
I am helping my customer for a PoC of Dbvisit Replicate as a logical replication tool. I will not discuss (at least, not in this post) about the capabilities of the tool itself, its configuration or the caveats that you should beware of when you do logical replication. Instead, I will concentrate on how we will likely integrate it in the current environment.
My role in this PoC is to make sure that the tool will be easy to operate from the operational point of view, and the database operations, here, are supported by Oracle Grid Infrastructure and cold failover clusters.
Note: there are official Dbvisit online resources about how to configure Dbvisit Replicate in a cluster. I aim to complement those informations, not copy them.
Quick overview
If you know Dbvisit replicate, skip this paragraph.
There are three main components of Dbvisit Replicate: The FETCHER, the MINE and the APPLY processes. The FETCHER gets the redo stream from the source and sends it to the MINE process. The MINE process elaborates the redo streams and converts it in proprietary transaction log files (named plog). The APPLY process gets the plog files and applies the transactions on the destination database.
From an architectural point of view, MINE and APPLY do not need to run close to the databases that are part of the configuration. The FETCHER process, by opposite, needs to be local to the source database online log files (and archived logs).
Because the MINE process is the most resource intensive, it is not convenient to run it where the databases reside, as it might consume precious CPU resources that are licensed for Oracle Database. So, first step in this PoC: the FETCHER processes will run on the cluster, while MINE and APPLY will run on a dedicated Virtual Machine.
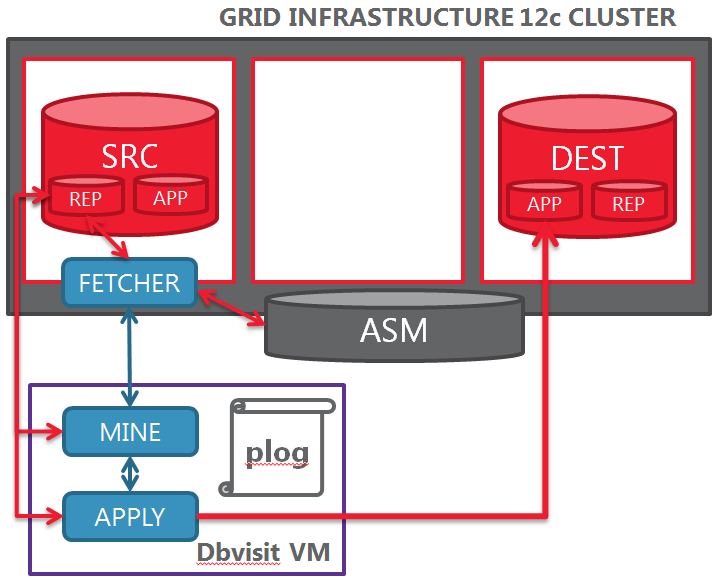
Clustering considerations
- the FETCHER does NOT need to run on the server of the source database: having access to the online logs through the ASM instance is enough
- to avoid SPoF, the fetcher should be a cluster resource that can relocate without problems
- to simplify the configuration, the FETCHER configuration and the Dbvisit binaries should be on a shared filesystem (the FETCHER does not persist any data, just the logs)
- the destination database might be literally anywhere: the APPLY connects via SQL*Net, so a correct name resolution and routing to the destination database are enough
so the implementation steps are:
- create a shared filesystem
- install dbvisit in the shared filesystem
- create the Dbvisit Replicate configuration on the dedicated VM
- copy the configuration files on the cluster
- prepare an action script
- configure the resource
- test!
Convention over configuration: the importance of a strong naming convention
Before starting the implementation, I decided to put all the caveats related to the FETCHER resource relocation on paper:
- Where will the configuration files reside? Dbvisit has an important variable: the Configuration Name. All the operations are done by passing a configuration file named /{PATH}/{CONFIG_NAME}/{CONFIG_NAME}-{PROCESS_TYPE}.ddc to the dbvrep binary. So, I decided to put ALL the configuration directories under the same path: given the Configuration Name, I will always be able to get the configuration file path.
- How will the configuration files relocate from one node to the other? Easy here: they won’t. I will use an ACFS filesystem
- How can I link the cluster resource with its configuration name? Easy again: I call my resources dbvrep.CONFIGNAME.PROCESS_TYPE. e.g. dbvrep.FROM_A_TO_B.fetcher
- How will I manage the need to use a new version of dbvisit in the future? Old and new versions must coexist: Instead of using external configuration files, I will just use a custom resource attribute named DBVREP_HOME inside my resource type definition. (see later)
- What port number should I use? Of course, many fetchers started on different servers should not have conflicts. This is something that might be either planned or made dynamic. I will opt for the first one. But instead of getting the port number inside the Dbvisit configuration, I will use a custom resource attribute: DBVREP_PORT.
Considerations on the FETCHER listen address
This requires a dedicated paragraph. The Dbvisit documentation suggest to create a VIP, bind on the VIP address and create a dependency between the FETCHER resource and the VIP. Here is where my configuration will differ.
Having a separate VIP per FETCHER resource might, potentially, lead to dozens of VIPs in the cluster. Everything will depend on the success of the PoC and on how many internal clients will decide to ask for such implementation. Many VIPs == many interactions with network admins for address reservation, DNS configurations, etc. Long story short, it might slow down the creation and maintenance of new configurations.
Instead, each FETCHER will listen to the local server address, and the action script will take care of:
- getting the current host name
- getting the current ASM instance
- changing the settings of the specific Dbvisit Replicate configuration (ASM instance and FETCHER listen address)
- starting the FETCHER
Implementation
Now that all the caveats and steps are clear, I can show how I implemented it:
Create a shared filesystem
|
1 2 3 4 |
asmcmd volcreate -G ACFS -s 10G dbvisit --column 1 /sbin/mkfs -t acfs /dev/asm/dbvisit-293 sudo /u01/app/grid/product/12.1.0.2/grid/bin/srvctl add filesystem -d /dev/asm/dbvisit-293 -m /u02/data/oracle/dbvisit -u oracle -fstype ACFS -autostart ALWAYS srvctl start filesystem -d /dev/asm/dbvisit-293 |
Install dbvisit in the shared filesystem
|
1 |
out of scope! |
Create the Dbvisit Replicate configuration on the dedicated VM
|
1 |
out of scope! |
Copy the configuration files from the Dbvisit VM to the cluster
|
1 2 |
scp /u02/data/oracle/dbvisit/FROM_A_TO_B/FROM_A_TO_B-FETCHER.ddc \ cluster-scan:/u02/data/oracle/dbvisit/FROM_A_TO_B |
Prepare an action script
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
$ cat dbvrep.sh #!/bin/ksh ######################################## # Name : dbvrep.sh # Author : Ludovico Caldara, Trivadis AG # the DBVISIT FETCHER process needs to know 2 attributes: DBVREP_HOME and DBVREP_PORT. # If you want to call the action script directly set: # _CRS_NAME=<resource name in format dbvrep.CONFIGNAME.fetcher> # _CRS_DBVREP_HOME=<dbvrep installation path> # _CRS_DBVREP_PORT=<listening port> DBVREP_RES_NAME=${_CRS_NAME} DBVREP_CONFIG_NAME=`echo $DBVREP_RES_NAME | awk -F. '{print $2}'` # MINE, FETCHER or APPLY? DBVREP_PROCESS_TYPE=`echo $DBVREP_RES_NAME | awk -F. '{print toupper($3)}'` DBVREP_HOME=${_CRS_DBVREP_HOME} DBVREP=${DBVREP_HOME}/dbvrep DBVREP_PORT=${_CRS_DBVREP_PORT} DBVREP_CONFIG_PATH=/u02/data/oracle/dbvisit DBVREP_CONFIG_FILE=${DBVREP_CONFIG_PATH}/${DBVREP_CONFIG_NAME}/${DBVREP_CONFIG_NAME}-${DBVREP_PROCESS_TYPE}.ddc function F_verify_dbvrep_up { ps -eaf | grep "[d]bvrep ${DBVREP_PROCESS_TYPE} $DBVREP_CONFIG_NAME" > /dev/null if [ $? -eq 0 ] ; then echo "OK" else echo "KO" exit 1 fi } ACTION="${1}" case "$ACTION" in 'start') LOCAL_ASM="+"`ps -eaf | grep [a]sm_pmon | awk -F+ '{print $NF}'`; if [ "${DBVREP_PROCESS_TYPE}" == "FETCHER" ] ; then $DBVREP --daemon --ddcfile ${DBVREP_CONFIG_FILE} --silent <<EOF set FETCHER.FETCHER_REMOTE_INTERFACE=${HOSTNAME}:${DBVREP_PORT} set FETCHER.FETCHER_LISTEN_INTERFACE=${HOSTNAME}:${DBVREP_PORT} set FETCHER.MINE_ASM=${LOCAL_ASM} start FETCHER EOF fi ;; 'stop') $DBVREP --daemon --ddcfile ${DBVREP_CONFIG_FILE} shutdown ${DBVREP_PROCESS_TYPE} ;; 'check') F_verify_dbvrep_up ;; 'clean') sleep 1 exit 0 ;; *) usage ;; esac |
Configure the resource
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
$ cat dbvrep.type ATTRIBUTE=ACTION_SCRIPT DEFAULT_VALUE=/path_to_action_script/dbvrep.ksh TYPE=STRING FLAGS=CONFIG ATTRIBUTE=SCRIPT_TIMEOUT DEFAULT_VALUE=120 TYPE=INT FLAGS=CONFIG ATTRIBUTE=DBVREP_PORT DEFAULT_VALUE= TYPE=INT FLAGS=CONFIG ATTRIBUTE=DBVREP_HOME DEFAULT_VALUE=/u02/data/oracle/dbvisit/replicate TYPE=STRING FLAGS=CONFIG ATTRIBUTE=SERVER_POOLS DEFAULT_VALUE=* TYPE=STRING FLAGS=CONFIG|HOTMOD ATTRIBUTE=START_DEPENDENCIES DEFAULT_VALUE=hard() weak(type:ora.listener.type,global:type:ora.scan_listener.type) pullup() TYPE=STRING FLAGS=CONFIG ATTRIBUTE=STOP_DEPENDENCIES DEFAULT_VALUE=hard() TYPE=STRING FLAGS=CONFIG ATTRIBUTE=RESTART_ATTEMPTS DEFAULT_VALUE=2 TYPE=INT FLAGS=CONFIG ATTRIBUTE=CHECK_INTERVAL DEFAULT_VALUE=60 TYPE=INT FLAGS=CONFIG ATTRIBUTE=FAILURE_THRESHOLD DEFAULT_VALUE=2 TYPE=INT FLAGS=CONFIG ATTRIBUTE=UPTIME_THRESHOLD DEFAULT_VALUE=8h TYPE=STRING FLAGS=CONFIG ATTRIBUTE=FAILURE_INTERVAL DEFAULT_VALUE=3600 TYPE=INT FLAGS=CONFIG $ crsctl add type dbvrep.type -basetype cluster_resource -file dbvrep.type $ crsctl add resource dbvrep.FROM_A_TO_B.fetcher -type dbvrep.type \ -attr "START_DEPENDENCIES=hard(db.source) pullup:always(db.source),STOP_DEPENDENCIES=hard(db.source),DBVREP_PORT=7901" |
Test!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
$ crsctl start res dbvrep.FROM_A_TO_B.fetcher CRS-2672: Attempting to start 'dbvrep.FROM_A_TO_B.fetcher' on 'server1' CRS-2676: Start of 'dbvrep.FROM_A_TO_B.fetcher' on 'server1' succeeded ..in the logs.. 2017-10-30 15:24:34.992478 : AGFW:1127589632: {1:30181:30166} Agent received the message: RESOURCE_START[dbvrep.FROM_A_TO_B.fetcher 1 1] ID 4098:5175912 2017-10-30 15:24:34.992512 : AGFW:1127589632: {1:30181:30166} Preparing START command for: dbvrep.FROM_A_TO_B.fetcher 1 1 2017-10-30 15:24:34.992521 : AGFW:1127589632: {1:30181:30166} dbvrep.FROM_A_TO_B.fetcher 1 1 state changed from: OFFLINE to: STARTING 2017-10-30 15:24:34.993195 :CLSDYNAM:1106577152: [dbvrep.FROM_A_TO_B.fetcher]{1:30181:30166} [start] Executing action script: dbvrep.ksh[start] 2017-10-30 15:24:41.254703 :CLSDYNAM:1106577152: [dbvrep.FROM_A_TO_B.fetcher]{1:30181:30166} [start] Variable FETCHER_REMOTE_INTERFACE set to server1:7901 for process 2017-10-30 15:24:41.254726 :CLSDYNAM:1106577152: [dbvrep.FROM_A_TO_B.fetcher]{1:30181:30166} [start] FETCHER. 2017-10-30 15:24:41.354916 :CLSDYNAM:1106577152: [dbvrep.FROM_A_TO_B.fetcher]{1:30181:30166} [start] Variable FETCHER_LISTEN_INTERFACE set to server1:7901 for process 2017-10-30 15:24:41.354935 :CLSDYNAM:1106577152: [dbvrep.FROM_A_TO_B.fetcher]{1:30181:30166} [start] FETCHER. 2017-10-30 15:24:41.405052 :CLSDYNAM:1106577152: [dbvrep.FROM_A_TO_B.fetcher]{1:30181:30166} [start] Variable MINE_ASM set to +ASM1 for process FETCHER. 2017-10-30 15:24:41.605423 :CLSDYNAM:1106577152: [dbvrep.FROM_A_TO_B.fetcher]{1:30181:30166} [start] Starting process FETCHER...started 2017-10-30 15:24:41.655660 : AGFW:1106577152: {1:30181:30166} Command: start for resource: dbvrep.FROM_A_TO_B.fetcher 1 1 completed with status: SUCCESS 2017-10-30 15:24:41.656100 :CLSDYNAM:1081362176: [dbvrep.FROM_A_TO_B.fetcher]{1:30181:30166} [check] Executing action script: dbvrep.ksh[check] 2017-10-30 15:24:41.658242 : AGFW:1127589632: {1:30181:30166} Agent sending reply for: RESOURCE_START[dbvrep.FROM_A_TO_B.fetcher 1 1] ID 4098:5175912 2017-10-30 15:24:41.908256 :CLSDYNAM:1081362176: [dbvrep.FROM_A_TO_B.fetcher]{1:30181:30166} [check] OK 2017-10-30 15:24:41.908440 : AGFW:1127589632: {1:30181:30166} dbvrep.FROM_A_TO_B.fetcher 1 1 state changed from: STARTING to: ONLINE 2017-10-30 15:24:41.908486 : AGFW:1127589632: {1:30181:30166} Started implicit monitor for [dbvrep.FROM_A_TO_B.fetcher 1 1] interval=60000 delay=60000 2017-10-30 15:24:41.908696 : AGFW:1127589632: {1:30181:30166} Agent sending last reply for: RESOURCE_START[dbvrep.FROM_A_TO_B.fetcher 1 1] ID 4098:5175912 $ crsctl stop res dbvrep.FROM_A_TO_B.fetcher CRS-2673: Attempting to stop 'dbvrep.FROM_A_TO_B.fetcher' on 'server1' CRS-2677: Stop of 'dbvrep.FROM_A_TO_B.fetcher' on 'server1' succeeded ..in the logs.. 2017-10-30 15:22:14.891730 : AGFW:1127589632: {1:30181:30156} Agent received the message: RESOURCE_STOP[dbvrep.FROM_A_TO_B.fetcher 1 1] ID 4099:5175818 2017-10-30 15:22:14.891762 : AGFW:1127589632: {1:30181:30156} Preparing STOP command for: dbvrep.FROM_A_TO_B.fetcher 1 1 2017-10-30 15:22:14.891772 : AGFW:1127589632: {1:30181:30156} dbvrep.FROM_A_TO_B.fetcher 1 1 state changed from: ONLINE to: STOPPING 2017-10-30 15:22:14.892400 :CLSDYNAM:1091868416: [dbvrep.FROM_A_TO_B.fetcher]{1:30181:30156} [stop] Executing action script: dbvrep.ksh[stop] 2017-10-30 15:22:20.957375 :CLSDYNAM:1091868416: [dbvrep.FROM_A_TO_B.fetcher]{1:30181:30156} [stop] DDC loaded from database (458 variables). 2017-10-30 15:22:21.007939 :CLSDYNAM:1091868416: [dbvrep.FROM_A_TO_B.fetcher]{1:30181:30156} [stop] Dbvisit Replicate version 2.9.04 2017-10-30 15:22:21.007963 :CLSDYNAM:1091868416: [dbvrep.FROM_A_TO_B.fetcher]{1:30181:30156} [stop] Copyright (C) Dbvisit Software Limited. All rights reserved. 2017-10-30 15:22:21.007976 :CLSDYNAM:1091868416: [dbvrep.FROM_A_TO_B.fetcher]{1:30181:30156} [stop] DDC file 2017-10-30 15:22:21.007994 :CLSDYNAM:1091868416: [dbvrep.FROM_A_TO_B.fetcher]{1:30181:30156} [stop] /u02/data/oracle/dbvisit/FROM_A_TO_B/FROM_A_TO_B 2017-10-30 15:22:21.008005 :CLSDYNAM:1091868416: [dbvrep.FROM_A_TO_B.fetcher]{1:30181:30156} [stop] -FETCHER.ddc loaded. 2017-10-30 15:22:21.108340 :CLSDYNAM:1091868416: [dbvrep.FROM_A_TO_B.fetcher]{1:30181:30156} [stop] Dbvisit Replicate FETCHER process shutting down. 2017-10-30 15:22:21.108361 :CLSDYNAM:1091868416: [dbvrep.FROM_A_TO_B.fetcher]{1:30181:30156} [stop] OK-0: Completed successfully. 2017-10-30 15:22:45.747531 : AGFW:1091868416: {1:30181:30156} Command: stop for resource: dbvrep.FROM_A_TO_B.fetcher 1 1 completed with status: SUCCESS 2017-10-30 15:22:45.747898 : AGFW:1127589632: {1:30181:30156} Agent sending reply for: RESOURCE_STOP[dbvrep.FROM_A_TO_B.fetcher 1 1] ID 4099:5175818 2017-10-30 15:22:45.747902 :CLSDYNAM:1123387136: [dbvrep.FROM_A_TO_B.fetcher]{1:30181:30156} [check] Executing action script: dbvrep.ksh[check] 2017-10-30 15:22:45.949702 :CLSDYNAM:1123387136: [dbvrep.FROM_A_TO_B.fetcher]{1:30181:30156} [check] KO 2017-10-30 15:22:45.949913 : AGFW:1127589632: {1:30181:30156} dbvrep.FROM_A_TO_B.fetcher 1 1 state changed from: STOPPING to: OFFLINE 2017-10-30 15:22:45.950014 : AGFW:1127589632: {1:30181:30156} Agent sending last reply for: RESOURCE_STOP[dbvrep.dbvrep.FROM_A_TO_B.fetcher 1 1] ID 4098:5175818 |
Also the relocation worked as expected: when the settings are modified through:
|
1 2 3 |
set FETCHER.FETCHER_REMOTE_INTERFACE=${HOSTNAME}:${DBVREP_PORT} set FETCHER.FETCHER_LISTEN_INTERFACE=${HOSTNAME}:${DBVREP_PORT} set FETCHER.MINE_ASM=${LOCAL_ASM} |
The MINE process get the change dynamically, so no need to restart it.
Last consideration
Adding a hard dependency between the DB and the FETCHER will require to stop the DB with the force option or to always stop the fetcher before the database. Also, the start of the DB will pullup the FETCHER (pullup:always) and the opposite as well. We will consider furtherly if we will use this dependency or if we will manage it differently (e.g. through the action script).
The hard dependency declared without the global keyword, will always start the fetcher on the server where the database runs. This is not required, but it might be nice to see the fetcher on the same node. Again, a consideration that we will discuss furtherly.
HTH
—
Ludovico
Latest posts by Ludovico (see all)
- New views in Oracle Data Guard 23c - January 3, 2024
- New in Data Guard 21c and 23c: Automatic preparation of the primary - December 22, 2023
- Does FLASHBACK QUERY work across incarnations or after a Data Guard failover? - December 13, 2023
Pingback: Blog Post: My own Dbvisit Replicate integration with Grid Infrastructure
Pingback: My own Dbvisit Replicate integration with Grid Infrastructure - Ludovico Caldara - Blogs - triBLOG