Oracle Database 12c says goodbye to a tool being around after the 10gR1: the Database Console.
OC4J for the 10g and weblogic for the 11g, both have had a non-negligible overhead on the systems, especially with many configured instances.
In many cases I’ve decided to switch to Grid/Cloud Control for the main reason to avoid too many db consoles, in other cases I’ve just disabled at all web management.
The new 12c brings a new tool called Database Express (indeed, very similar to its predecessors).
Where’s my emca/emctl?
The DB Express runs entirely with pl/sql code within the XDB schema. It’s XDB that leverages its features to enable a web-based console, and it’s embedded by default in the database.
To enable it, it’s necessary to check that the parameter dispatchers is enabled for XDB:
|
1 2 3 4 5 |
SQL> show parameter dispatchers NAME TYPE VALUE ----------- ------ ----------------------------------- dispatchers string (PROTOCOL=TCP) (SERVICE=CLASSICXDB) |
and then set an https port unique on the server:
|
1 2 3 4 5 |
SQL> exec dbms_xdb_config.sethttpsport (5502); PL/SQL procedure successfully completed. SQL> |
If you’ve already done it but you don’t remember the port number you can get it with this query:
|
1 2 3 4 5 |
SQL> select dbms_xdb_config.gethttpsport () from dual; DBMS_XDB_CONFIG.GETHTTPSPORT() ------------------------------ 5502 |
You can now access the web interface by using the address:
|
1 |
https://yourserver:5502/em |


Lower footprint, less features
From one side DB Express is thin (but not always fast on my laptop…), from the other it has clearly fewer features comparing to the DB Console.
It’s not clear to me if Oracle wants to make it more powerful in future releases or if it’s a move to force everybody to use something else (SQLDeveloper or EM12c Cloud Control). However the DBA management plugin of the current release of SQL Developer is fully compatible with the 12c, including the ability to manage pluggable databases: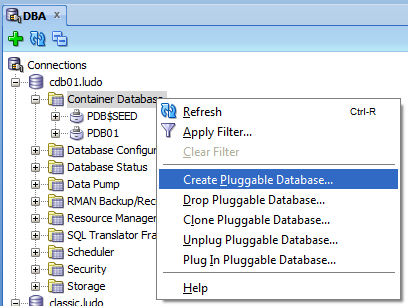
So is the EM 12c Cloud Control, so you have plenty of choice to manage your 12c databases from graphical interfaces.
Stay tuned!
Ludovico