blog post, I will show how to plan a framework for automated Oracle Home provisioning.

![2018-05-03 16_26_38-Diaporama PowerPoint - [Présentation1]](https://www.ludovicocaldara.net/dba/wp-content/uploads/2018/05/2018-05-03-16_26_38-Diaporama-PowerPoint-Présentation1.png)