SQL> connect / as sysdba
Connected.
SQL> DECLARE
2 v_dropped_plans number;
3 BEGIN
4 v_dropped_plans := DBMS_SPM.DROP_SQL_PLAN_BASELINE (
5 sql_handle => 'SQL_6c4c6680810dd01a'
6 );
7 DBMS_OUTPUT.PUT_LINE('dropped ' || v_dropped_plans || ' plans');
8 END;
9 /
PL/SQL procedure successfully completed.
SQL> select sql_handle, plan_name, sql_text, enabled, accepted, fixed from dba_sql_plan_baselines;
no rows selected
SQL> alter system flush shared_pool;
System altered.
SQL> select sql_id, plan_hash_value, child_number from v$sql where sql_id='1km5kczcgr0fr';
no rows selected
SQL> connect ludo/ludo
Connected.
SQL> ALTER SESSION SET OPTIMIZER_CAPTURE_SQL_PLAN_BASELINES = TRUE;
Session altered.
SELECT /*+ GATHER_PLAN_STATISTICS */
2 a.data AS tab1_data,
3 b.data AS tab2_data
4 FROM tab1 a
5 JOIN tab2 b ON b.tab1_id = a.id
6 WHERE a.code = 'ONE';
TAB1_DATA TAB2_DATA
---------- ----------
...
30 rows selected.
SQL> r
1 SELECT /*+ GATHER_PLAN_STATISTICS */
2 a.data AS tab1_data,
3 b.data AS tab2_data
4 FROM tab1 a
5 JOIN tab2 b ON b.tab1_id = a.id
6* WHERE a.code = 'ONE'
TAB1_DATA TAB2_DATA
---------- ----------
...
30 rows selected.
SQL> ALTER SESSION SET OPTIMIZER_CAPTURE_SQL_PLAN_BASELINES = FALSE;
Session altered.
SQL> select sql_id, plan_hash_value, child_number from v$sql where sql_id='1km5kczcgr0fr';
SQL_ID PLAN_HASH_VALUE CHILD_NUMBER
--------------------------------------- --------------- ------------
1km5kczcgr0fr 2672205743 1
SELECT /*+ GATHER_PLAN_STATISTICS */
a.data AS tab1_data,
2 3 b.data AS tab2_data
4 FROM tab1 a
5 JOIN tab2 b ON b.tab1_id = a.id
6 WHERE a.code = 'ONE';
TAB1_DATA TAB2_DATA
---------- ----------
...
30 rows selected.
SQL> select sql_id, plan_hash_value, child_number from v$sql where sql_id='1km5kczcgr0fr';
SQL_ID PLAN_HASH_VALUE CHILD_NUMBER
--------------------------------------- --------------- ------------
1km5kczcgr0fr 2672205743 1
1km5kczcgr0fr 2672205743 2
SQL> ALTER SESSION SET OPTIMIZER_USE_SQL_PLAN_BASELINES = FALSE;
Session altered.
SELECT /*+ GATHER_PLAN_STATISTICS */
2 a.data AS tab1_data,
3 b.data AS tab2_data
4 FROM tab1 a
5 JOIN tab2 b ON b.tab1_id = a.id
6 WHERE a.code = 'ONE';
TAB1_DATA TAB2_DATA
---------- ----------
...
30 rows selected.
SQL> select sql_id, plan_hash_value, child_number from v$sql where sql_id='1km5kczcgr0fr';
SQL_ID PLAN_HASH_VALUE CHILD_NUMBER
--------------------------------------- --------------- ------------
1km5kczcgr0fr 1599395313 0
1km5kczcgr0fr 2672205743 1
1km5kczcgr0fr 2672205743 2
SQL> connect / as sysdba
Connected.
SQL> VARIABLE cnt NUMBER
SQL> EXECUTE :cnt := DBMS_SPM.LOAD_PLANS_FROM_CURSOR_CACHE( sql_id => '1km5kczcgr0fr',plan_hash_value => '1599395313');
PL/SQL procedure successfully completed.
SQL> select sql_handle, plan_name, sql_text, enabled, accepted, fixed from dba_sql_plan_baselines;
SQL_HANDLE PLAN_NAME SQL_TEXT ENABLED ACCEPTED FIXED
------------------------- ----------------------------------- -------------------------------------- --------- --------- ---------
SQL_6c4c6680810dd01a SQL_PLAN_6sm36h20hvn0u55a25f73 SELECT /*+ GATHER_PLAN_STATISTICS */ YES YES NO
a.data AS tab1_data,
b.data A
SQL_6c4c6680810dd01a SQL_PLAN_6sm36h20hvn0ud64ac9be SELECT /*+ GATHER_PLAN_STATISTICS */ YES YES NO
a.data AS tab1_data,
b.data A
SQL> select * from table (DBMS_XPLAN.DISPLAY_SQL_PLAN_BASELINE('SQL_6c4c6680810dd01a', format=>'+adaptive'));
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------
--------------------------------------------------------------------------------
SQL handle: SQL_6c4c6680810dd01a
SQL text: SELECT /*+ GATHER_PLAN_STATISTICS */ a.data AS tab1_data,
b.data AS tab2_data FROM tab1 a JOIN tab2 b ON b.tab1_id =
a.id WHERE a.code = 'ONE'
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Plan name: SQL_PLAN_6sm36h20hvn0u55a25f73 Plan id: 1436704627
Enabled: YES Fixed: NO Accepted: YES Origin: AUTO-CAPTURE
Plan rows: From dictionary
--------------------------------------------------------------------------------
Plan hash value: 2672205743
---------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 25 | 425 | 3 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 25 | 425 | 3 (0)| 00:00:01 |
| 2 | NESTED LOOPS | | 25 | 425 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID BATCHED| TAB1 | 1 | 11 | 2 (0)| 00:00:01 |
| * 4 | INDEX RANGE SCAN | TAB1_CODE | 1 | | 1 (0)| 00:00:01 |
| * 5 | INDEX RANGE SCAN | TAB2_TAB1_FKI | 25 | | 0 (0)| 00:00:01 |
| 6 | TABLE ACCESS BY INDEX ROWID | TAB2 | 25 | 150 | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("A"."CODE"='ONE')
5 - access("B"."TAB1_ID"="A"."ID")
Note
-----
- this is an adaptive plan (rows marked '-' are inactive)
--------------------------------------------------------------------------------
Plan name: SQL_PLAN_6sm36h20hvn0ud64ac9be Plan id: 3595225534
Enabled: YES Fixed: NO Accepted: YES Origin: MANUAL-LOAD
Plan rows: From dictionary
--------------------------------------------------------------------------------
Plan hash value: 1599395313
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 3 (100)| |
| * 1 | HASH JOIN | | 25 | 425 | 3 (0)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID BATCHED| TAB1 | 1 | 11 | 2 (0)| 00:00:01 |
| * 3 | INDEX RANGE SCAN | TAB1_CODE | 1 | | 1 (0)| 00:00:01 |
| 4 | TABLE ACCESS FULL | TAB2 | 25 | 150 | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("B"."TAB1_ID"="A"."ID")
3 - access("A"."CODE"='ONE')
Note
-----
- this is an adaptive plan (rows marked '-' are inactive)
65 rows selected.
SQL> VARIABLE cnt NUMBER
SQL> EXECUTE :cnt := DBMS_SPM.DROP_SQL_PLAN_BASELINE( SQL_HANDLE => 'SQL_6c4c6680810dd01a',plan_name => 'SQL_PLAN_6sm36h20hvn0u55a25f73');
PL/SQL procedure successfully completed.
SQL> select sql_handle, plan_name, sql_text, enabled, accepted, fixed from dba_sql_plan_baselines;
SQL_HANDLE PLAN_NAME SQL_TEXT ENABLED ACCEPTED FIXED
------------------------- ----------------------------------- -------------------------------------- --------- --------- ---------
SQL_6c4c6680810dd01a SQL_PLAN_6sm36h20hvn0ud64ac9be SELECT /*+ GATHER_PLAN_STATISTICS */ YES YES NO
a.data AS tab1_data,
b.data A
SQL> conn ludo/ludo
Connected.
SELECT /*+ GATHER_PLAN_STATISTICS */
2 a.data AS tab1_data,
3 b.data AS tab2_data
4 FROM tab1 a
5 JOIN tab2 b ON b.tab1_id = a.id
6 WHERE a.code = 'ONE';
TAB1_DATA TAB2_DATA
---------- ----------
...
30 rows selected.
SQL> SELECT * FROM TABLE(DBMS_XPLAN.display_cursor(format => 'allstats last adaptive'));
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID 1km5kczcgr0fr, child number 2
-------------------------------------
SELECT /*+ GATHER_PLAN_STATISTICS */ a.data AS tab1_data,
b.data AS tab2_data FROM tab1 a JOIN tab2 b ON b.tab1_id =
a.id WHERE a.code = 'ONE'
Plan hash value: 1599395313
---------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
---------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 24 |00:00:00.01 | 71 | | | |
|* 1 | HASH JOIN | | 1 | 25 | 24 |00:00:00.01 | 71 | 1888K| 1888K| 1921K (0)|
| 2 | TABLE ACCESS BY INDEX ROWID BATCHED| TAB1 | 1 | 1 | 10001 |00:00:00.01 | 62 | | | |
|* 3 | INDEX RANGE SCAN | TAB1_CODE | 1 | 1 | 10001 |00:00:00.01 | 37 | | | |
| 4 | TABLE ACCESS FULL | TAB2 | 1 | 100 | 100 |00:00:00.01 | 9 | | | |
---------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("B"."TAB1_ID"="A"."ID")
3 - access("A"."CODE"='ONE')
Note
-----
- SQL plan baseline SQL_PLAN_6sm36h20hvn0ud64ac9be used for this statement
28 rows selected.

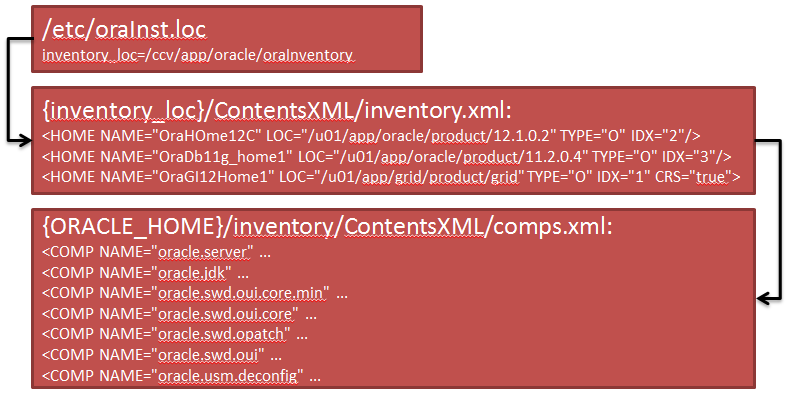 You can use this simple function to get some content out of it, including the edition (that information is a step deeper in the local inventory).
You can use this simple function to get some content out of it, including the edition (that information is a step deeper in the local inventory).