
PostgreSQL uses a nice, non standard mechanism for big columns called TOAST (hopefully will blog about it in the future) that can be compared to extended data types in Oracle (TOAST rows by the way can be much bigger). But traditional large objects exist and are still used by many customers.
If you are new to large objects in PostgreSQL, read here. For TOAST, read here.
Inside the application tables, the columns for large objects are defined as OIDs that point to data chunks inside the pg_largeobject table.
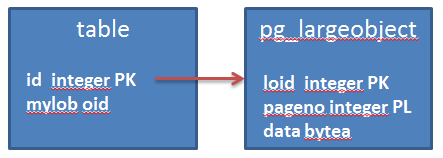
Because the large objects are created independently from the table columns that reference to it, when you delete a row from the table that points to the large object, the large object itself is not deleted.
Moreover, pg_largeobject stores by design all the large objects that exist in the database.
This makes housekeeping and maintenance of this table crucial for the database administration. (we will see it in a next post)
How is space organized for large objects?
We will see it by examples. Let’s start with an empty database with empty pg_largeobject:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
lob_test=# select count(*) from pg_largeobject; count ------- 0 (1 row) lob_test=# vacuum full pg_largeobject; VACUUM lob_test=# select pg_total_relation_size('pg_largeobject'); pg_total_relation_size ------------------------ 8192 (1 row) |
Just one block. Let’s see its file on disk:
|
1 2 3 4 5 6 7 8 |
lob_test=# SELECT pg_relation_filepath('pg_largeobject'); pg_relation_filepath ---------------------- base/16471/16487 (1 row) # ls -l base/16471/16487 -rw------- 1 postgres postgres 0 Jul 26 16:58 base/16471/16487 |
First evidence: the file is empty, meaning that the first block is not created physically until there’s some data in the table (like deferred segment creation in Oracle, except that the file exists).
Now, let’s create two files big 1MB for our tests, one zero-padded and another random-padded:
|
1 2 3 4 5 |
$ dd if=/dev/zero of=/tmp/zeroes bs=1024 count=1024 $ dd if=/dev/urandom of=/tmp/randoms bs=1024 count=1024 $ ls -l /tmp/zeroes /tmp/randoms -rw-r--r-- 1 postgres postgres 1048576 Jul 26 16:56 /tmp/randoms -rw-r--r-- 1 postgres postgres 1048576 Jul 26 16:23 /tmp/zeroes |
Let’s import the zero-padded one:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
lob_test=# \lo_import '/tmp/zeroes'; lo_import 16491 lob_test=# select count(*) from pg_largeobject_metadata; count ------- 1 (1 row) lob_test=# select count(*) from pg_largeobject; count ------- 512 (1 row) |
The large objects are split in chunks big 2048 bytes each one, hence we have 512 pieces. What about the physical size?
|
1 2 3 4 5 6 7 8 9 |
lob_test=# select pg_relation_size('pg_largeobject'); pg_total_relation_size ------------------------ 40960 (1 row) bash-4.1$ ls -l 16487* -rw------- 1 postgres postgres 40960 Jul 26 17:18 16487 |
Just 40k! This means that the chunks are compressed (like the TOAST pages). PostgreSQL uses the pglz_compress function, its algorithm is well explained in the source code src/common/pg_lzcompress.c.
What happens when we insert the random-padded file?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
lob_test=# \lo_import '/tmp/randoms'; lo_import 16492 lob_test=# select count(*) from pg_largeobject where loid=16492; count ------- 512 (1 row) lob_test=# select pg_relation_size('pg_largeobject'); pg_relation_size ------------------ 1441792 (1 row) $ ls -l 16487 -rw------- 1 postgres postgres 1441792 Jul 26 17:24 16487 |
The segment increased of much more than 1Mb! precisely, 1441792-40960 = 1400832 bytes. Why?
The large object is splitted again in 512 data chinks big 2048 bytes each, and again, PostgreSQL tries to compress them. But because a random string cannot be compressed, the pieces are still (average) 2048 bytes big.
Now, a database block size is 8192 bytes. If we subtract the size of the bloch header, there is not enough space for 4 chunks of 2048 bytes. Every block will contain just 3 non-compressed chunks.
So, 512 chunks will be distributed over 171 blocks (CEIL(512/3.0)), that gives:
|
1 2 3 4 5 |
lob_test=# select ceil(1024*1024/2048/3.0)*8192; ?column? ---------- 1400832 (1 row) |
1400832 bytes!
Depending on the compression rate that we can apply to our large objects, we might expect much more or much less space used inside the pg_largeobject table.
Latest posts by Ludovico (see all)
- Data Guard 26ai – #28: Fast-Start Failover Validation - April 17, 2026
- Data Guard 26ai – #27: Enhanced Observer Diagnostics - April 16, 2026
- Data Guard 26ai – #26: Fast-Start Failover Lag Histogram - April 7, 2026
Hello,
Thanks for this detailed explanation, is there a query to find where the pg_largeobject are used (which schema is using pg_largeobject) ?
Pingback: PostgreSQL Large Objects and space usage (part 1) - Ludovico Caldara - Blogs - triBLOG