A blog post series would not be complete without a final post about vacuumlo.
In the previous post we have seen that the large objects are split in tuples containing 2048 bytes each one, and each chunk behaves in the very same way as regular tuples.
What distinguish large objects?
NOTE: in PostgreSQL, IT IS possible to store a large amount of data along with the table, thanks to the TOAST technology. Read about TOAST here.
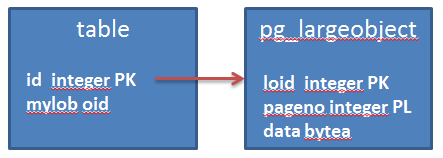
Large objects are not inserted in application tables, but are threated in a different way. The application using large objects usually has a table with columns of type OID. When the application creates a new large objects, a new OID number is assigned to it, and this number is inserted into the application table.
Now, a common mistake for people who come from other RDBMS (e.g. Oracle), think that a large object is unlinked automatically when the row that references
it is deleted. It is not, and we need to unlink it explicitly from the application.
Let’s see it with a simple example, starting with an empty pg_largeobject table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
lob_test=# vacuum full pg_largeobject; VACUUM lob_test=# select count(*) from pg_largeobject_metadata; count ------- 0 (1 row) lob_test=# select pg_relation_size('pg_largeobject')/8192 as pages; pages ------- 0 (1 row) |
Let’s insert a new LOB and reference it in the table t:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
lob_test=# CREATE TABLE t (id integer, file oid); CREATE TABLE lob_test=# \lo_import /tmp/zeroes lo_import 16546 lob_test=# INSERT INTO t VALUES (1, 16546); INSERT 0 1 lob_test=# select generate_series as pageno, (select count(*) from heap_page_items(get_raw_page('pg_largeobject',generate_series)) where t_infomask::bit(16) & x'0800'::bit(16) = x'0800'::bit(16)) from generate_series(0,4); pageno | count --------+------- 0 | 107 1 | 107 2 | 107 3 | 107 4 | 84 |
Another one:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
lob_test=# \lo_import /tmp/zeroes lo_import 16547 lob_test=# INSERT INTO t VALUES (2, 16547); INSERT 0 1 lob_test=# select generate_series as pageno, (select count(*) from heap_page_items(get_raw_page('pg_largeobject',generate_series)) where t_infomask::bit(16) & x'0800'::bit(16) = x'0800'::bit(16)) from generate_series(0,9); pageno | count --------+------- 0 | 107 1 | 107 2 | 107 3 | 107 4 | 107 5 | 107 6 | 107 7 | 107 8 | 107 9 | 61 (10 rows) lob_test=# select * from t; id | file ----+------- 1 | 16546 2 | 16547 (2 rows) |
If we delete the first one, the chunks of its LOB are still there, valid:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
lob_test=# DELETE FROM t WHERE id=1; DELETE 1 lob_test=# select * from t; id | file ----+------- 2 | 16547 (1 row) lob_test=# select generate_series as pageno, (select count(*) from heap_page_items(get_raw_page('pg_largeobject',generate_series)) where t_infomask::bit(16) & x'0800'::bit(16) = x'0800'::bit(16)) from generate_series(0,9); pageno | count --------+------- 0 | 107 1 | 107 2 | 107 3 | 107 4 | 107 5 | 107 6 | 107 7 | 107 8 | 107 9 | 61 (10 rows) |
If we want to get the rid of the LOB, we have to unlink it, either explicitly or by using triggers that unlink the LOB when a record in the application table is deleted.
Another way is to use the binary vacuumlo included in PostgreSQL.
It scans the pg_largeobject_metadata and search through the tables that have OID columns to find if there are any references to the LOBs. The LOB that are not referenced, are unlinked.
ATTENTION: this means that if you use ways to reference LOBs other than OID columns, vacuumlo might unlink LOBs that are still needed!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# vacuumlo -U postgres lob_test # p_ lob_test psql.bin (9.6.2) Type "help" for help. lob_test=# select generate_series as pageno, (select count(*) from heap_page_items(get_raw_page('pg_largeobject',generate_series)) where t_infomask::bit(16) & x'0800'::bit(16) = x'0800'::bit(16)) from generate_series(0,9); pageno | count --------+------- 0 | 0 1 | 0 2 | 0 3 | 0 4 | 23 5 | 107 6 | 107 7 | 107 8 | 107 9 | 61 (10 rows) |
vacuumlo has indeed unlinked the first LOB, but the deleted tuples are not freed until a vacuum is executed:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
lob_test=# \lo_import /tmp/zeroes lo_import 16551 lob_test=# INSERT INTO t VALUES (3, 16551); INSERT 0 1 lob_test=# select generate_series as pageno, (select count(*) from heap_page_items(get_raw_page('pg_largeobject',generate_series)) where t_infomask::bit(16) & x'0800'::bit(16) = x'0800'::bit(16)) from generate_series(0,14); pageno | count --------+------- 0 | 0 1 | 0 2 | 0 3 | 0 4 | 23 5 | 107 6 | 107 7 | 107 8 | 107 9 | 107 10 | 107 11 | 107 12 | 107 13 | 107 14 | 38 (15 rows) lob_test=# vacuum pg_largeobject; VACUUM lob_test=# \lo_import /tmp/zeroes lo_import 16552 lob_test=# INSERT INTO t VALUES (4, 16552); INSERT 0 1 lob_test=# select generate_series as pageno, (select count(*) from heap_page_items(get_raw_page('pg_largeobject',generate_series)) where t_infomask::bit(16) & x'0800'::bit(16) = x'0800'::bit(16)) from generate_series(0,14); pageno | count --------+------- 0 | 107 1 | 107 2 | 107 3 | 107 4 | 107 5 | 107 6 | 107 7 | 107 8 | 107 9 | 107 10 | 107 11 | 107 12 | 107 13 | 107 14 | 38 (15 rows) |
So vacuumlo does not do any vacuuming on pg_largeobject table.