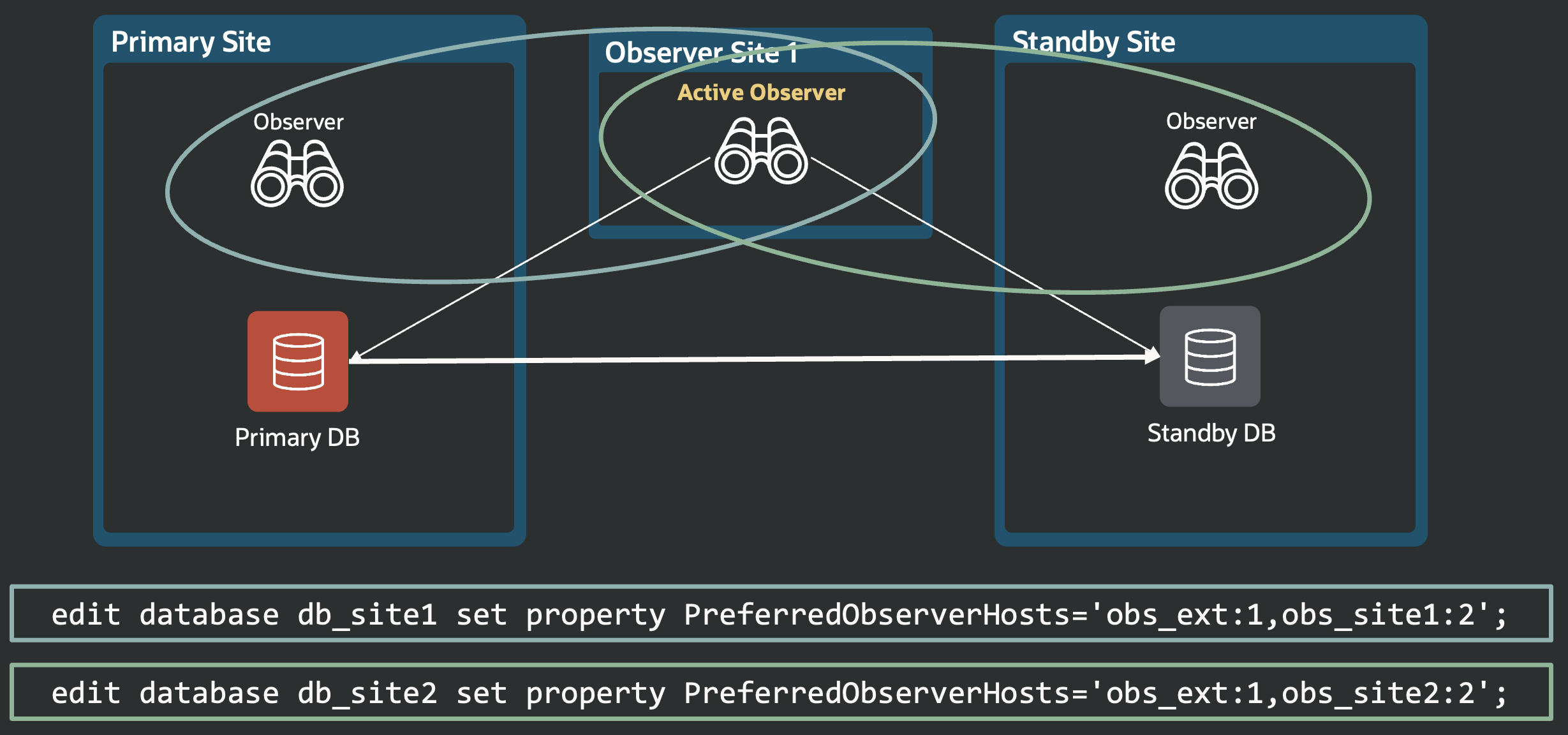
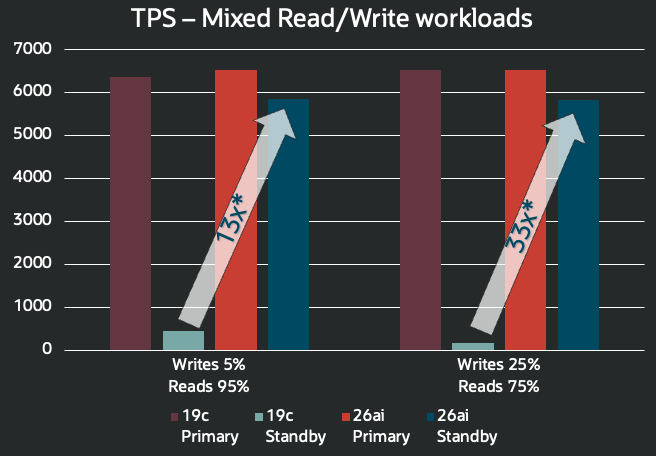
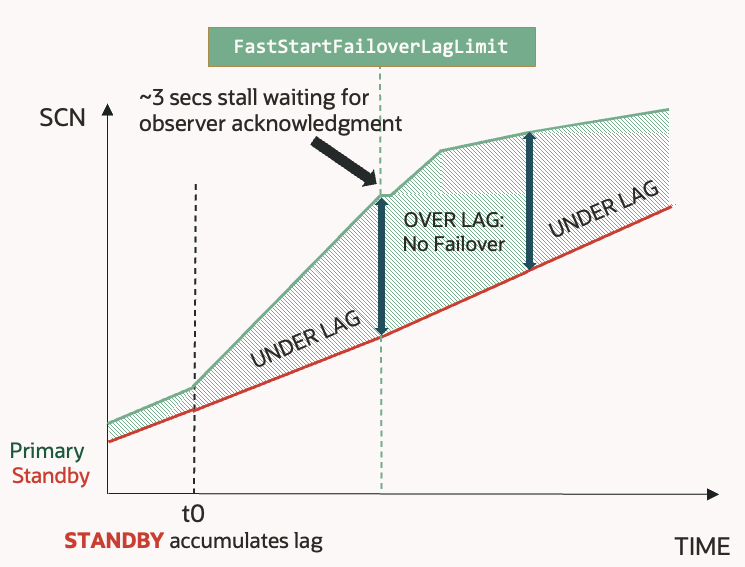
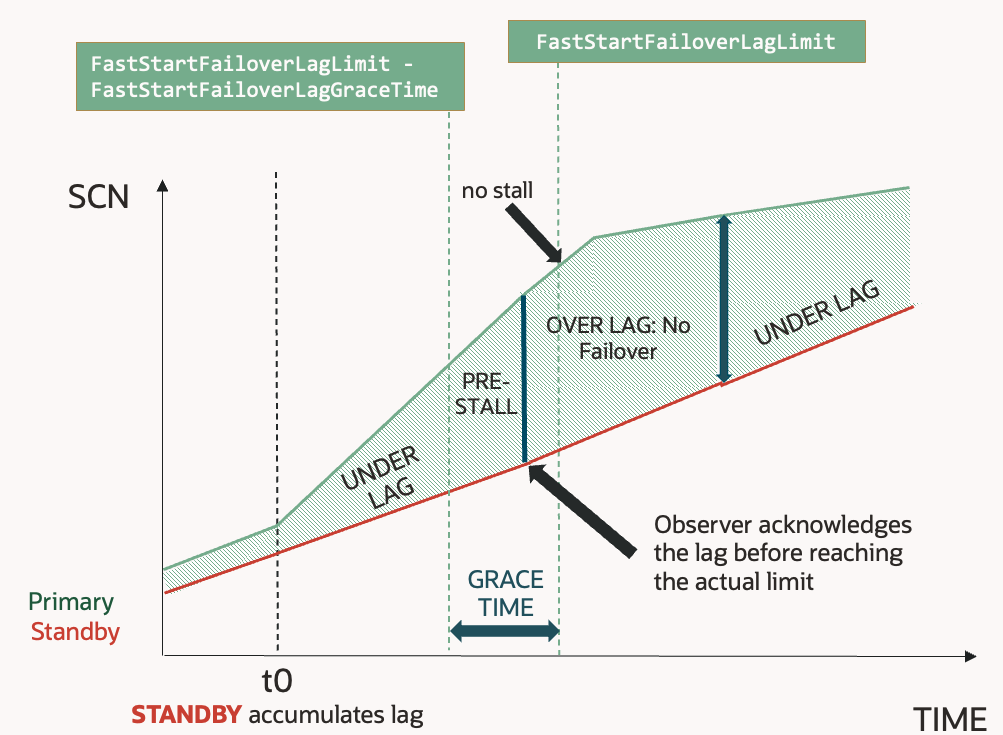
RMAN> restore standby controlfile from service adgvec_d7q_lhr;
restore standby controlfile from service adgvec_d7q_lhr;
Starting restore at 16-DEC-25
using target database control file instead of recovery catalog
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=331 device type=DISK
channel ORA_DISK_1: starting datafile backup set restore
channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr
channel ORA_DISK_1: restoring control file
channel ORA_DISK_1: restore complete, elapsed time: 00:00:01
output file name=/u02/app/oracle/oradata/adgvec_site0/control01.ctl
output file name=/u03/app/oracle/fast_recovery_area/ADGVEC_SITE0/control02.ctl
Finished restore at 16-DEC-25
RMAN> alter database mount;
released channel: ORA_DISK_1
Statement processed
RMAN> restore database from service adgvec_d7q_lhr;
restore database from service adgvec_d7q_lhr;
Starting restore at 16-DEC-25
Starting implicit crosscheck backup at 16-DEC-25
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=486 device type=DISK
Crosschecked 6 objects
Finished implicit crosscheck backup at 16-DEC-25
Starting implicit crosscheck copy at 16-DEC-25
using channel ORA_DISK_1
Finished implicit crosscheck copy at 16-DEC-25
searching for all files in the recovery area
cataloging files...
cataloging done
List of Cataloged Files
=======================
File Name: /u03/app/oracle/fast_recovery_area/ADGVEC_SITE0/autobackup/2025_07_25/o1_mf_s_1207415482_n87gotv5_.bkp
File Name: /u03/app/oracle/fast_recovery_area/ADGVEC_SITE0/archivelog/2025_10_31/o1_mf_1_172_njbddl2f_.arc
...
using channel ORA_DISK_1
channel ORA_DISK_1: starting datafile backup set restore
channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr
channel ORA_DISK_1: specifying datafile(s) to restore from backup set
channel ORA_DISK_1: restoring datafile 00001 to /u02/app/oracle/oradata/adgvec_d7q_lhr/ADGVEC_D7Q_LHR/datafile/o1_mf_system_n87ggxdv_.dbf
channel ORA_DISK_1: restore complete, elapsed time: 00:00:07
channel ORA_DISK_1: starting datafile backup set restore
channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr
channel ORA_DISK_1: specifying datafile(s) to restore from backup set
channel ORA_DISK_1: restoring datafile 00002 to /u02/app/oracle/oradata/adgvec_d7q_lhr/ADGVEC_D7Q_LHR/32F00060B1F21FF6E0633A875E64E7C7/datafile/o1_mf_system_n87ggxhw_.dbf
channel ORA_DISK_1: restore complete, elapsed time: 00:00:03
channel ORA_DISK_1: starting datafile backup set restore
channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr
channel ORA_DISK_1: specifying datafile(s) to restore from backup set
channel ORA_DISK_1: restoring datafile 00003 to /u02/app/oracle/oradata/adgvec_d7q_lhr/ADGVEC_D7Q_LHR/datafile/o1_mf_sysaux_n87ggxn0_.dbf
channel ORA_DISK_1: restore complete, elapsed time: 00:00:55
channel ORA_DISK_1: starting datafile backup set restore
channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr
channel ORA_DISK_1: specifying datafile(s) to restore from backup set
channel ORA_DISK_1: restoring datafile 00004 to /u02/app/oracle/oradata/adgvec_d7q_lhr/ADGVEC_D7Q_LHR/32F00060B1F21FF6E0633A875E64E7C7/datafile/o1_mf_sysaux_n87ggxqm_.dbf
channel ORA_DISK_1: restore complete, elapsed time: 00:00:03
channel ORA_DISK_1: starting datafile backup set restore
channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr
channel ORA_DISK_1: specifying datafile(s) to restore from backup set
channel ORA_DISK_1: restoring datafile 00007 to /u02/app/oracle/oradata/adgvec_d7q_lhr/ADGVEC_D7Q_LHR/datafile/o1_mf_users_n87gh76c_.dbf
channel ORA_DISK_1: restore complete, elapsed time: 00:00:01
channel ORA_DISK_1: starting datafile backup set restore
channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr
channel ORA_DISK_1: specifying datafile(s) to restore from backup set
channel ORA_DISK_1: restoring datafile 00009 to /u02/app/oracle/oradata/adgvec_d7q_lhr/ADGVEC_D7Q_LHR/32F00060B1F21FF6E0633A875E64E7C7/datafile/o1_mf_undotbs1_n87gh97l_.dbf
channel ORA_DISK_1: restore complete, elapsed time: 00:00:01
channel ORA_DISK_1: starting datafile backup set restore
channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr
channel ORA_DISK_1: specifying datafile(s) to restore from backup set
channel ORA_DISK_1: restoring datafile 00011 to /u02/app/oracle/oradata/adgvec_d7q_lhr/ADGVEC_D7Q_LHR/datafile/o1_mf_undotbs1_n87ghb6x_.dbf
channel ORA_DISK_1: restore complete, elapsed time: 00:00:01
channel ORA_DISK_1: starting datafile backup set restore
channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr
channel ORA_DISK_1: specifying datafile(s) to restore from backup set
channel ORA_DISK_1: restoring datafile 00012 to /u02/app/oracle/oradata/adgvec_d7q_lhr/ADGVEC_D7Q_LHR/330D3A56F99F26B6E0635C08F40AF437/datafile/o1_mf_system_n87ghdl5_.dbf
channel ORA_DISK_1: restore complete, elapsed time: 00:00:03
channel ORA_DISK_1: starting datafile backup set restore
channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr
channel ORA_DISK_1: specifying datafile(s) to restore from backup set
channel ORA_DISK_1: restoring datafile 00013 to /u02/app/oracle/oradata/adgvec_d7q_lhr/ADGVEC_D7Q_LHR/330D3A56F99F26B6E0635C08F40AF437/datafile/o1_mf_sysaux_n87ghdny_.dbf
channel ORA_DISK_1: restore complete, elapsed time: 00:00:45
channel ORA_DISK_1: starting datafile backup set restore
channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr
channel ORA_DISK_1: specifying datafile(s) to restore from backup set
channel ORA_DISK_1: restoring datafile 00014 to /u02/app/oracle/oradata/adgvec_d7q_lhr/ADGVEC_D7Q_LHR/330D3A56F99F26B6E0635C08F40AF437/datafile/o1_mf_undotbs1_n87ghdrp_.dbf
channel ORA_DISK_1: restore complete, elapsed time: 00:00:01
channel ORA_DISK_1: starting datafile backup set restore
channel ORA_DISK_1: using network backup set from service adgvec_d7q_lhr
channel ORA_DISK_1: specifying datafile(s) to restore from backup set
channel ORA_DISK_1: restoring datafile 00015 to /u02/app/oracle/oradata/adgvec_d7q_lhr/ADGVEC_D7Q_LHR/330D3A56F99F26B6E0635C08F40AF437/datafile/o1_mf_users_n87ghhw8_.dbf
channel ORA_DISK_1: restore complete, elapsed time: 00:00:15
Finished restore at 16-DEC-25
RMAN>