
Last part of the blog series… let’s see how to put everything together and have a single script that creates and provisions Oracle Home golden images:
Review of the points
The scripts will:
- let create a golden image based on the current Oracle Home
- save the golden image metadata into a repository (an Oracle schema somewhere)
- list the avilable golden images and display whether they are already deployed on the current host
- let provision an image locally (pull, not push), either with the default name or a new name
Todo:
- Run as root in order to run root.sh automatically (or let specify the sudo command or a root password)
- Manage Grid Infrastructure homes
Assumptions
- There is an available Oracle schema where the golden image metadata will be stored
- There is an available NFS share that contains the working copies and golden images
- Some variables must be set accordingly to the environment in the script
- The function setoh is defined in the environment (it might be copied inside the script)
- The Instant Client is installed and “setoh ic” correctly sets its environment. This is required because there might be no sqlplus binaries available at the very first deploy
- Oracle Home name and path’s basename are equal for all the Oracle Homes
Repository table
First we need a metadata table. Let’s keep it as simple as possible:
|
1 2 3 4 5 6 |
CREATE TABLE "OH_GOLDEN_IMAGES" ( NAME VARCHAR2(50 BYTE) , FULLPATH VARCHAR2(200 BYTE) , CREATED TIMESTAMP (6) , CONSTRAINT PK_OH_GOLDEN_IMAGES PRIMARY KEY (NAME) ); |
Helpers
The script has some functions that check stuff inside the central inventory.
e.g.
|
1 2 3 4 5 6 7 8 9 |
F_OH_Installed () { CENTRAL_ORAINV=`grep ^inventory_loc /etc/oraInst.loc | awk -F= '{print $2}'` grep "<HOME NAME=\"$1\"" $CENTRAL_ORAINV/ContentsXML/inventory.xml | grep -v "REMOVED=\"T\"" >/dev/null if [ $? -eq 0 ] ; then echo -e "${colgrn}Installed${colrst}" else echo "Not installed" fi } |
checks if a specific Oracle Home (name) is present in the central inventory. It is helpful to check, for every golden image in the matadata repository, if it is already provisioned or not:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
F_list_OH () { F_colordef echo echo "Listing existing golden images:" RESULT=`$SQLPLUS -S -L ${REPO_CREDENTIALS} <<EOF | grep ";" set line 200 pages 1000 set feed off head off col name format a32 alter session set nls_timestamp_format='YYYY-MM-DD'; select name||';'||created||';'||fullpath from oh_golden_images order by created desc; EOF ` echo printf "%-35s %-10s %-18s\n" "OH_Name" "Created" "Installed locally?" echo "----------------------------------- ---------- ------------------" for line in $RESULT ; do L_GI_Name=`echo $line | awk -F\; '{print $1}'` L_GI_Date=`echo $line | awk -F\; '{print $2}'` L_GI_Path=`echo $line | awk -F\; '{print $3}'` L_Installed=`F_OH_Installed "$L_GI_Name"` printf "%-35s %-10s %-18s\n" "$L_GI_Name" "$L_GI_Date" "$L_Installed" done } |
Variables
Some variables must be changed, but in general you might want to adapt the whole script to fit your needs.
|
1 2 3 4 5 6 7 8 |
REPO_OWNER=scott REPO_PWD=tiger REPO_CONN="//localhost:1521/ORCL" REPO_CREDENTIALS=${REPO_OWNER}/${REPO_PWD}@${REPO_CONN} PRODUCT_INSTALL_PATH="/u01/app/oracle/product" GOLDEN_IMAGE_DEST="/share/oracle/oh_repository/golden_images" WORKING_COPY_DEST="/share/oracle/oh_repository/working_copies" |
Image creation
The image creation would be as easy as creating a zip file, but there are some files that we do not want to include in the golden image, therefore we need to create a staging directory (working copy) to clean up everything:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
# Copy to NFS working copy echo "Cleaning previous working copy" WC=$WORKING_COPY_DEST/$L_New_Name [ -d $WC ] && rm -rf $WC echo "Copying the OH to the working copy" mkdir -p $WC cp -rp $ORACLE_HOME/* $WC/ 2>/tmp/ohctl.err # Cleanup files echo "Cleansing files in Working Copy" rm -rf $WC/log/$HOSTNAME rm -rf $WC/log/diag/rdbms/* rm -rf $WC/gpnp/$HOSTNAME find $WC/gpnp -type f -exec rm {} \; 2>/dev/null rm -rf $WC/cfgtoollogs/* rm -rf $WC/crs/init/* rm -rf $WC/cdata/* rm -rf $WC/crf/* rm -rf $WC/admin/* rm -rf $WC/network/admin/*.ora rm -rf $WC/crs/install/crsconfig_params find $WC -name '*.ouibak' -exec rm {} \; 2>/dev/null find $WC -name '*.ouibak.1' -exec rm {} \; 2>/dev/null # rm -rf $WC/root.sh find $WC/rdbms/audit -name '*.aud' -exec rm {} \; 2>/dev/null rm -rf $WC/rdbms/log/* rm -rf $WC/inventory/backup/* rm -rf $WC/dbs/* # create zip echo "Creating the Golden Image zip file" [ -f $GOLDEN_IMAGE_DEST/$L_New_Name.zip ] && rm $GOLDEN_IMAGE_DEST/$L_New_Name.zip pushd $WC zip -r $GOLDEN_IMAGE_DEST/$L_New_Name.zip . >/dev/null popd $OLDPWD |
Home provisioning
Home provisioning requires, beside some checks, a runInstaller -clone command, eventually a relink, eventually a setasmgid, eventually some other tasks, but definitely run root.sh. This last task is not automated yet in my deployment script.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
# ... some checks ... # if no new OH name specified, get the golden image name ... # - check if image to install exists ... # - check if OH name to install is not already installed ... # - check if the zip exists ... # - check if the destination directory exist ... L_Clone_Command="$RUNINST -clone -waitForCompletion -silent ORACLE_HOME=$ORACLE_HOME ORACLE_BASE=$ORACLE_BASE ORACLE_HOME_NAME=$L_New_Name" echo $L_Clone_Command $L_Clone_Command if [ $? -eq 0 ] ; then echo "Clone command completed successfully." else echo "There was a problem during the clone command. The script will exit." exit 1 fi if [ "${L_Link_RAC}" == "yes" ] ; then pushd $ORACLE_HOME/rdbms/lib make -f ins_rdbms.mk rac_on make -f ins_rdbms.mk ioracle popd fi # - run setasmgid if [ -x /etc/oracle/setasmgid ] ; then echo "setasmgid found: running it on Oracle binary" /etc/oracle/setasmgid oracle_binary_path=$ORACLE_HOME/bin/oracle else echo "setasmgid not found: ignoring" fi # - create symlinks for ldap, sqlnet and tnsnames.ora TNS_ADMIN=${TNS_ADMIN:-/var/opt/oracle} ln -s $TNS_ADMIN/sqlnet.ora $ORACLE_HOME/network/admin/sqlnet.ora ln -s $TNS_ADMIN/tnsnames.ora $ORACLE_HOME/network/admin/tnsnames.ora ln -s $TNS_ADMIN/ldap.ora $ORACLE_HOME/network/admin/ldap.ora # ... other checks ... |
Usage
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
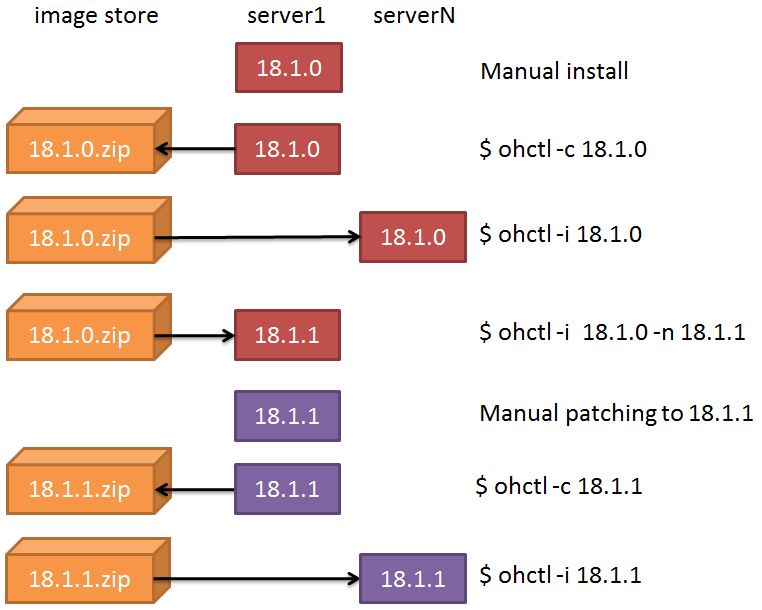
Purpose : Management of Golden Images (Oracle Homes) Usage : To list the available images: ohctl -l To install an image on the localhost: ohctl -i goldenimage [-n newname] [-r] To create an image based on the current OH: ohctl -c [-n newname] [ -f ] To remove a golden image from the repository: ohctl -d goldenimage [ -f ] Options : -l List the available Oracle Homes in the golden image repository -i goldenimage Installs locally the specified golden image. (If already deployed, an error is thrown) if the option -l is given, the list action has the priority over the deploy. -n newname Specify a new name for the Oracle Home: use it in case you need to patch and create a new Golden Image from it or if you want to change the Golden Image name for the current Oracle Home you are converting to Image. When creating a new Image (-c), it takes the basename of the OH by default, and not the OHname inside the inventory. -c Creates a new Golden Image from the current Oracle Home. -d goldenimage Removes the golden image from the repository -f If the Golden Image to be created exists, force the overwrite. -r Relink with RAC option (install only) Example : ohctl -i DB12_1_0_2_BP170718_home1 -n DB12_1_0_2_BP171018_home1 installs the Oracle Home DB12_1_0_2_BP170718_home1 with new name DB12_1_0_2_BP171018_home1 in order to apply the Bundle Patch 171018 on it ohctl -i DB12_1_0_2_BP170718_home1 installs the Oracle Home DB12_1_0_2_BP170718_home1 for normal usage ohctl -c -n DB12_1_0_2_BP180116 Creates a new Golden Image named DB12_1_0_2_BP180116 from the current ORACLE_HOME ohctl -c -f Creates a new Golden Image with the name of the current OH basename, overwriting the eventual existing image. E.g. if the current OH is /ccv/app/oracle/product/DB12_1_0_2_BP180116, the new GI name will be "DB12_1_0_2_BP180116" |
Examples
List installed homes:
|
1 2 3 4 5 6 7 8 9 10 |
# [ oracle@myserver:/u01/app/oracle/scripts [17:43:04] [12.1.0.2.0 SID=GRID] 0 ] # # lsoh HOME LOCATION VERSION EDITION --------------------------- ------------------------------------------------------- ------------ --------- OraGI12Home1 /u01/app/grid/product/grid 12.1.0.2.0 GRID OraDB12Home1 /u01/app/oracle/product/12.1.0.2 12.1.0.2.0 DBMS EE agent12c1 /u01/app/oracle/product/agent12c/core/12.1.0.5.0 12.1.0.5.0 AGT OraDb11g_home1 /u01/app/oracle/product/11.2.0.4 11.2.0.4.0 DBMS EE OraDB12Home2 /u01/app/oracle/product/12.1.0.2_BP170718 12.1.0.2.0 DBMS EE |
Create a golden image 12_1_0_2_BP170718 from the Oracle Home named OraDB12Home2 (tha latter having been installed manually without naming convention):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# [ oracle@myserver:/u01/app/oracle/scripts [17:43:07] [12.1.0.2.0 SID=GRID] 0 ] # # setoh OraDB12Home2 # [ oracle@myserver:/u01/app/oracle/scripts [17:43:04] [12.1.0.2.0 SID=GRID] 0 ] # # ohctl -c -n 12_1_0_2_BP170718 -f Image 12_1_0_2_BP170718 already exists but -f specified. The script will continue. Creating the new Golden Image 12_1_0_2_BP170718 Cleaning previous working copy Copying the OH to the working copy Cleansing files in Working Copy Creating the Golden Image zip file # [ oracle@myserver:/u01/app/oracle/scripts [17:52:09] [12.1.0.2.0 SID=GRID] 0 ] # # |
List the new golden image from the metadata repository:
|
1 2 3 4 5 6 7 8 |
# [ oracle@myserver:/u01/app/oracle/scripts [17:57:46] [12.1.0.2.0 SID=GRID] 0 ] # # ohctl -l Listing existing golden images: OH_Name Created Installed locally? ----------------------------------- ---------- ------------------ 12_1_0_2_BP170718 2018-02-06 Not installed |
Reinstalling the same home with the new naming convention:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
# ohctl -i 12_1_0_2_BP170718 OK, the image exists. Zip file exists. The unzip completed successfully. /u01/app/oracle/product/12_1_0_2_BP170718/oui/bin/runInstaller -clone -waitForCompletion -silent ORACLE_HOME=/u01/app/oracle/product/12_1_0_2_BP170718 ORACLE_BASE=/u01/app/oracle ORACLE_HOME_NAME=12_1_0_2_BP170718 Starting Oracle Universal Installer... Checking swap space: must be greater than 500 MB. Actual 16383 MB Passed Preparing to launch Oracle Universal Installer from /tmp/OraInstall2018-02-06_06-04-33PM. Please wait ...Oracle Universal Installer, Version 12.1.0.2.0 Production Copyright (C) 1999, 2014, Oracle. All rights reserved. You can find the log of this install session at: /u01/app/oracle/oraInventory/logs/cloneActions2018-02-06_06-04-33PM.log .................................................................................................... 100% Done. Installation in progress (Tuesday, February 6, 2018 6:04:41 PM CET) ................................................................................ 80% Done. Install successful Linking in progress (Tuesday, February 6, 2018 6:04:44 PM CET) . 81% Done. Link successful Setup in progress (Tuesday, February 6, 2018 6:05:01 PM CET) .......... 100% Done. Setup successful Saving inventory (Tuesday, February 6, 2018 6:05:01 PM CET) Saving inventory complete Configuration complete End of install phases.(Tuesday, February 6, 2018 6:05:22 PM CET) WARNING: The following configuration scripts need to be executed as the "root" user. /u01/app/oracle/product/12_1_0_2_BP170718/root.sh To execute the configuration scripts: 1. Open a terminal window 2. Log in as "root" 3. Run the scripts The cloning of 12_1_0_2_BP170718 was successful. Please check '/u01/app/oracle/oraInventory/logs/cloneActions2018-02-06_06-04-33PM.log' for more details. Clone command completed successfully. setasmgid found: running it on Oracle binary The image 12_1_0_2_BP170718 has been installed and exists in the inventory. Installation completed. Please run /u01/app/oracle/product/12_1_0_2_BP170718/root.sh as root before using the new home. # [ oracle@myserver:/u01/app/oracle/scripts [18:05:24] [12.1.0.2.0 SID=GRID] 0 ] # # # and manually... -bash-4.2$ sudo /u01/app/oracle/product/12_1_0_2_BP170718/root.sh Check /u01/app/oracle/product/12_1_0_2_BP170718/install/root_myserver_2018-02-06_18-06-07.log for the output of root script |
Installing the same home in a new path for manual patching from 170718 to 180116:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
# [ oracle@myserver:/u01/app/oracle/scripts [12:48:36] [12.1.0.2.0 SID=GRID] 0 ] # # ohctl -i 12_1_0_2_BP170718 -n 12_1_0_2_BP180116 OK, the image exists. Zip file exists. The unzip completed successfully. /u01/app/oracle/product/12_1_0_2_BP180116/oui/bin/runInstaller -clone -waitForCompletion -silent ORACLE_HOME=/u01/a pp/oracle/product/12_1_0_2_BP180116 ORACLE_BASE=/u01/app/oracle ORACLE_HOME_NAME=12_1_0_2_BP180116 Starting Oracle Universal Installer... Checking swap space: must be greater than 500 MB. Actual 16383 MB Passed Preparing to launch Oracle Universal Installer from /tmp/OraInstall2018-02-07_12-49-50PM. Please wait ...Oracle Univers al Installer, Version 12.1.0.2.0 Production Copyright (C) 1999, 2014, Oracle. All rights reserved. You can find the log of this install session at: /u01/app/oracle/oraInventory/logs/cloneActions2018-02-07_12-49-50PM.log .................................................................................................... 100% Done. Installation in progress (Wednesday, February 7, 2018 12:49:58 PM CET) ................................................................................ 80% Done. Install successful Linking in progress (Wednesday, February 7, 2018 12:50:00 PM CET) . 81% Done. Link successful Setup in progress (Wednesday, February 7, 2018 12:50:17 PM CET) .......... 100% Done. Setup successful Saving inventory (Wednesday, February 7, 2018 12:50:17 PM CET) Saving inventory complete Configuration complete End of install phases.(Wednesday, February 7, 2018 12:50:38 PM CET) WARNING: The following configuration scripts need to be executed as the "root" user. /u01/app/oracle/product/12_1_0_2_BP180116/root.sh To execute the configuration scripts: 1. Open a terminal window 2. Log in as "root" 3. Run the scripts The cloning of 12_1_0_2_BP180116 was successful. Please check '/u01/app/oracle/oraInventory/logs/cloneActions2018-02-07_12-49-50PM.log' for more details. Clone command completed successfully. setasmgid found: running it on Oracle binary The image 12_1_0_2_BP180116 has been installed and exists in the inventory. Installation completed. Please run /u01/app/oracle/product/12_1_0_2_BP180116/root.sh as root before using the new home. |
New home situation:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# [ oracle@myserver:/u01/app/oracle/scripts [12:50:41] [12.1.0.2.0 SID=GRID] 0 ] # # lsoh HOME LOCATION VERSION EDITION --------------------------- ------------------------------------------------------- ------------ -------- - OraGI12Home1 /u01/app/grid/product/grid 12.1.0.2.0 GRID OraDB12Home1 /u01/app/oracle/product/12.1.0.2 12.1.0.2.0 DBMS EE agent12c1 /u01/app/oracle/product/agent12c/core/12.1.0.5.0 12.1.0.5.0 AGT OraDb11g_home1 /u01/app/oracle/product/11.2.0.4 11.2.0.4.0 DBMS EE OraDB12Home2 /u01/app/oracle/product/12.1.0.2_BP170718 12.1.0.2.0 DBMS EE 12_1_0_2_BP170718 /u01/app/oracle/product/12_1_0_2_BP170718 12.1.0.2.0 DBMS EE 12_1_0_2_BP180116 /u01/app/oracle/product/12_1_0_2_BP180116 12.1.0.2.0 DBMS EE |
Patch manually the home named 12_1_0_2_BP180116 with the January bundle patch:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 |
# [ oracle@myserver:/u01/app/oracle/scripts [18:07:00] [12.1.0.2.0 SID=GRID] 0 ] # # setoh 12_1_0_2_BP170718 # [ oracle@myserver:/share/oracle/database/patches/12c/12.1.0.2.BP180116/27010930/26925263 [12:55:58] [12.1.0.2.0 SID=GRID] 0 ] # # opatch apply Oracle Interim Patch Installer version 12.2.0.1.12 Copyright (c) 2018, Oracle Corporation. All rights reserved. Oracle Home : /u01/app/oracle/product/12_1_0_2_BP180116 Central Inventory : /u01/app/oracle/oraInventory from : /u01/app/oracle/product/12_1_0_2_BP180116/oraInst.loc OPatch version : 12.2.0.1.12 OUI version : 12.1.0.2.0 Log file location : /u01/app/oracle/product/12_1_0_2_BP180116/cfgtoollogs/opatch/opatch2018-02-07_12- 54-50PM_1.log Verifying environment and performing prerequisite checks... OPatch continues with these patches: 26609798 26717470 26925263 Do you want to proceed? [y|n] y User Responded with: Y All checks passed. Please shutdown Oracle instances running out of this ORACLE_HOME on the local system. (Oracle Home = '/u01/app/oracle/product/12_1_0_2_BP180116') Is the local system ready for patching? [y|n] y User Responded with: Y Backing up files... Applying sub-patch '26609798' to OH '/u01/app/oracle/product/12_1_0_2_BP180116' Patching component oracle.oracore.rsf, 12.1.0.2.0... Patching component oracle.rdbms, 12.1.0.2.0... Patching component oracle.rdbms.rsf, 12.1.0.2.0... Applying sub-patch '26717470' to OH '/u01/app/oracle/product/12_1_0_2_BP180116' ApplySession: Optional component(s) [ oracle.oid.client, 12.1.0.2.0 ] , [ oracle.has.crs, 12.1.0.2.0 ] n ot present in the Oracle Home or a higher version is found. Patching component oracle.ldap.client, 12.1.0.2.0... Patching component oracle.rdbms.crs, 12.1.0.2.0... Patching component oracle.rdbms.deconfig, 12.1.0.2.0... Patching component oracle.xdk, 12.1.0.2.0... Patching component oracle.tfa, 12.1.0.2.0... Patching component oracle.rdbms, 12.1.0.2.0... Patching component oracle.rdbms.dbscripts, 12.1.0.2.0... Patching component oracle.nlsrtl.rsf, 12.1.0.2.0... Patching component oracle.xdk.parser.java, 12.1.0.2.0... Patching component oracle.xdk.rsf, 12.1.0.2.0... Patching component oracle.rdbms.rsf, 12.1.0.2.0... Patching component oracle.rdbms.rman, 12.1.0.2.0... Patching component oracle.rdbms.rman, 12.1.0.2.0... Patching component oracle.has.deconfig, 12.1.0.2.0... Applying sub-patch '26925263' to OH '/u01/app/oracle/product/12_1_0_2_BP180116' ApplySession: Optional component(s) [ oracle.has.crs, 12.1.0.2.0 ] not present in the Oracle Home or a h igher version is found. Patching component oracle.network.rsf, 12.1.0.2.0... Patching component oracle.rdbms.crs, 12.1.0.2.0... Patching component oracle.rdbms.util, 12.1.0.2.0... Patching component oracle.rdbms, 12.1.0.2.0... Patching component oracle.rdbms.dbscripts, 12.1.0.2.0... Patching component oracle.rdbms.rsf, 12.1.0.2.0... Patching component oracle.rdbms.rman, 12.1.0.2.0... Composite patch 26925263 successfully applied. Sub-set patch [22652097] has become inactive due to the application of a super-set patch [26925263]. Please refer to Doc ID 2161861.1 for any possible further required actions. Log file location: /u01/app/oracle/product/12_1_0_2_BP180116/cfgtoollogs/opatch/opatch2018-02-07_12-5 4-50PM_1.log OPatch succeeded. # [ oracle@myserver:/share/oracle/database/patches/12c/12.1.0.2.BP180116/27010930/26925263 [12:55:47] [12.1.0.2.0 SID=GRID] 0 ] # # opatch lspatches 26925263;Database Bundle Patch : 12.1.0.2.180116 (26925263) 22243983; OPatch succeeded. |
Create the new golden image from the home patched with January bundle patch:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# [ oracle@myserver:/u01/app/oracle/scripts [18:07:00] [12.1.0.2.0 SID=GRID] 0 ] # # setoh 12_1_0_2_BP180116 # [ oracle@myserver:/u01/app/oracle/scripts [12:57:24] [12.1.0.2.0 SID=GRID] 1 ] # # ohctl -c -f Creating the new Golden Image 12_1_0_2_BP180116 Cleaning previous working copy Copying the OH to the working copy Cleansing files in Working Copy Creating the Golden Image zip file # [ oracle@myserver:/u01/app/oracle/scripts [13:04:57] [12.1.0.2.0 SID=GRID] 0 ] # # ohctl -l Listing existing golden images: OH_Name Created Installed locally? ----------------------------------- ---------- ------------------ 12_1_0_2_BP180116 2018-02-07 Installed 12_1_0_2_BP170718 2018-02-06 Installed |
Full source code
I hope you find it useful! The cool thing is that once you have the golden images ready in the golden image repository, then the provisioning to all the servers is striaghtforward and requires just a couple of minutes, from nothing to a full working and patched Oracle Home.
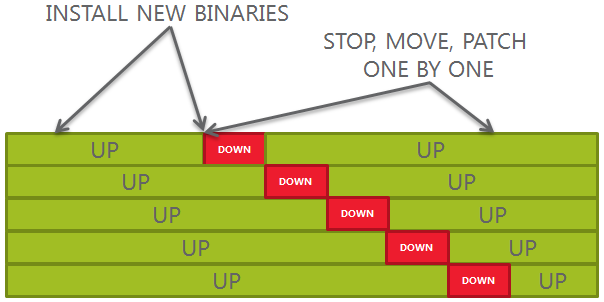
Why applying the patch manually?
If you read everything carefully, I automated the golden image creation and provisioning, but the patching is still done manually.
The aim of this framework is not to patch all the Oracle Homes with the same patch, but to install the patch ONCE and then deploy the patched home everywhere. Because each patch has different conflicts, bugs, etc, it might be convenient to install it manually the first time and then forget it. At least this is my opinion 🙂
Of course, patch download, conflict detection, etc. can also be automated (and it is a good idea, if you have the time to implement it carefully and bullet-proof).
In the addendum blog post, I will show some scripts made by Hutchison Austria and why I find them really useful in this context.
Blog posts in this series:
Oracle Home Management – part 1: Patch soon, patch often vs. reality
Oracle Home Management – part 2: Common patching patterns
Oracle Home Management – part 3: Strengths and limitations of Rapid Home Provisioning
Oracle Home Management – part 4: Challenges and opportunities of the New Release Model
Oracle Home Management – part 5: Oracle Home Inventory and Naming Conventions
Oracle Home Management – part 6: Simple Golden Image blueprint
Oracle Home Management – part 7: Putting all together
Oracle Home Management – Addendum: Managing and controlling the patch level (berx’s work)

![2018-05-03 16_26_38-Diaporama PowerPoint - [Présentation1]](https://www.ludovicocaldara.net/dba/wp-content/uploads/2018/05/2018-05-03-16_26_38-Diaporama-PowerPoint-Présentation1.png)