First, let me apologize because every post in my blog starts with a disclaimer… but sometimes it is really necessary. 😉
Disclaimer: this blog post contains PL/SQL code that deletes incarnations from your RMAN recovery catalog. Please DON’T use it unless you deeply understand what you are doing, as it can compromise your backup and recovery strategy.
Small introduction
You may have a central RMAN catalog that stores all the backup metadata for your databases. If it is the case, you will have a database entry for each of your databases and a new incarnation entry for each duplicate, incomplete recovery or flashback (or whatever).
You should also have a delete strategy that deletes the obsolete backups from either your DISK or SBT_TAPE media. If you have old incarnations, however, after some time you will notice that their information never goes away from your catalog, and you may end up soon or later to do some housekeeping. But there is nothing more tedious than checking and deleting the incarnations one by one, especially if you have average big numbers like this catalog:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
SQL> SELECT count(*) FROM db; COUNT(*) ---------- 1843 SQL> SELECT count(*) FROM dbinc; COUNT(*) ---------- 3870 SQL> SELECT count(*) FROM bdf; COUNT(*) ---------- 4130959 SQL> SELECT count(*) FROM brl; COUNT(*) ---------- 14876291 |
Where db, dbinc, bdf and brl contain reslectively the registered databases, incarnations, datafile backups and archivelog backups.
Different incarnations?
Consider the following query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
col dbinc_key_ for a60 set pages 100 lines 200 SELECT lpad(' ',2*(level-1)) || TO_CHAR(DBINC_KEY) AS DBINC_KEY_, db_key, db_name, TO_CHAR(reset_time,'YYYY-MM-DD HH24:MI:SS'), dbinc_status FROM rman.dbinc START WITH PARENT_DBINC_KEY IS NULL CONNECT BY prior DBINC_KEY = PARENT_DBINC_KEY ORDER BY db_name , db_key, level ; |
You can run it safely: it returns the list of incarnations hierarchically connected to their parent, by database name, key and level.
Then you have several types of behaviors:
- Normal databases (created once, never restored or flashed back) will have just one or two incarnations (it depends on how they are created):
|
1 2 3 4 |
DBINC_KEY DB_KEY DB_NAME TO_CHAR(RESET_TIME, DBINC_ST -------------------------- ---------- -------- ------------------- -------- 104547357 104546534 VxxxxxxP 2010-09-05 05:49:10 PARENT 104546535 104546534 VxxxxxxP 2012-01-18 09:31:01 CURRENT |
They are usually the ones that you may want to keep in your catalog, unless the database no longer exist: in this case perhaps you omitted the deletion from the catalog when you have dropped your database?
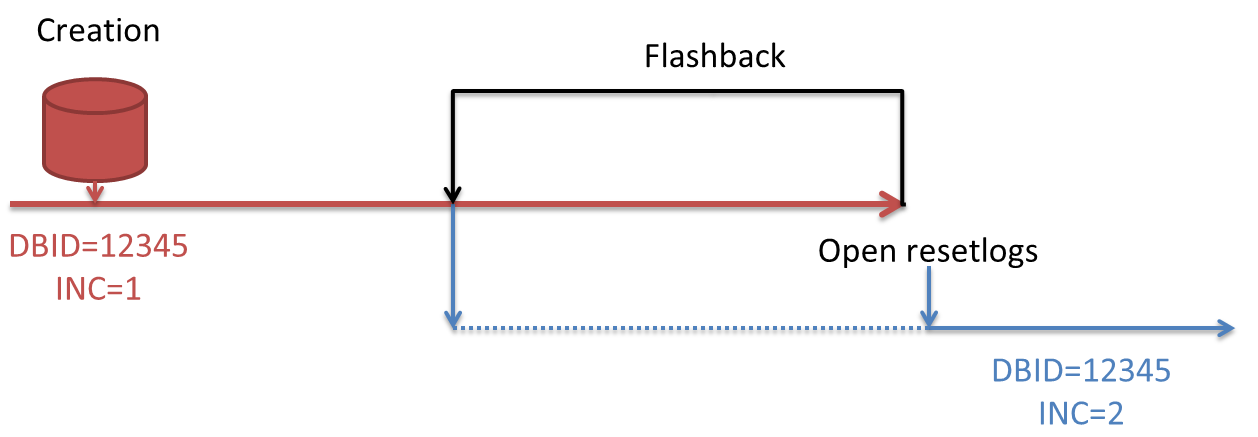
- Flashed back databases (flashed back multiple times) will have as many incarnations as the number of flashbacks, but all connected with the incarnation prior to the flashback:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
DBINC_KEY DB_KEY DB_NAME TO_CHAR(RESET_TIME, DBINC_ST ------------------------------------------------------------ ---------- -------- ------------------- -------- 1164696351 1164696336 VxxxxxxD 2014-07-07 05:38:47 PARENT 1164696337 1164696336 VxxxxxxD 2014-12-10 07:39:14 PARENT 1328815631 1164696336 VxxxxxxD 2016-05-12 08:22:23 PARENT 1329299866 1164696336 VxxxxxxD 2016-05-13 13:02:35 PARENT 1329299867 1164696336 VxxxxxxD 2016-05-13 14:05:53 PARENT 1329299833 1164696336 VxxxxxxD 2016-05-13 18:26:59 PARENT 1331239226 1164696336 VxxxxxxD 2016-05-17 08:09:04 PARENT 1331395102 1164696336 VxxxxxxD 2016-05-17 13:20:17 PARENT 1331815030 1164696336 VxxxxxxD 2016-05-18 07:32:13 PARENT 1331814966 1164696336 VxxxxxxD 2016-05-18 10:57:45 PARENT 1387023006 1164696336 VxxxxxxD 2016-07-13 09:33:05 PARENT 1407484366 1164696336 VxxxxxxD 2016-09-09 13:25:31 PARENT 1419007163 1164696336 VxxxxxxD 2016-10-17 14:32:59 PARENT 1436430179 1164696336 VxxxxxxD 2016-12-12 15:13:55 PARENT 1436430034 1164696336 VxxxxxxD 2016-12-12 16:28:57 PARENT 1437118959 1164696336 VxxxxxxD 2016-12-14 14:48:53 PARENT 1437365509 1164696336 VxxxxxxD 2016-12-15 09:45:00 PARENT 1437365456 1164696336 VxxxxxxD 2016-12-15 11:11:06 PARENT 1437484026 1164696336 VxxxxxxD 2016-12-15 13:26:37 PARENT 1437483983 1164696336 VxxxxxxD 2016-12-15 17:21:11 PARENT 1437822754 1164696336 VxxxxxxD 2016-12-16 12:07:46 CURRENT |
Here, despite you have several incarnations, they all belong to the same database (same DB_KEY and DBID), then you must also keep it inside the recovery catalog.
- Non-production databases that are frequently refreshed from the production database (via duplicate) will have several incarnations with different DBIDs and DB_KEY:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
DBINC_KEY DB_KEY DB_NAME TO_CHAR(RESET_TIME, DBINC_ST ----------------------- ---------- -------- ------------------- -------- 1173852671 1173852633 VxxxxxxV 2014-07-07 05:38:47 PARENT 1173852635 1173852633 VxxxxxxV 2015-01-16 07:29:01 PARENT 1188550385 1173852633 VxxxxxxV 2015-03-16 16:06:00 CURRENT 1220896058 1220896027 VxxxxxxV 2015-02-27 16:25:13 PARENT 1220896028 1220896027 VxxxxxxV 2015-07-17 08:06:00 CURRENT 1233975755 1233975724 VxxxxxxV 2015-02-27 16:25:13 PARENT 1233975725 1233975724 VxxxxxxV 2015-09-10 11:23:53 CURRENT 1244346785 1244346754 VxxxxxxV 2015-02-27 16:25:13 PARENT 1244346755 1244346754 VxxxxxxV 2015-10-23 07:46:34 CURRENT 1281775847 1281775816 VxxxxxxV 2015-02-27 16:25:13 PARENT 1281775817 1281775816 VxxxxxxV 2016-02-08 09:44:03 CURRENT 1317447322 1317447257 VxxxxxxV 2015-02-27 16:25:13 PARENT 1317447258 1317447257 VxxxxxxV 2016-04-07 12:20:56 CURRENT 1323527351 1323527316 VxxxxxxV 2015-02-27 16:25:13 PARENT 1323527317 1323527316 VxxxxxxV 2016-04-29 10:09:12 CURRENT 1437346753 1437346718 VxxxxxxV 2015-02-27 16:25:13 PARENT 1437346719 1437346718 VxxxxxxV 2016-12-12 13:33:31 CURRENT |
This is usually the most frequent case: here you want to delete the old incarnations, but only as far as there are no backups attached to them that are still in the recovery window.
- You may also have orphaned incarnations:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DBINC_KEY DB_KEY DB_NAME TO_CHAR(RESET_TIME, DBINC_ST ------------------------------------------------------------ ---------- -------- ------------------- -------- 1262827482 1262827435 TxxxxxxT 2014-07-07 05:38:47 PARENT 1262827436 1262827435 TxxxxxxT 2016-01-05 12:15:22 PARENT 1267262014 1262827435 TxxxxxxT 2016-01-19 09:15:47 PARENT 1267290962 1262827435 TxxxxxxT 2016-01-19 11:09:05 PARENT 1284933855 1262827435 TxxxxxxT 2016-02-11 11:18:52 PARENT 1299685647 1262827435 TxxxxxxT 2016-02-23 13:40:18 ORPHAN 1299837528 1262827435 TxxxxxxT 2016-02-23 17:08:36 CURRENT 1299767977 1262827435 TxxxxxxT 2016-02-23 15:34:13 ORPHAN 1298269640 1262827435 TxxxxxxT 2016-02-22 13:16:46 ORPHAN 1299517249 1262827435 TxxxxxxT 2016-02-23 10:37:29 ORPHAN |
In this case, again, it depends whether the DBID and DB_KEY are the same as the current incarnation or not.
What do you need to delete?
Basically:
- Incarnations of databases that no longer exist
- Incarnations of existing databases where the database has a more recent current incarnation, only if there are no backups still in the retention window
How to do it?
In order to be sure 100% that you can delete an incarnation, you have to verify that there are no recent backups (for instance, no backups more rercent than the current recovery window for that database). If the database does not have a specified recovery window but rather a default “CONFIGURE RETENTION POLICY TO REDUNDANCY 1; # default”, it is a bit more problematic… in this case let’s assume that we consider “old” an incarnation that does not backup since 1 year (365 days), ok?
Getting the last backup of each database
Sadly, there is not a single table where you can verify that. You have to collect the information from several tables. I think bdf, al, cdf, bs would suffice in most cases.
When you delete an incarnation you specify a db_key: you have to get the last backup for each db_key, with queries like this:
|
1 2 3 4 |
SELECT dbinc_key ,max(completion_time) max_al_time FROM al GROUP by dbinc_key; |
Putting together all the tables:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
WITH incs AS ( SELECT lpad(' ',2*(level-1))|| to_char(dbinc_key) AS dbinc_key_ ,dbinc_key ,db_key ,db_name ,reset_time ,dbinc_status FROM rman.dbinc START WITH parent_dbinc_key IS NULL CONNECT BY PRIOR dbinc_key = parent_dbinc_key ORDER BY db_name, db_key, level ), mbdf AS ( SELECT dbinc_key ,max(completion_time) max_bdf_time FROM bdf GROUP by dbinc_key ), mbrl AS ( SELECT dbinc_key ,max(next_time) max_brl_time FROM brl GROUP by dbinc_key ), mal AS ( SELECT dbinc_key ,max(completion_time) max_al_time FROM al GROUP by dbinc_key ), mcdf AS ( SELECT dbinc_key ,max(completion_time) max_cdf_time FROM cdf GROUP by dbinc_key ), mbs AS ( SELECT db_key ,max(completion_time) max_bs_time FROM bs GROUP by db_key ) SELECT incs.db_key, db.db_id, db.REG_DB_UNIQUE_NAME AS db_uq_name , incs.db_name, dbinc_status ,greatest( nvl(max_bdf_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_brl_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_al_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_cdf_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_bs_time,to_date('1970-01-01','YYYY-MM-DD')) ) AS last_bck FROM incs JOIN db ON (db.db_key=incs.db_key) LEFT OUTER JOIN mbdf ON (incs.dbinc_key=mbdf.dbinc_key) LEFT OUTER JOIN mcdf ON (incs.dbinc_key=mcdf.dbinc_key) LEFT OUTER JOIN mbrl ON (incs.dbinc_key=mbrl.dbinc_key) LEFT OUTER JOIN mal ON (incs.dbinc_key=mal.dbinc_key) LEFT OUTER JOIN mbs ON (incs.db_key=mbs.db_key) ; |
Getting the recovery window
The configuration information for each database is stored inside the conf table, but the retention information is stored in a VARCHAR2, either ‘TO RECOVERY WINDOW OF % DAYS’ or ‘TO REDUNDANCY %’
You need to convert it to a number when the retention policy is recovery windows, otherwise you default it to 365 days wher the redundancy is used. You can add a column and a join to the query:
|
1 2 3 4 5 |
-- new column in the projection ,nvl(to_number(substr(c.value,23,length(c.value)-27)),365) as days -- new join in the "from" LEFT OUTER JOIN conf c ON (c.db_key=incs.db_key AND c.NAME = 'RETENTION POLICY' AND value LIKE 'TO RECOVERY WINDOW OF %') |
and eventually, either display if it the incarnation is no more used or filter by usage:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
-- display if the incarnation is still used ,CASE WHEN greatest( nvl(max_bdf_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_brl_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_al_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_cdf_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_bs_time,to_date('1970-01-01','YYYY-MM-DD')) ) < (sysdate - nvl(to_number(substr(c.value,23,length(c.value)-27)),365)) THEN 'OLD ONE!' ELSE 'USED' END AS USED -- or filter it WHERE greatest( nvl(max_bdf_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_brl_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_al_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_cdf_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_bs_time,to_date('1970-01-01','YYYY-MM-DD')) ) < (sysdate - nvl(to_number(substr(c.value,23,length(c.value)-27)),365)) |
Delete the incarnations!
You can delete the incarnations with this procedure:
|
1 2 3 |
BEGIN dbms_rcvcat.unregisterdatabase(DB_KEY=>:db_key, DB_ID=>:db_id); END; |
This procedure will raise an exception (-20001, ‘Database not found’) when a database does not exist anymore (either already deleted by this procedure or by another session), so you need to handle it.
Putting all together:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 |
col db_uq_name for a12 col dbinc_key_ for a30 set pages 100 lines 200 set serveroutput on DECLARE e_dbatabase_not_found EXCEPTION; PRAGMA EXCEPTION_INIT (e_dbatabase_not_found, -20001); CURSOR c_old_incarnations IS WITH incs AS ( SELECT lpad(' ',2*(level-1))|| to_char(dbinc_key) AS dbinc_key_ ,dbinc_key ,db_key ,db_name ,reset_time ,dbinc_status FROM rman.dbinc START WITH parent_dbinc_key IS NULL CONNECT BY PRIOR dbinc_key = parent_dbinc_key ORDER BY db_name, db_key, level ), mbdf AS ( SELECT dbinc_key ,max(completion_time) max_bdf_time FROM bdf GROUP by dbinc_key ), mbrl AS ( SELECT dbinc_key ,max(next_time) max_brl_time FROM brl GROUP by dbinc_key ), mal AS ( SELECT dbinc_key ,max(completion_time) max_al_time FROM al GROUP by dbinc_key ), mcdf AS ( SELECT dbinc_key ,max(completion_time) max_cdf_time FROM cdf GROUP by dbinc_key ), mbs AS ( SELECT db_key ,max(completion_time) max_bs_time FROM bs GROUP by db_key ) SELECT distinct incs.db_key, db.db_id, db.REG_DB_UNIQUE_NAME AS db_uq_name , incs.db_name ,greatest( nvl(max_bdf_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_brl_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_al_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_cdf_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_bs_time,to_date('1970-01-01','YYYY-MM-DD')) ) AS last_bck ,CASE WHEN greatest( nvl(max_bdf_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_brl_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_al_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_cdf_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_bs_time,to_date('1970-01-01','YYYY-MM-DD')) ) < (sysdate - nvl(to_number(substr(c.value,23,length(c.value)-27)),365)) THEN 'OLD ONE!' ELSE 'USED' END AS USED FROM incs JOIN db ON (db.db_key=incs.db_key) LEFT OUTER JOIN mbdf ON (incs.dbinc_key=mbdf.dbinc_key) LEFT OUTER JOIN mcdf ON (incs.dbinc_key=mcdf.dbinc_key) LEFT OUTER JOIN mbrl ON (incs.dbinc_key=mbrl.dbinc_key) LEFT OUTER JOIN mal ON (incs.dbinc_key=mal.dbinc_key) LEFT OUTER JOIN mbs ON (incs.db_key=mbs.db_key) LEFT OUTER JOIN conf c ON (c.db_key=incs.db_key AND c.NAME = 'RETENTION POLICY' AND value LIKE 'TO RECOVERY WINDOW OF %') WHERE 1=1 AND greatest( nvl(max_bdf_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_brl_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_al_time ,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_cdf_time,to_date('1970-01-01','YYYY-MM-DD')), nvl(max_bs_time,to_date('1970-01-01','YYYY-MM-DD')) ) < (sysdate - nvl(to_number(substr(c.value,23,length(c.value)-27)),365)) order by 4,3, 5 ; r_old_incarnation c_old_incarnations%ROWTYPE; BEGIN OPEN c_old_incarnations; LOOP FETCH c_old_incarnations INTO r_old_incarnation; EXIT WHEN c_old_incarnations%NOTFOUND; dbms_output.put('Purging db: ' || r_old_incarnation.db_name); dbms_output.put(' IncKey: ' || r_old_incarnation.db_key); dbms_output.put(' DBID: ' || r_old_incarnation.db_id); dbms_output.put_line(' Last BCK: ' || to_char(r_old_incarnation.last_bck,'YYYY-MM-DD')); BEGIN dbms_rcvcat.unregisterdatabase(DB_KEY => r_old_incarnation.db_key, DB_ID => r_old_incarnation.db_id); EXCEPTION WHEN e_dbatabase_not_found THEN dbms_output.put_line('Database already unregistered'); END; END LOOP; CLOSE c_old_incarnations; END; / |
I have used this procedure today for the first time and it worked like a charm.
However, if you have any adjustment or suggestion, don’t hesitate to comment it 🙂
HTH