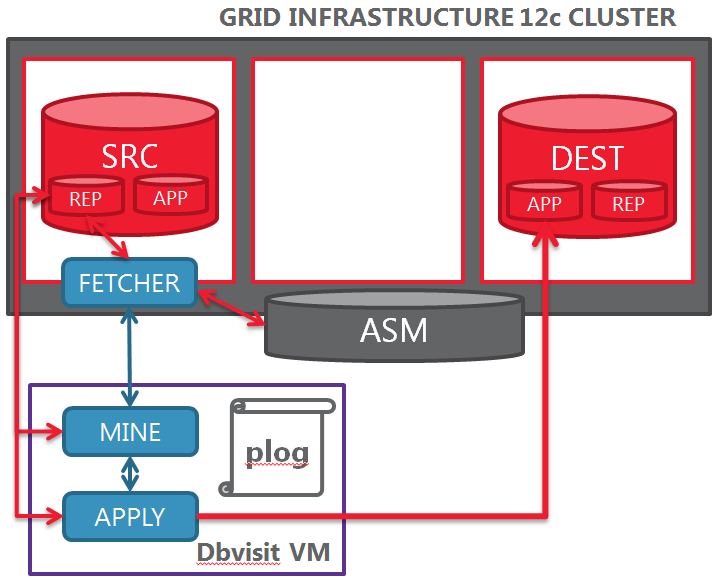
#!/u01/app/oracle/tvdtoolbox/tvdperl-Linux-x86-64-02.04.00-05.08.04/bin/tvd_perl
use File::Copy;
use File::Path qw(mkpath rmtree);
use Net::SMTP;
use Sys::Hostname;
use Getopt::Std 'getopts';
use File::Basename;
use DBI;
use DBD::Oracle qw(:ora_session_modes);
my $CloneDIR; # predefine rootDir variable
BEGIN {
use FindBin qw($Bin); # get the current path of script
use Cwd 'abs_path';
$CloneDIR = abs_path("$Bin/.."); # get the absolut rood path to clone directory
}
my $CloneLOGDir = $CloneDIR."/log"; # LOG Directory
my $baseACFS = "/u02/acfs";
my $basename = basename($0, ".pl");
my $BaseDB;
my $SnapshotName;
my $DestDB;
my $DestPath; # contains the final snapshot destination
my $oraenv = '/usr/local/bin/oraenv';
my $crsctl = '/u01/app/grid/12.2.0.1/bin/crsctl';
my $ORACLE_HOME = '/u01/app/oracle/product/12.2.0.1/dbhome_1';
my %opts;
my $dbh;
my $db_create_file_dest;
my $db_unique_name;
my $cmd;
my $SnapError=0;
my $SnapDir;
my $ControlfileTrace = "control.trc";
my $InitName = "init.ora";
my $warnings = 0;
my $foo;
my $dbUniqueName;
################################################################################
# Main
################################################################################
my $StartDate = localtime;
&DoMsg ("Start of $basename.pl");
unless ( open (MAINLOG, ">>$CloneLOGDir/$basename.log") ) {
&DoMsg ("Can't open Main Logfile $CloneLOGDir/$basename.log");
exit 1;
}
# b: base db
# u: source database db_unique_name. if empty, will try to get it dynamically
# s: snapshot name
# d: destination name
# Process command line arguments
if ( ! defined @ARGV ) { &Usage; exit 1; }
getopts('b:s:d:u:', \%opts);
if ($opts{"b"}) {
$BaseDB = $opts{"b"};
} else {
&DoMsg ("Base DB not given!");
&Usage;
exit 1;
}
if ($opts{"s"}) {
$SnapshotName = $opts{"s"};
} else {
&DoMsg ("Snapshot Name not given!");
&ListSnapshots;
exit 1;
}
if ($opts{"d"}) {
$DestDB = $opts{"d"};
} else {
&DoMsg ("Dest DB not given!");
&Usage;
exit 1;
}
if ($opts{"u"}) {
$dbUniqueName = $opts{"u"};
} else {
&DoMsg ("db_unique_name not given, try to get it dynamically");
&ConnectDB ;
$dbUniqueName= &QueryOneValue(qq{SELECT value FROM v\$parameter2 WHERE name='db_unique_name'});
&DisconnectDB ;
}
# show the parameters
&DoMsg ("Base: $BaseDB");
&DoMsg ("SnapshotName: $SnapshotName");
&DoMsg ("Dest: $DestDB");
&DoMsg ("db_unique_name: $dbUniqueName");
# try to get the ORACLE_HOME of the resource
my $cmd = "$crsctl status resource ora.".$DestDB.".db -f";
&DoMsg ($cmd);
open( CMD, $cmd . " |");
my @output = <CMD>;
close CMD;
#if ( $? != 0 ) {
# &DoMsg ("Destination database does not exist, please configure it with srvctl");
# exit 1;
#}
foreach (@output) {
chomp($_);
if ($_ =~ /^ORACLE_HOME=/) {
($foo, $ORACLE_HOME) = split (/=/);
$ENV{ORACLE_HOME}=$ORACLE_HOME;
&DoMsg ("OH = $ORACLE_HOME");
}
}
# try to get the status of the resource using srvctl
my $cmd = "$ORACLE_HOME/bin/srvctl status database -d $DestDB";
&DoMsg ($cmd);
open( CMD, $cmd . " |");
&DoMsg (join("", <CMD>));
close CMD;
#if ( $? != 0 ) {
# &DoMsg ("Destination database does not exist, please configure it");
# exit 1;
#}
# try to stop the dest db (will ignore errors)
my $cmd = "$ORACLE_HOME/bin/srvctl stop database -d $DestDB -o abort -f";
&DoMsg ($cmd);
open( CMD, $cmd . " |");
&DoMsg (join("", <CMD>));
close CMD;
# drop/recreate the snapshot using snap_acfs.pl
$cmd = "tvd_perl ".$CloneDIR."/bin/snap_acfs.pl -p $SnapshotName -n $DestDB";
&DoMsg($cmd);
open( CMD, $cmd . " |");
print (join("", <CMD>)); ## only print here as it logs and echoes its time as well
close CMD;
#if ( $? != 0 ) {
# &DoMsg("Error creating the new snapshot for $DestDB. Exiting.");
# exit(1);
#}
$DestPath = $baseACFS . '/.ACFS/snaps/' . $DestDB;
$ControlfileTrace = $DestPath.'/'.$ControlfileTrace;
$InitName = $DestPath.'/'.$InitName;
&DoMsg("Control file trace: $ControlfileTrace");
&DoMsg("Init file: $InitName");
### remove old archives, redo_logs and control files!
rmtree($baseACFS . '/fra/' . $DestDB , 1, 1 );
mkpath($baseACFS . '/fra/' . $DestDB );
## HERE WE HAVE THE CONTROL AND INIT READY TO BE MODIFIED
open(FILE, "<$ControlfileTrace");
my @ControlLines = <FILE>;
close(FILE);
# sed controlfile
my @NewControlLines;
push(@NewControlLines,"SET ECHO ON;\n");
push(@NewControlLines,"WHENEVER SQLERROR EXIT FAILURE;\n");
push(@NewControlLines,"CREATE SPFILE FROM PFILE='$InitName';\n");
foreach(@ControlLines) {
# change the snapshot name in the paths
$_ =~ s/u02\/$BaseDB/u02\/$DestDB/gi;
# change the db_unique_name in the REDO paths
$_ =~ s/fra\/$dbUniqueName/fra\/$DestDB/gi;
# change the dbname in the create controlfile line
$_ =~ s/CREATE CONTROLFILE.*$/CREATE CONTROLFILE REUSE SET DATABASE "$DestDB" RESETLOGS NOARCHIVELOG/;
# everything after and including "recover database" can be skipped
if ($_ =~ /^RECOVER DATABASE /) {
last;
}
print ($_);
push(@NewControlLines, $_);
}
push(@NewControlLines,"ALTER DATABASE OPEN RESETLOGS;\n");
push(@NewControlLines,"ALTER TABLESPACE TEMP ADD TEMPFILE SIZE 1G;\n");
push(@NewControlLines,"SELECT status FROM v\$instance;\n");
push(@NewControlLines,"QUIT;\n");
# write the new controlfile:
open(FILE, ">$ControlfileTrace");
print FILE @NewControlLines;
close(FILE);
# delete old controlfile
# no more necessary, deleted above unlink ($DestPath.'/control01.ctl');
# sed init file
open(FILE, "<$InitName");
my @InitLines = <FILE>;
close(FILE);
@InitLines = grep(!/^$BaseDB/i, @InitLines);
@InitLines = grep(!/^\*\.db_name/, @InitLines);
@InitLines = grep(!/^\*\.db_unique_name/, @InitLines);
@InitLines = grep(!/^\*\.dispatchers/, @InitLines);
@InitLines = grep(!/^\*\.audit_file_dest/, @InitLines);
@InitLines = grep(!/^\*\.fal_server/, @InitLines);
@InitLines = grep(!/^\*\.fal_client/, @InitLines);
@InitLines = grep(!/^\*\.log_archive_config/, @InitLines);
@InitLines = grep(!/^\*\.log_archive_dest/, @InitLines);
@InitLines = grep(!/^\*\.memory_target/, @InitLines);
@InitLines = grep(!/^\*\.sga_target/, @InitLines);
@InitLines = grep(!/^\*\.pga_aggregate_target/, @InitLines);
@InitLines = grep(!/^\*\.service_names/, @InitLines);
@InitLines = grep(!/^\*\.dg_broker_start/, @InitLines);
my @NewInitLines;
foreach(@InitLines ) {
# change only the snapshot name in the paths
$_ =~ s/u02\/$BaseDB/u02\/$DestDB/gi;
$_ =~ s/fra\/$dbUniqueName/fra\/$DestDB/gi;
print ($_);
push(@NewInitLines, $_);
}
push(@NewInitLines, "*.db_name='$DestDB'\n");
push(@NewInitLines, "*.db_unique_name='$DestDB'\n");
push(@NewInitLines, "*.dispatchers='(PROTOCOL=TCP)(SERVICE=${DestDB}XDB)'\n");
push(@NewInitLines, "*.log_archive_dest_1='location=USE_DB_RECOVERY_FILE_DEST'\n");
push(@NewInitLines, "*.sga_target=1G\n");
push(@NewInitLines, "*.pga_aggregate_target=100M\n");
push(@NewInitLines, "*.service_names='$DestDB'\n");
#push(@NewInitLines, "*.\n");
# write the new init file
open(FILE, ">$InitName");
print FILE @NewInitLines;
close(FILE);
$ENV{ORACLE_SID}=$DestDB;
$cmd = "$ORACLE_HOME/bin/sqlplus / as sysdba \@$ControlfileTrace";
&DoMsg($cmd);
open( CMD, $cmd . " |");
print (join("", <CMD>)); ## only print here as it logs and echoes its time as well
close CMD;
#if ( $? != 0 ) {
# &DoMsg("Error creating the new snapshot for $DestDB. Exiting.");
# exit(1);
#}
&DoMsg("New database snapshot $DestDB created successfully!");
&DoMsg("Starting using srvctl:");
my $cmd = "$ORACLE_HOME/bin/srvctl start database -d $DestDB";
&DoMsg ($cmd);
open( CMD, $cmd . " |");
&DoMsg (join("", <CMD>));
close CMD;
#if ( $? != 0 ) {
# &DoMsg ("Destination database cannot be started using srvctl");
# exit 1;
#}
#
#-------------------------------------------------------------------------------
# DoMsg
#
# PURPOSE : echo with timestamp YYYY-MM-DD_H24:MI:SS
# PARAMS : $*: the messages
# GLOBAL VARS: none
#-------------------------------------------------------------------------------
sub DoMsg {
my $msg = shift;
my $timestamp = &getTimestamp;
print ("$timestamp $msg\n");
if (fileno(MAINLOG)) {print MAINLOG "$timestamp $msg\n";}
}
#-------------------------------------------------------------------------------
# getTimestamp
#
# PURPOSE : returns timestamp in different formats
# PARAMS : format_parm
# GLOBAL VARS: none
#-------------------------------------------------------------------------------
sub getTimestamp {
#
# Format 1: dd-mm-yyyy_hh24:mi:ss
# Format 2: dd.mm.yyyy_hh24miss
# Format 3: dd.mm.yyyy
# Format 4: hh24:mi:ss
# Rest: dd.mm.yyyy hh24:mi:ss (default)
#
my $Parm = shift;
my $date;
my $date2;
my $heure;
my $heure2;
my ($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst);
if ( length($Parm) > 1 ) {
($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime($Parm);
}
else {
($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime;
}
$date = (sprintf "%2.0d",($mday)).".".(sprintf "%2.0d",($mon+1)).".".($year+1900);
$date =~ s/ /0/g;
$date2 = (sprintf "%2.0d",($mday))."-".(sprintf "%2.0d",($mon+1))."-".($year+1900);
$date2 =~ s/ /0/g;
$heure = (sprintf "%2.0d",($hour)).":".(sprintf "%2.0d",($min)).":".(sprintf "%2.0d",($sec));
$heure =~ s/ /0/g;
$heure2 = (sprintf "%2.0d",($hour)).(sprintf "%2.0d",($min)).(sprintf "%2.0d",($sec));
$heure2 =~ s/ /0/g;
if ($Parm eq "1") { return ($date2."_".$heure) }
elsif ($Parm eq "2") { return ($date."_".$heure2) }
elsif ($Parm eq "3") { return ($date) }
elsif ($Parm eq "4") { return ($heure) }
else { return ($date." ".$heure) };
}
#-------------------------------------------------------------------------------
# getWeekDay
#
# PURPOSE : returns weekday (Sun - Sat)
# GLOBAL VARS: none
#-------------------------------------------------------------------------------
sub getWeekDay{
my @date = split(" ", localtime(time));
my $day = $date[0];
return ($day);
}
#-------------------------------------------------------------------------------
# callSQLPLUS
#
# PURPOSE : calls the rman utility
# PARAMS : rman script name
# GLOBAL VARS: ReturnStatus, LogFile
#-------------------------------------------------------------------------------
#sub callSQLPLUS {
# my $script = shift;
# open( SQL, "$ORACLE_HOME/bin/sqlplus /nolog \@$script |");
# &DoMsg (join("", <SQL>));
# if ( $? != 0 ) { $rc = 1; } # RC if last call create an error
# close SQL;
#}
#-------------------------------------------------------------------------------
# Usage
#
# PURPOSE : print the Usage
# PARAMS : none
# GLOBAL VARS: none
#-------------------------------------------------------------------------------
sub Usage {
print <<EOF
Usage: $basename -b <base> [Optional Arguments]
-b <base> : db_name of the source database
-d <base> : name of the destination database
-s <snapshot> : name of the snapshot to be used
Purpose:
Create a new snapshot of a standby database by apply-off, backup controlfile to trace, copy init, acfs snap, apply-on.
Optional Arguments:
-u <db_unique_name> : name of the db_unique_name of the source database. if not specified, it will be taked from the source db, but it must be mounted!
this parameter is used only for pattern replacement inside control file trace and init file.
examples:
$basename -b stout -s stout_save.Wed -d poug2648
will clone stout from snapshot $baseACFS/.ACFS/snaps/stout_save.Wed to poug2648
THE EXISTING DESTINATION DATABASE SNAPSHOT WILL BE DROPPED!!
EOF
}
sub ConnectDB {
# DB connection #
$ENV{ORACLE_HOME}=$ORACLE_HOME;
$ENV{ORACLE_SID}=$BaseDB;
delete $ENV{TWO_TASK};
&DoMsg ("Connecting to DB $BaseDB");
&DoMsg ("OH: $ORACLE_HOME");
&DoMsg ("SID: $BaseDB");
unless ($dbh = DBI->connect('dbi:Oracle:', "sys", "Vagrant1_", {PrintError=>0, AutoCommit => 0, ora_session_mode => ORA_SYSDBA})) {
&DoMsg ("Error connecting to DB: ". $DBI::errstr);
exit(1);
}
#&DoMsg ("Connected to DB $BaseDB");
}
sub QueryOneValue {
my $sth;
my $query = shift;
unless ($sth = $dbh->prepare ($query)) {
&DoMsg ("Error preparing statement $query: ".$dbh->errstr);
}
$sth->execute;
my ($result) = $sth->fetchrow_array;
return $result;
}
sub DisconnectDB {
$dbh->disconnect;
}

 Oracle Rapid Home Provisioning simplifies tremendously the software provisioning: you can use it to create golden images starting from existing installations and then deploy them locally, across different nodes, on local or remote clusters, standalone servers, etc.
Oracle Rapid Home Provisioning simplifies tremendously the software provisioning: you can use it to create golden images starting from existing installations and then deploy them locally, across different nodes, on local or remote clusters, standalone servers, etc.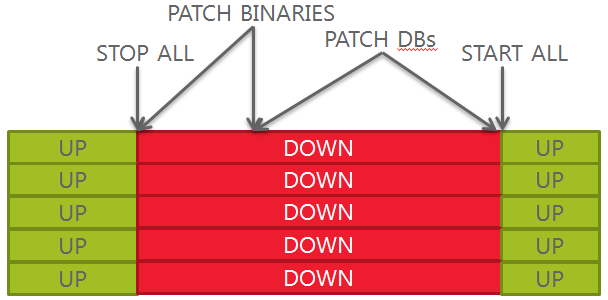
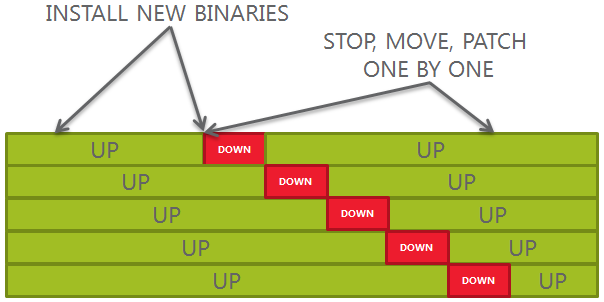
![2018-05-03 16_26_38-Diaporama PowerPoint - [Présentation1]](https://www.ludovicocaldara.net/dba/wp-content/uploads/2018/05/2018-05-03-16_26_38-Diaporama-PowerPoint-Présentation1.png)